Table of Contents
- Supervised Instruction Finetuning
- The Finetuning Pipeline and Dataset Origins
- LLM-generated datasets
- High-quality Datasets: Less May Be More
- Finetuning LLMs on LIMA
- Available Models and Datasets in Lit-GPT
- Preparing New and Custom Datasets
- Additional Datasets to Consider
- Research Directions to Explore
- Conclusion
Takeaways
Discover new research directions to improve Large Language Models (LLMs) and learn how to enhance the performance of instruction-finetuned LLMs by concentrating on higher-quality data and exploring diverse dataset sources.This article focuses on improving the modeling performance of LLMs by finetuning them using carefully curated datasets. Specifically, this article highlights strategies that involve modifying, utilizing, or manipulating the datasets for instruction-based finetuning rather than altering the model architecture or training algorithms (the latter will be topics of a future article). This article will also explain how you can prepare your own datasets to finetune open-source LLMs.
Note that the NeurIPS LLM Efficiency Challenge is currently underway, aiming to train a Large Language Model on a single GPU within a 24-hour period, which is super interesting for practitioners and researchers interested in LLM efficiency. The techniques discussed in this article have direct relevance to this competition, and we will delve into how these dataset-centric strategies could potentially be applied within the challenge setting. Additionally, the article will offer suggestions for new experiments you might consider trying.
Supervised Instruction Finetuning
What is instruction-finetuning, and why should we care?
Instruction finetuning is a method used to improve the performance of language models like ChatGPT and Llama-2-chat by having the model generate outputs for a range of example inputs paired with desired outputs. It allows for more controlled and desired behavior of the model in specific applications or tasks. Also, it can enhance the reliability, specificity, and safety of AI systems in real-world use cases.
Annotated figure from InstructGPT paper
Instruction finetuning uses a dataset consisting of instruction-response pairs to improve an LLM’s instruction-following capabilities. Such a dataset for instruction finetuning typically consists of three components:
- Instruction text
- Input text (optional)
- Output text
The example below lists two training examples, one without and one with an optional input text:

Instruction finetuning format
LLMs are then finetuned on these instruction datasets via next-token prediction (similar to pretraining). The difference from pretraining is that the model sees the whole instruction and input text as a context before it’s tasked to carry out the next-token prediction to generate the output text in an autoregressive fashion, illustrated below.
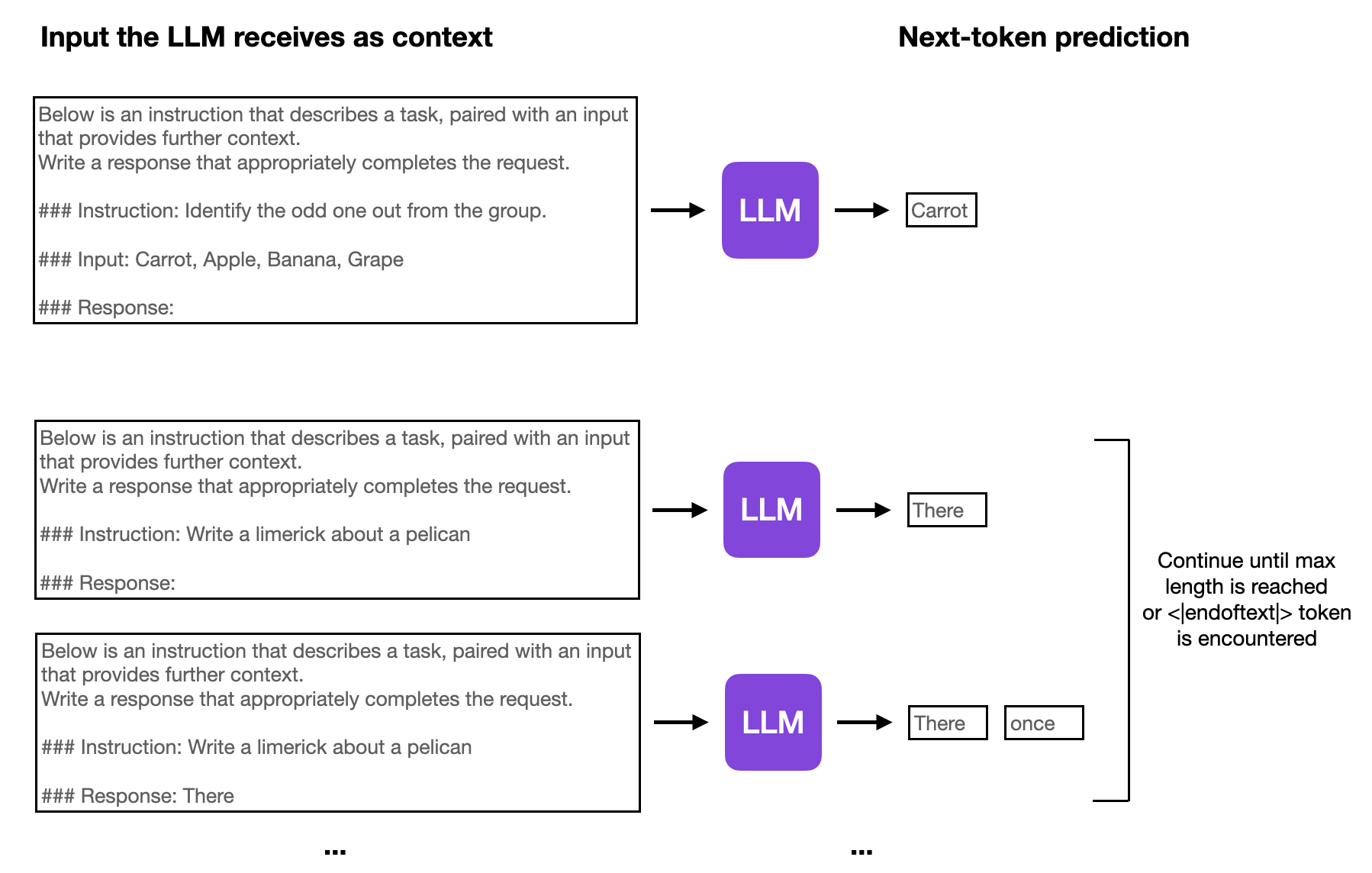
Finetuning LLMs on instruction datasets
This above-mentioned process for finetuning an LLM to generate the desired output in an iterative, token-wise fashion is also referred to as supervised finetuning.
