Key takeaway
Using parameter-efficient finetuning methods outlined in this article, it’s possible to finetune an open-source LLM like Falcon in 1 hour on a single GPU instead of a day on 6 GPUs.
Finetuning allows us to adapt pretrained LLMs in a cost-efficient manner. But which method should we use? This article compares different parameter-efficient finetuning methods for the latest top-performing open-source LLM, Falcon.
Pretraining and Finetuning LLMs
Before we dive into the LLM finetuning details, let’s briefly recap how we train LLMs in general.
LLMs are trained in two stages. The first stage is an expensive pretraining step to train the models on a large, unlabeled dataset containing trillions of words. The resulting models are often called foundation models since they have general capabilities and can be adapted for various downstream tasks. A classic example of a pretrained model is GPT-3.
The second stage is finetuning such a foundation model. This typically involves training the pretrained model to follow instructions or perform another specific target task (for example, sentiment classification). ChatGPT (which started as a finetuned version of the GPT-3 foundation model) is a typical example of a model that was finetuned to follow instructions. Using parameter-efficient finetuning methods outlined in this article, it’s possible to finetune an LLM in 1 hour on a single GPU instead of a day on 6 GPUs.
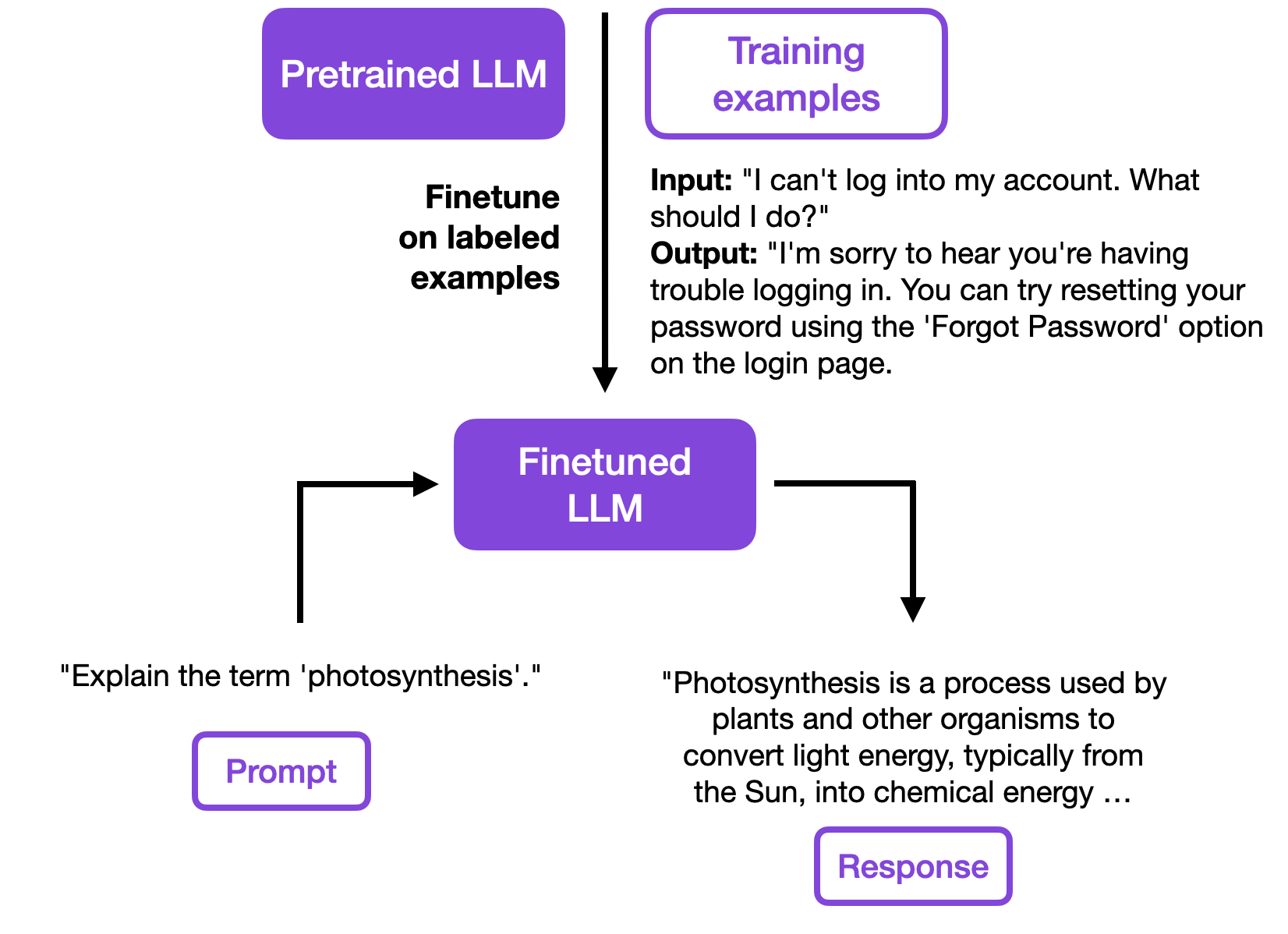
Finetuning a pretrained LLM to follow instructions
Finetuning also allows the model to better adapt to specific domains or types of text that were not well represented in its original training data. For example, we might finetune a model on medical literature if we want it to understand and generate medical texts.
