Note
Go to the end to download the full example code.
ROUGE¶
The ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metric used to evaluate the quality of generated text compared to a reference text. It does so by computing the overlap between two texts, for which a subsequent precision and recall value can be computed. The ROUGE score is often used in the context of generative tasks such as text summarization and machine translation.
A major difference with Perplexity comes from the fact that ROUGE evaluates actual text, whereas Perplexity evaluates logits.
Here’s a hypothetical Python example demonstrating the usage of unigram ROUGE F-score to evaluate a generative language model:
12 from transformers import AutoTokenizer, pipeline
13
14 from torchmetrics.text import ROUGEScore
15
16 pipe = pipeline("text-generation", model="openai-community/gpt2")
17 tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
Define the prompt and target texts
22 prompt = "The quick brown fox"
23 target_text = "The quick brown fox jumps over the lazy dog."
Generate a sample text using the GPT-2 model
28 sample_text = pipe(prompt, max_length=20, do_sample=True, temperature=0.1, pad_token_id=tokenizer.eos_token_id)[0][
29 "generated_text"
30 ]
31 print(sample_text)
The quick brown foxes are a great way to get a little bit of a kick out of your dog.
The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a kick out of your dog. The quick brown foxes are a great way to get a little bit of a
Calculate the ROUGE of the generated text
36 rouge = ROUGEScore()
37 rouge(preds=[sample_text], target=[target_text])
{'rouge1_fmeasure': tensor(0.0410), 'rouge1_precision': tensor(0.0213), 'rouge1_recall': tensor(0.5556), 'rouge2_fmeasure': tensor(0.0165), 'rouge2_precision': tensor(0.0085), 'rouge2_recall': tensor(0.2500), 'rougeL_fmeasure': tensor(0.0410), 'rougeL_precision': tensor(0.0213), 'rougeL_recall': tensor(0.5556), 'rougeLsum_fmeasure': tensor(0.0328), 'rougeLsum_precision': tensor(0.0170), 'rougeLsum_recall': tensor(0.4444)}
By default, the ROUGE score is calculated using a whitespace tokenizer. You can also calculate the ROUGE for the tokens directly:
41 token_rouge = ROUGEScore(tokenizer=lambda text: tokenizer.tokenize(text))
42 token_rouge(preds=[sample_text], target=[target_text])
{'rouge1_fmeasure': tensor(0.0467), 'rouge1_precision': tensor(0.0243), 'rouge1_recall': tensor(0.6000), 'rouge2_fmeasure': tensor(0.0235), 'rouge2_precision': tensor(0.0122), 'rouge2_recall': tensor(0.3333), 'rougeL_fmeasure': tensor(0.0467), 'rougeL_precision': tensor(0.0243), 'rougeL_recall': tensor(0.6000), 'rougeLsum_fmeasure': tensor(0.0448), 'rougeLsum_precision': tensor(0.0233), 'rougeLsum_recall': tensor(0.6000)}
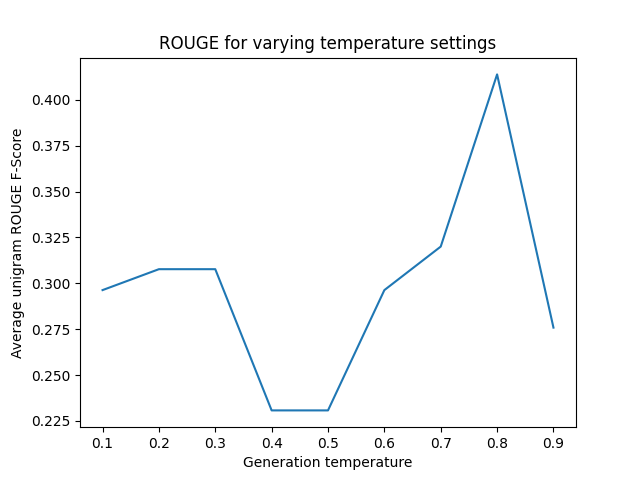
Since ROUGE is a text-based metric, it can be used to benchmark decoding strategies. For example, you can compare temperature settings:
47 import matplotlib.pyplot as plt # noqa: E402
48
49 temperatures = [x * 0.1 for x in range(1, 10)] # Generate temperature values from 0 to 1 with a step of 0.1
50 n_samples = 100 # Note that a real benchmark typically requires more data
51
52 average_scores = []
53
54 for temperature in temperatures:
55 sample_text = pipe(
56 prompt, max_length=20, do_sample=True, temperature=temperature, pad_token_id=tokenizer.eos_token_id
57 )[0]["generated_text"]
58 scores = [rouge(preds=[sample_text], target=[target_text])["rouge1_fmeasure"] for _ in range(n_samples)]
59 average_scores.append(sum(scores) / n_samples)
60
61 # Plot the average ROUGE score for each temperature
62 plt.plot(temperatures, average_scores)
63 plt.xlabel("Generation temperature")
64 plt.ylabel("Average unigram ROUGE F-Score")
65 plt.title("ROUGE for varying temperature settings")
66 plt.show()
Total running time of the script: (1 minutes 56.568 seconds)