In practice, there is an additional optional finetuning stage following supervised finetuning, which uses additional preference data and ranking labels from human annotators who compare responses generated by LLMs. This process is also known as reinforcement learning with human feedback (RLHF), but it is out-of-scope for this article, which focuses on the instruction datasets themselves. (However, I have an optional article on RLHF here if you want to learn more.)
The Finetuning Pipeline and Dataset Origins
When finetuning LLMs, datasets for instruction finetuning can be sourced in multiple ways:
- Human-created: Expert annotators can provide explicit instructions and feedback, creating datasets for instruction finetuning. This is particularly useful for domain-specific tasks or for reducing particular biases or unwanted behaviors.
- LLM-generated: We can generate a vast amount of potential input-output pairs using an existing LLM (if the terms of service permit). These can then be refined or rated by humans for quality and then used to finetune a new LLM. This method is usually more efficient than the abovementioned human-created approach because an available LLM, such as GPT-4 (via the API interface), can generate a large number of potential examples in a short time.
The LLM finetuning pipeline using human-created or LLM-generated data is summarized in the recent and excellent Instruction Tuning for Large Language Models survey:
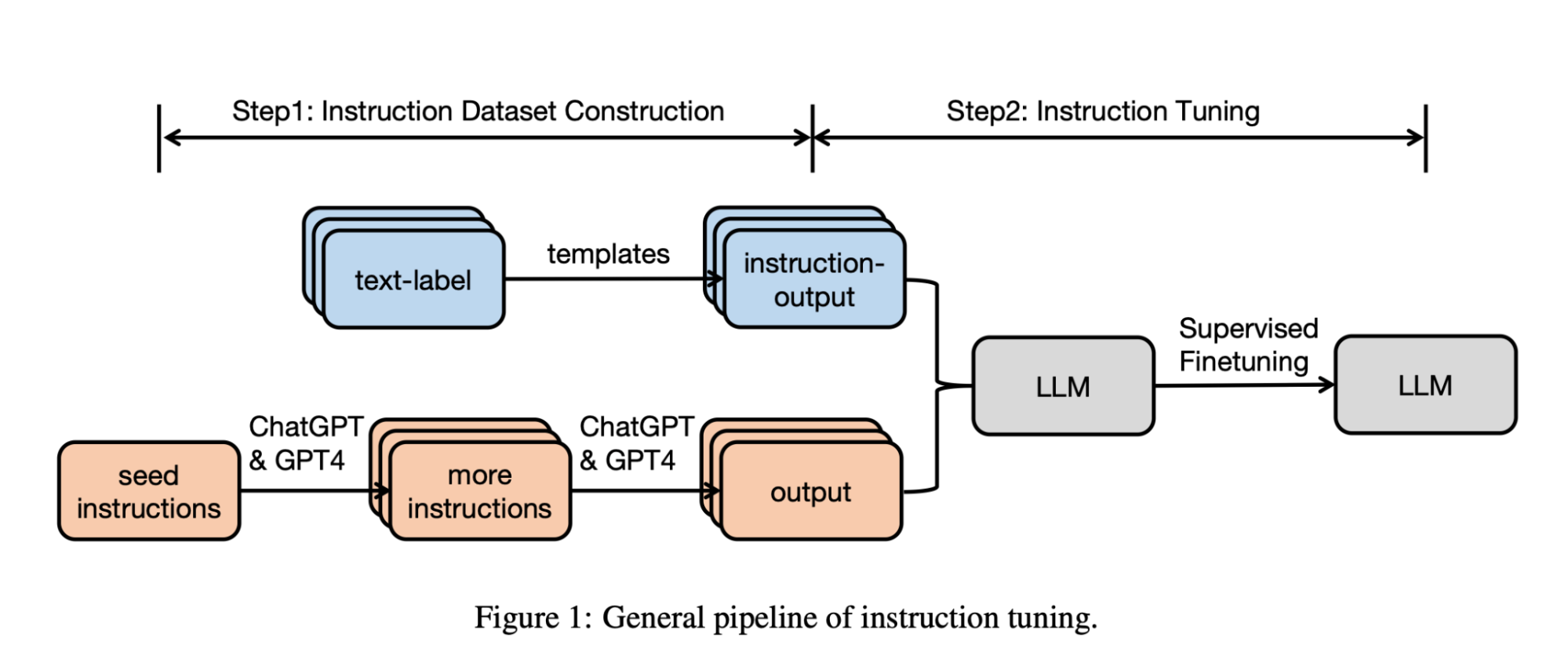
Additionally, we can also potentially combine both human-created and LLM-generated instruction data to get the best of both worlds.
The upcoming sections will discuss LLM-generated and human-created datasets for instruction finetuning in more detail, including the recent research highlights.
LLM-generated datasets
Dataset labeling has been a bottleneck in machine learning ever since. As a human annotator, simple labeling tasks like categorizing an image as “cat” or “dog” are already considered laborious when it has to be done at scale.
Tasks requiring long-form text annotations can be even more time-consuming and challenging. So, a lot of effort has been devoted towards generating datasets for instruction finetuning automatically using existing LLMs.
Self-Instruct
One of the most prominent and widely used methods for LLM-generated datasets is Self-Instruct.
So, how does it work? Briefly, it involves four stages:
- Seed task pool with a set of human-written instructions (175 in this case) and sample instructions;
- Use a pretrained LLM (like GPT-3) to determine the task category;
- Given the new instruction, let a pretrained LLM generate the response;
- Collect, prune, and filter the responses before adding them to the task pool.
