Lightning AI Studios: Never set up a local environment again →
Author:
Sebastian Raschka
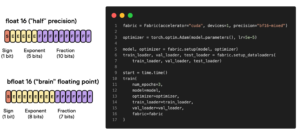
Doubling Neural Network Finetuning Efficiency with 16-bit Precision Techniques
Read More
Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments
Read More
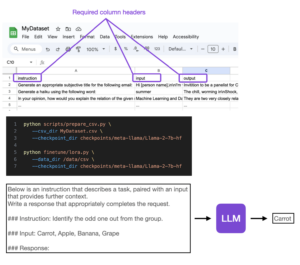
Optimizing LLMs from a Dataset Perspective
Read More
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Read More
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Read More
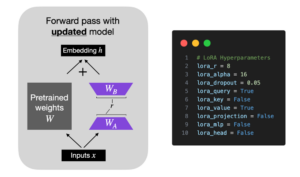
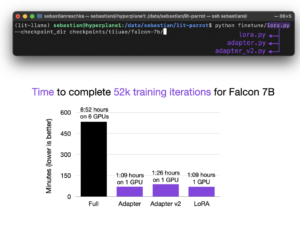
Finetuning Falcon LLMs More Efficiently With LoRA and Adapters
Read More
Accelerating Large Language Models with Mixed-Precision Techniques
Read More
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
Read More
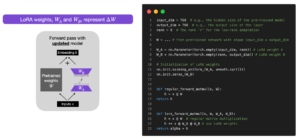
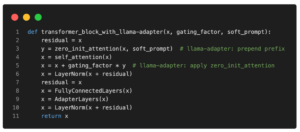
Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters
Read More
Finetuning LLMs on a Single GPU Using Gradient Accumulation
Read More
1
2
»