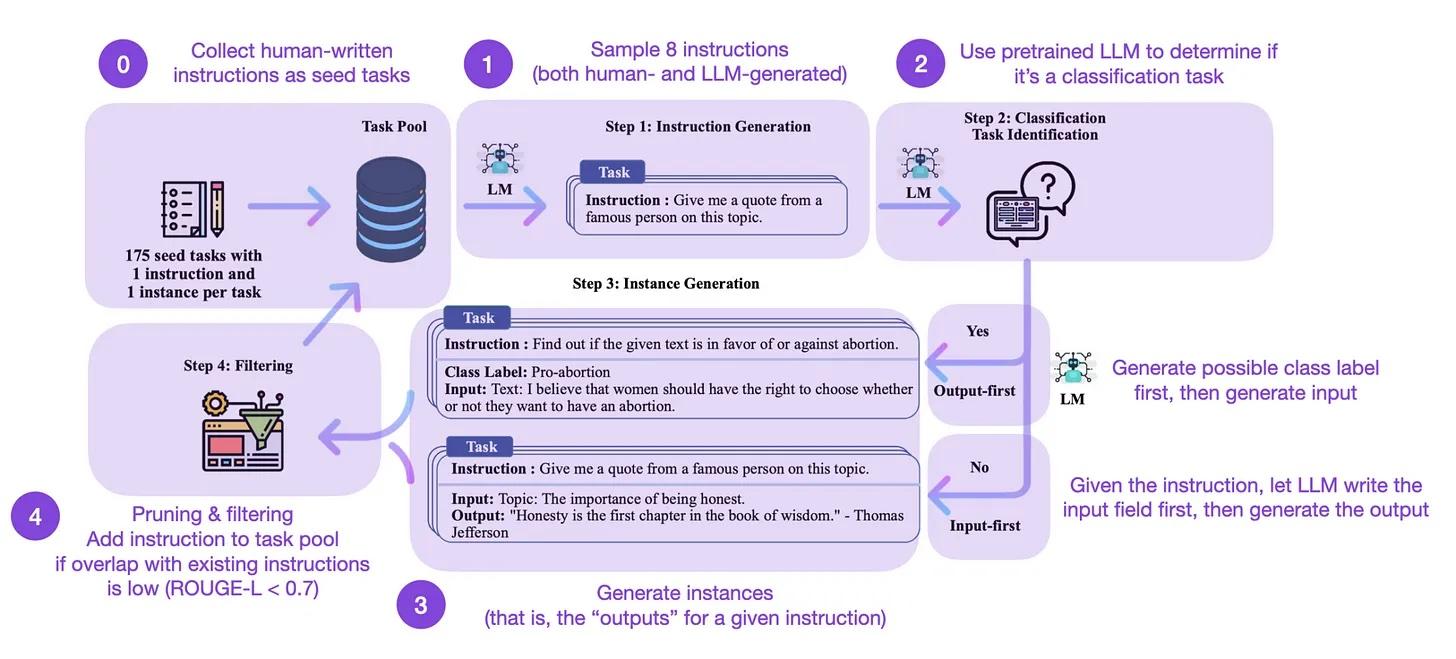
Annotated figure from Self-Instruct paper
An early popular application of Self-Instruct was the Alpaca dataset, which consists of 52k LLM-generated instruction-response pairs. Alpaca was used to create the first finetuning Llama v1 model earlier this year.
Backtranslation
Another interesting type of approach involves working backward from the responses and generating the corresponding instructions via LLMs.
In other words, rather than gathering datasets for instruction finetuning from human writers, it’s possible to employ an LLM to produce instruction-response pairs (also known as distillation).
In a paper titled Self-Alignment with Instruction Backtranslation, researchers refined LLMs via “instruction backtranslation” and found that this method surpasses those trained on distillation datasets like Alpaca.
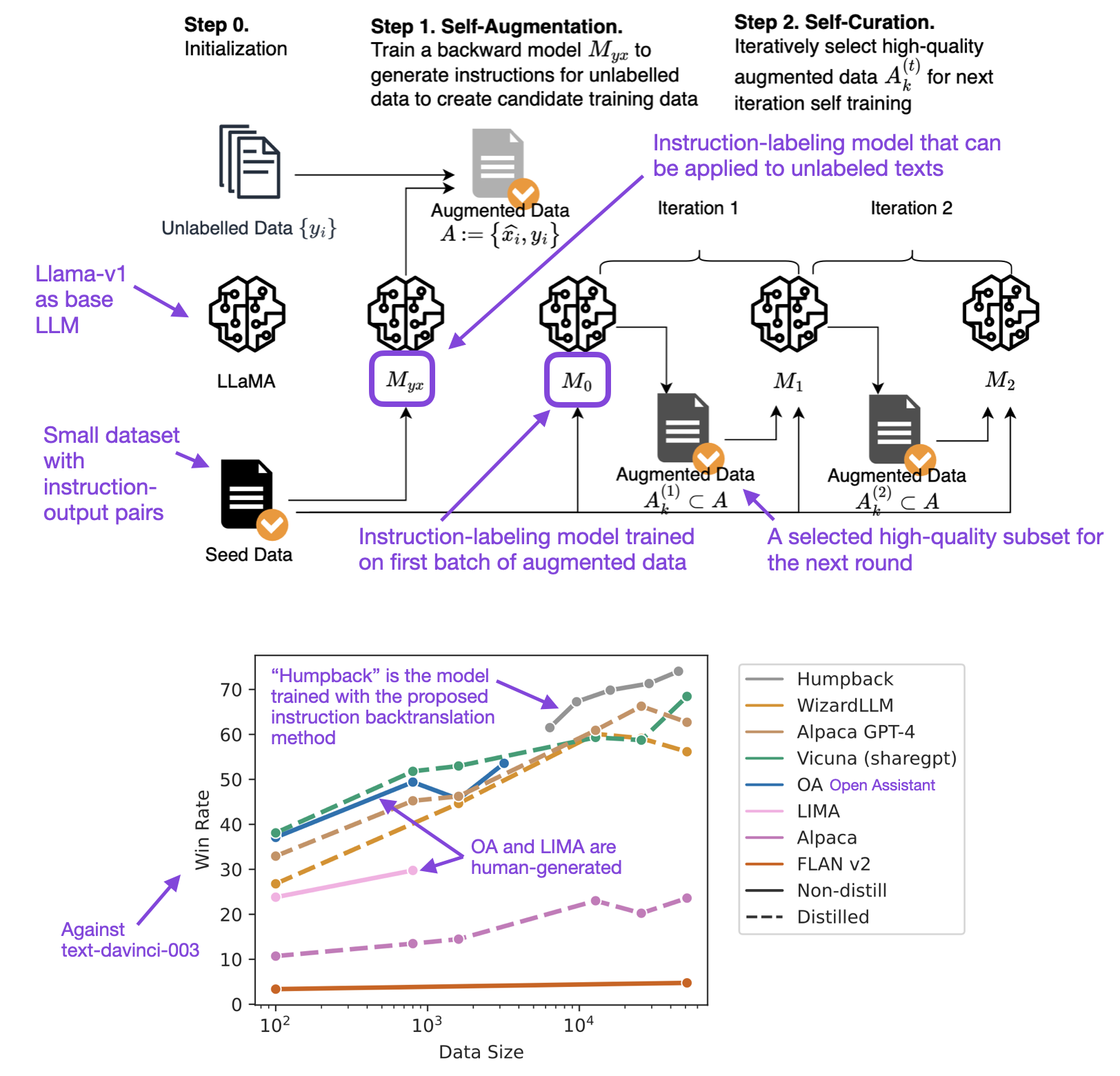
Annotated figures from Self-Alignment with Instruction Backtranslation paper
NeurIPS Efficiency Challenge Rules
Note that the NeurIPS LLM Efficiency Challenge, which is centered around training 1 LLM for 1 Day on 1 GPU, does not permit LLM-generated datasets.
So, in the next section, High-Quality Datasets, we will focus on human-generated instruction datasets that we can use as an alternative.
If you are interested in participating in the NeurIPS LLM Efficiency Challenge, I’ve written a quick starter tutorial here.
A Note About LLM-generated Datasets and Imitation Models
Before we jump into the discussion of human-generated datasets for instruction finetuning, I wanted to share a brief word of caution regarding LLM-generated datasets. Yes, generating datasets via LLMs may sound too good to be true, so it is important to evaluate LLMs finetuned on LLM-generated datasets extra carefully.
For instance, in a recent The False Promise of Imitating Proprietary LLMs paper, researchers observed that crowd workers gave high ratings to LLMs trained on LLM-generated data. However, these so-called “imitation models” primarily replicated the style of the upstream LLMs they were trained on rather than their factual accuracy.
High-quality Datasets: Less May Be More
In the previous section, we discussed datasets generated by LLMs. Now, let’s switch gears and examine a high-quality, human-generated dataset, which is also allowed in the NeurIPS LLM Efficiency Challenge.
LIMA
The LIMA: Less Is More for Alignment paper shows that quality trumps quantity when instruction finetuning datasets.
In this study, researchers carefully selected 1,000 instruction pairs to finetune the 65-billion-parameter Llama-v1 model, known as LIMA, using supervised finetuning.
Notably, other finetuned Llama models, such as Alpaca, were trained on a considerably larger dataset of 52,000 LLM-generated instruction pairs. In selected benchmarks, LIMA outperformed models that employed Reinforcement Learning with Human Feedback (RLHF) methods, including ChatGPT and GPT-3.5.
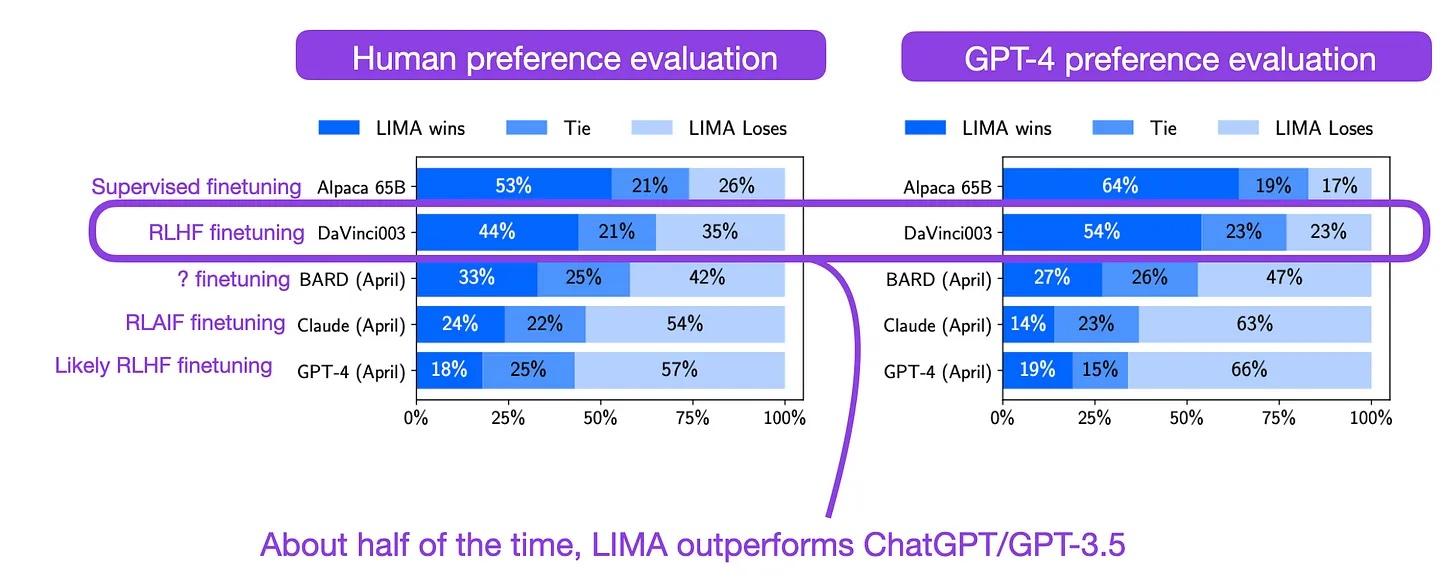
Annotated figure from the LIMA paper
The next section will show you how to get started with open-source LLMs and finetune these models on LIMA.
Finetuning LLMs on LIMA
This section explains how to finetune open-source LLMs on instruction datasets like LIMA using the Lit-GPT repository.
(Note that the NeurIPS LLM Efficiency Challenge organizers cleared LIMA for the competition. The NeurIPS LLM Efficiency Challenge organizers also selected Lit-GPT as the starter kit since the code is relatively easy to use and customize, which is an essential prerequisite for exploring new research directions.)
As of this writing, the currently supported models in Lit-GPT are the following:
| Model and usage | Reference |
| Meta AI Llama 2 | Touvron et al. 2023 |
| Stability AI FreeWilly2 | Stability AI 2023 |
| Stability AI StableCode | Stability AI 2023 |
| TII UAE Falcon | TII 2023 |
| OpenLM Research OpenLLaMA | Geng & Liu 2023 |
| LMSYS Vicuna | Li et al. 2023 |
| LMSYS LongChat | LongChat Team 2023 |
| Together RedPajama-INCITE | Together 2023 |
| EleutherAI Pythia | Biderman et al. 2023 |
| StabilityAI StableLM | Stability AI 2023 |
| Platypus | Lee, Hunter, and Ruiz 2023 |
| NousResearch Nous-Hermes | Org page |
| Meta AI Code Llama | Rozière et al. 2023 |
For this brief walkthrough, we will use the 7B parameter Llama 2 base model and finetune it on LIMA.
Assuming you have cloned the Lit-GPT repository, you can get started via the following three steps:
1) Download and prepare the model:
export HF_TOKEN=your_token python scripts/download.py \ --repo_id meta-llama/Llama-2-7b-hf
python scripts/convert_hf_checkpoint.py \ --checkpoint_dir meta-llama/Llama-2-7b-hf
2) Prepare the dataset:
python scripts/prepare_lima.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf
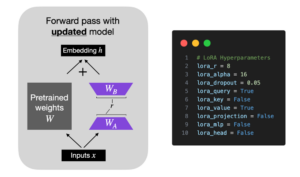
3) Finetune the model using low-rank adaptation (LoRA):
python finetune/lora.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \
--data_dir data/lima
Note that the –checkpoint_dir argument is required for preparing the dataset in step 2 because the dataset preparation is model-dependent. Different LLMs may use different tokenizers and special tokens, so it’s important to prepare the dataset accordingly.
I am skipping a detailed explanations of the LoRA finetuning procedure to keep this article focused on the dataset perspective. However, if you are interested in learning more, you can see my article Finetuning Falcon LLMs More Efficiently With LoRA and Adapters.
In addition, you may also find my NeurIPS 2023 LLM Efficiency Challenge Quickstart Guide article helpful, where I walk through the setup, finetuning, and model evaluation step by step.
Tip
According to the official competition rules, the maximum context length used for the evaluation is 2,048 tokens. Hence, I recommend preparing the dataset with a maximum length of 2,048 tokens:
python scripts/prepare_lima.py \
--checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf \
--max_seq_length 2048
Alternatively you can edit the finetune/lora.py file and change override_max_seq_length = None to override_max_seq_length = 2048 to reduce the GPU memory requirements.
In addition, I also suggest modifying the set max_iter setting and change it to max_iter = 1000 to finetune for ~1 pass over the LIMA dataset, which consists of 1k training examples.
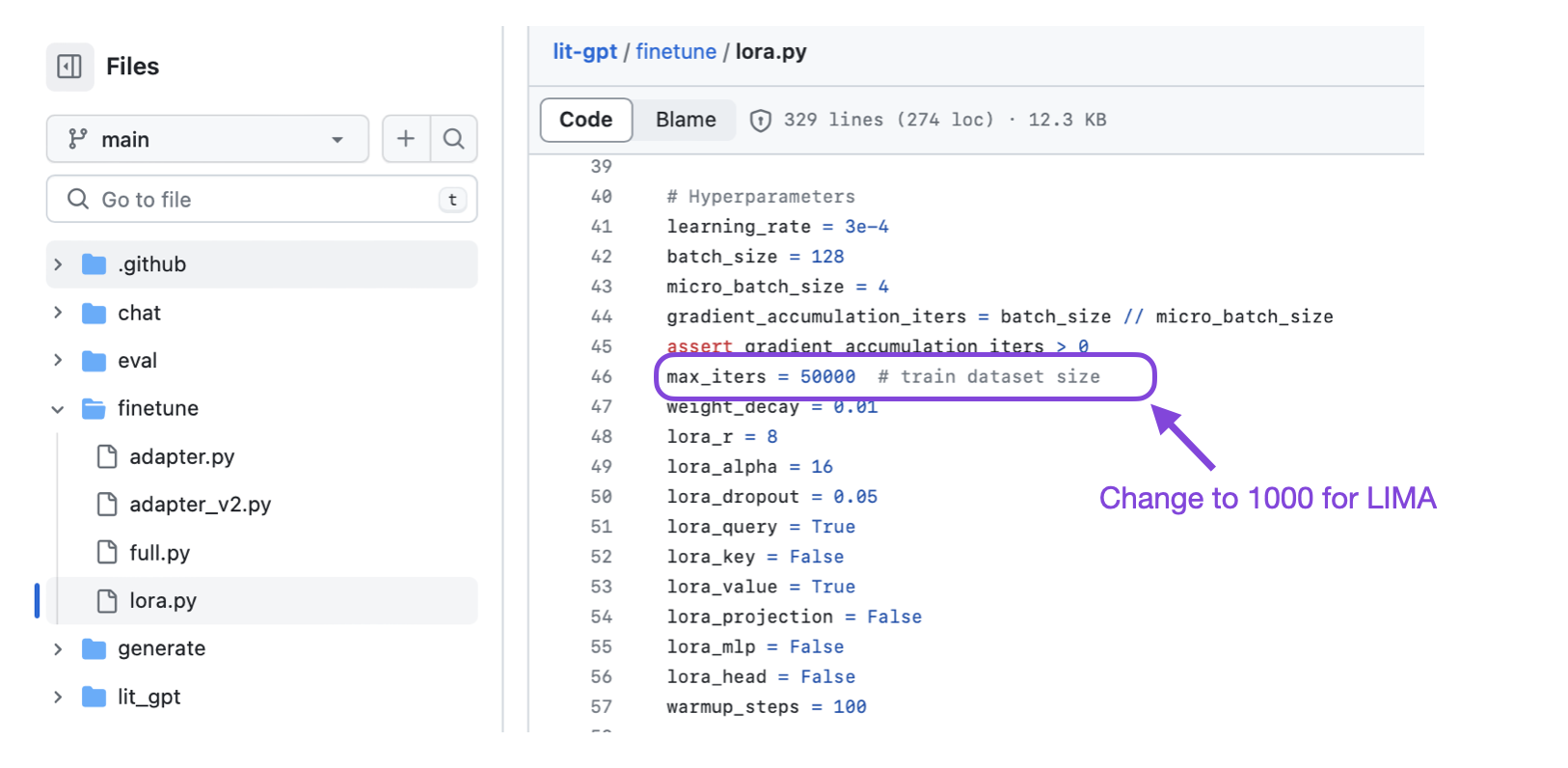
Selecting the number of finetuning iterations
For reference, finetuning a 7B parameter model on 52k instruction pairs, such as in Alpaca, takes about 1 hour on an A100 GPU when using LoRA with default settings. Note that LIMA is 50x smaller than Alpaca, so finetuning will only take a few minutes.
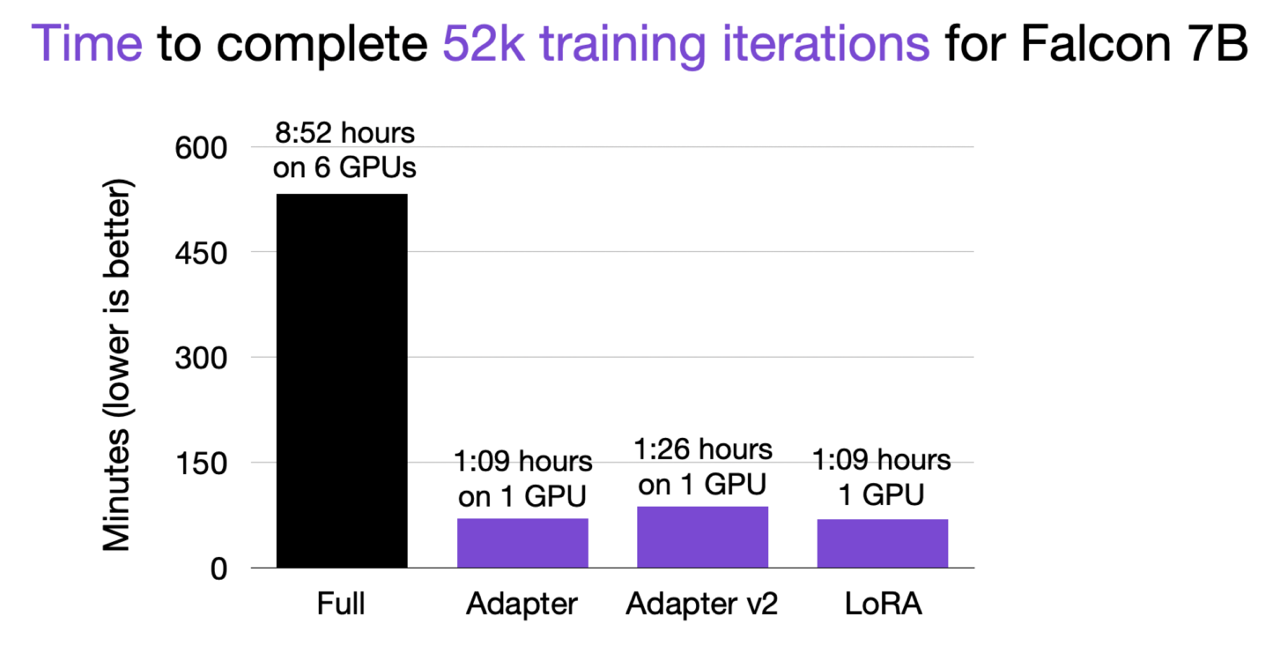
Finetuning a 7B model on 52k data points via Finetuning Falcon LLMs More Efficiently With LoRA and Adapters
Available Models and Datasets in Lit-GPT
As of this writing, there are currently multiple finetuning datasets supported in Lit-GPT:
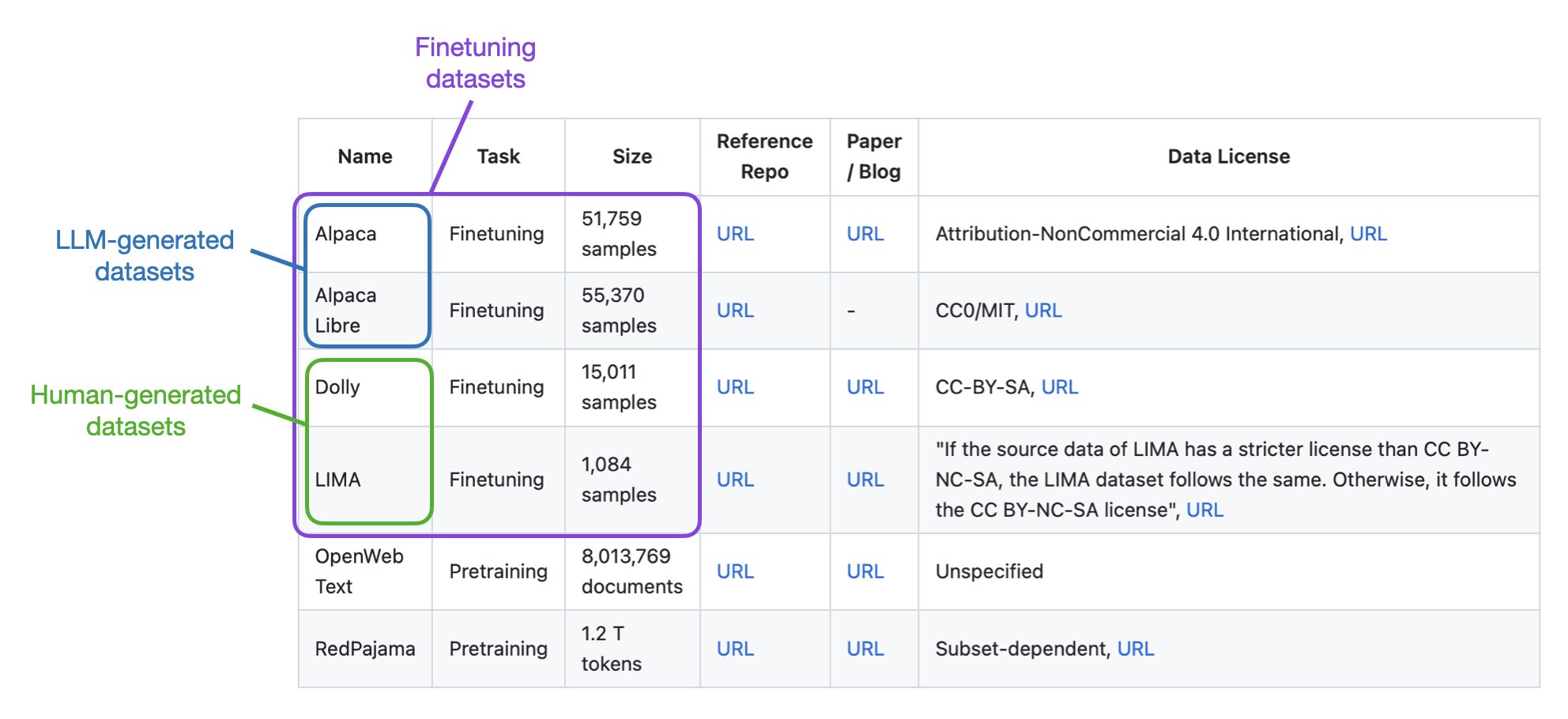
The Dolly and LIMA datasets are human-generated and should thus be fine for use in the NeurIPS LLM Efficiency Challenge.
Additionally, if you are interested in using different datasets to customize LLMs for your projects, the next section will briefly explain how this works.
Preparing New and Custom Datasets
In addition to the existing datasets mentioned above, you might be interested in adding new datasets or using your own datasets to finetune custom open-source LLMs.
There are two main ways to prepare a dataset for the LLMs in Lit-GPT:
- Using the
scripts/prepare_csv.pyscript to read an instruction dataset from a CSV file. - Creating a custom
scripts/prepare_dataset.pyscript similar to LIMA, which we used earlier.
(Thanks to the community contribution via @Anindyadeep that helped enable CSV file support!)
The easiest way to prepare a new dataset is to read it from a CSV file using the scripts/prepare_csv.py script in Lit-GPT. All you need is a CSV file that has the three column headers as shown below:
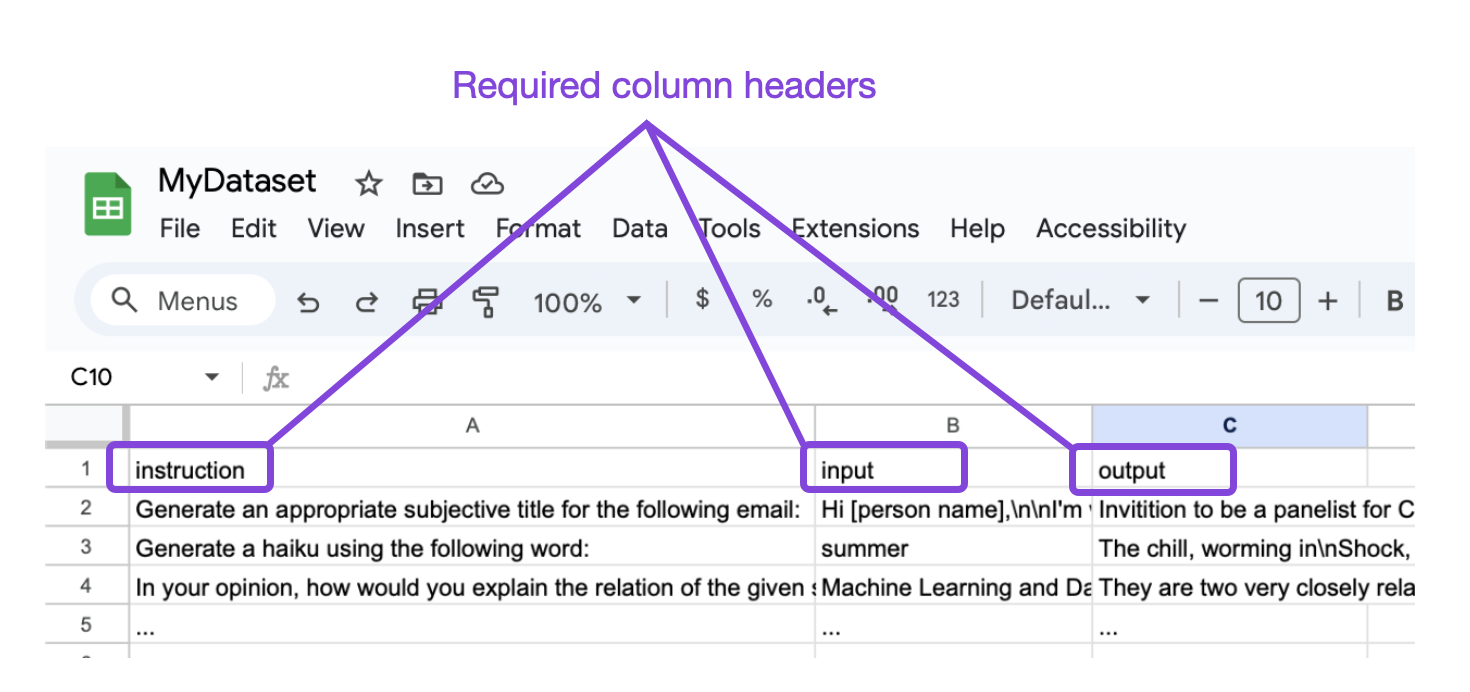
Requires column headers for the prepare_csv.py script
Assuming you exported this dataset as MyDataset.csv, you can then prepare and finetune the model as follows:
1) Prepare the dataset:
python scripts/prepare_csv.py \ --csv_dir MyDataset.csv \ --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf
2) Finetune the model using low-rank adaptation (LoRA):
python finetune/lora.py \ --data_dir /data/csv \ --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-hf
There are additional options for determining the random seed or train/split available that you can access via
python scripts/prepare_csv.py --helpIf you are interested in the second option, creating a prepare_dataset.py script similar to LIMA, I added an explanation to the Lit-GPT documentation here.
Additional Datasets to Consider
The previous section covered how to prepare custom datasets for open-source LLMs in Lit-GPT. If you don’t have your own dataset you want to experiment with but want to experiment with existing datasets (for example, the NeurIPS LLM Efficiency Challenge is restricted to publicly available datasets), here are a few pointers for datasets to explore.
With the NeurIPS LLM Efficiency Challenge in mind, the list focuses on human-generated English datasets, not LLM-generated datasets.
Open Assistant (multi-lingual) is a collection of assistant-like conversations created and annotated by humans. It contains 161,443 messages in 35 languages, enriched with 461,292 quality evaluations, resulting in more than 10,000 comprehensively annotated conversation trees. This dataset results from a global crowdsourcing initiative that engaged over 13,500 volunteers.
Natural Instructions is an English instruction dataset handcrafted with 193K entries, spanning 61 unique NLP tasks.
P3 (Public Pool of Prompts) is an instruction finetuning dataset constructed using 170 English NLP datasets and 2,052 English prompts. Prompts, sometimes named task templates, map a data instance in a conventional NLP task (e.g., question answering, text classification) to a natural language input-output pair.
Flan 2021 is an English instruction dataset compilation created by converting 62 popular NLP benchmarks (including SNLI, AG News, and others) into pairs of language inputs and outputs.
Research Directions to Explore
Now that we have covered the why and how related to instruction-finetuning, what interesting research directions can we explore to boost the performance of open-source LLMS?
Merging Datasets
Besides the P3 and Flan 2021 datasets mentioned above, I have not seen attempts to create larger datasets by combining datasets from multiple sources. For instance, it could make sense to experiment with combinations of LIMA and Dolly, and so forth.
Dataset Ordering
Following up on the dataset merging idea mentioned above, it could be interesting to explore the role of visiting different data points in different orders (for example, sorted or shuffled by the type of instruction). Besides the pretraining experiments done in the Pythia paper, I have not seen any studies on dataset ordering in the context of instruction finetuning.
Multiple-Epoch Training
Due to the large dataset size requirements, LLMs are usually pretrained for less than one epoch, which means that they don’t revisit data points multiple times. While computational costs are one reason for this, another is that LLMs can be prone to overfitting. Nonetheless, with many overfitting-reduction techniques at our disposal, studying multi-epoch training in the context of LLMs would be interesting.
For instance, it’s possible to train LLMs on a small dataset like LIMA in a few minutes. Would it make sense to iterate over the dataset multiple times?
Automatic Quality-filtering
Does it make sense to adopt dataset filtering as a default?
Related to the LIMA study discussed earlier, the AlpaGasus: Training A Better Alpaca with Fewer Data paper also emphasizes that a larger dataset isn’t necessarily advantageous for finetuning LLMs. In the AlpaGasus study, the researchers employed ChatGPT to pinpoint low-quality instruction-response pairs in the original 52,000-instance Alpaca dataset. They discovered that reducing this to just 9,000 high-quality pairs actually enhanced performance when training Llama-v1 LLMs with 7 billion and 13 billion parameters.
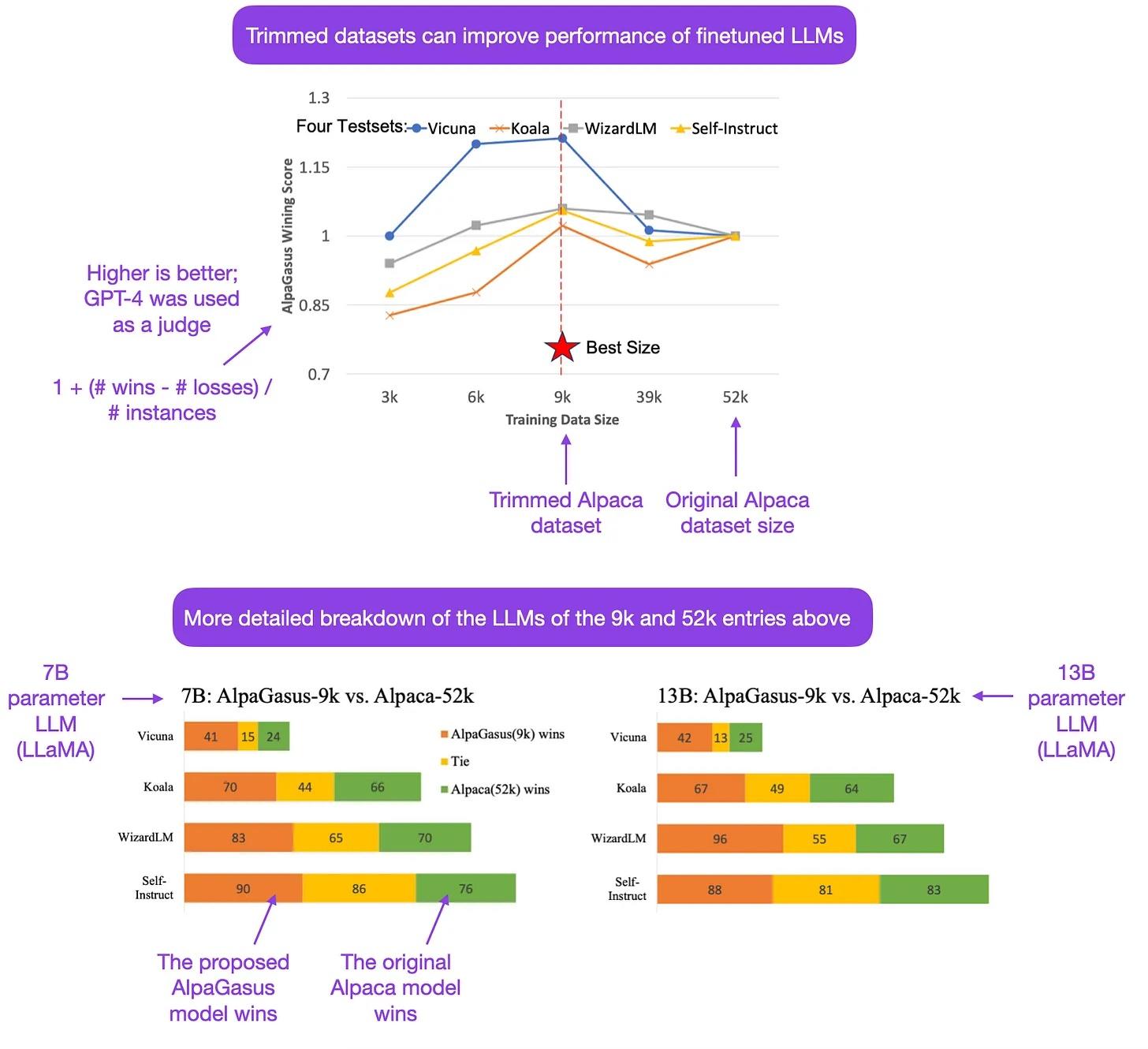
Annotated figure from the AlpaGasus paper
However, as mentioned earlier, the NeurIPS LLM Efficiency Challenge does not permit LLM-generated datasets. So, this Alpaca-based Alpagasus dataset would not be useful for this competition.
A viable alternative to AlpaGasus might be to use an LLM to filter human-generated (instead of LLM-generated) datasets. However, I’m uncertain if using LLM-based dataset filtering is allowed, so it would be important to confirm with the organizers on their Discord channel before using such datasets in the competition.
The upcoming sections will explain how to use datasets such as LIMA for training the latest open-source LLMs. Additionally, I will also highlight interesting research directions to try in the NeurIPS LLM Efficiency Challenge.
Conclusion
This article covered instruction finetuning and explained the advantages of LLM-generated and human-generated datasets. We also went over a quick tutorial explaining how to finetune open-source LLMs with different datasets and how to use our own datasets to create custom LLMs. Compared to proprietary APIs and services, such custom LLMs can help leverage specific datasets at your company, improve LLMs on certain use cases, and give you full privacy control.
If you have any questions, please don’t hesitate to reach out:
- If you have any suggestions, feedback, or problems with Lit-GPT, please consider filing an Issue on GitHub if you think it is a bug.
- Furthermore, Lit-GPT pull requests with improvements and implementations of new techniques would be very welcome!
If you are participating in the NeurIPS LLM Efficiency Challenge, I hope you find this competition as useful and exciting as I do.
- I suggest starting with the Quick Starter Guide I compiled here.
- For questions about whether a particular dataset is allowed in the competition, I recommend double-checking with the organizers via their Discord channel.
- For Lit-GPT-related questions about the challenge, my colleagues at Lightning AI also maintain a Discord channel here.
Happy learning, coding, and experimenting!
Table of Contents
- Supervised Instruction Finetuning
- The Finetuning Pipeline and Dataset Origins
- LLM-generated datasets
- High-quality Datasets: Less May Be More
- Finetuning LLMs on LIMA
- Available Models and Datasets in Lit-GPT
- Preparing New and Custom Datasets
- Additional Datasets to Consider
- Research Directions to Explore
- Conclusion