Besides building custom chatbots, finetuning allows customization of these models to specific business needs to offer superior performance in targeted applications. Furthermore, it can also provide a data privacy advantage when data cannot be uploaded or shared with cloud APIs.
This article aims to illustrate how to finetune a top-performing LLM efficiently and cost-effectively in a few hours on a single GPU.
Finetuning Versus ChatGPT
In the era of ChatGPT, why do we care about finetuning models in the first place?
The problem with closed models such as OpenAI’s ChatGPT and Google’s Bard is that they cannot be readily customized, which makes them less attractive for many use cases. However, fortunately, we have seen a large number of open-source LLMs emerging in recent months. (While ChatGPT and Bard have strong in-context learning capabilities, finetuned models outperform generalist models on specific tasks; recent research examples highlighting this include and .)
Open Source LLMs and the Falcon Architecture
Finetuning open-source LLMs has several benefits, such as better customization capabilities and task performance. Furthermore, open-source LLMs are an excellent testbed for researchers to develop novel techniques. But if we adopt an open-source model today, which one should it be?
As of this writing, the Falcon model, developed by , is currently the top-performing open-source LLM. And in this article, we will learn how to finetune it efficiently, for example, on your custom dataset.
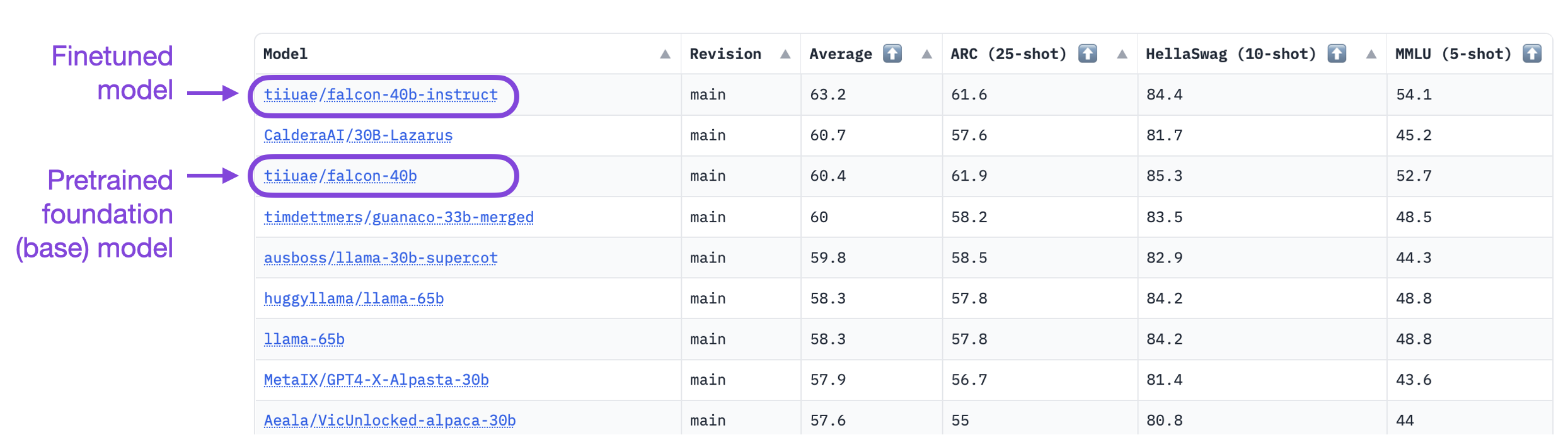
Excerpt from the OpenLLM leaderboard
Falcon LLMs come in different sizes: as of this writing, there’s a 7 billion parameter (Falcon 7B) variant and a 40 billion parameter variant (Falcon 40B). Furthermore, each size comes as a foundation (Falcon 7B and Falcon 40B) and instruction-tuned model (Falcon 7B-instruct and Falcon 40B-instruct). The instruction-tuned models are already finetuned for general-purpose tasks (similar to ChatGPT), but they can be further finetuned on domain-specific data if needed. (PS: A .)
Note that the Falcon model is fully open-source and was released under a permissive license, which permits unrestricted commercial use — it’s the same license PyTorch Lightning, TensorFlow, and OpenOffice use, for example.
How is Falcon different from other LLMs such as GPT or LLaMA?
Besides the better performance on the OpenLLM leaderboard, as highlighted above, there are also some small architectural differences between Falcon, LLaMA, and GPT. LLaMA () introduced the following architecture improvements, which likely contributed to LLaMA’s better performance over GPT-3 ():
Similar to GPT-3, LLaMA places the layer normalization before the self-attention blocks; however, instead of using LayerNorm () as in GPT-3, the researchers opted for the more recent RMSNorm () variant.
LLaMA borrows the idea of using SwiGLU () activations from PaLM (), instead of using ReLU as in GPT-3.
Finally, LLaMA replaced the absolute positional embeddings used in GPT-3 with rotary positional embeddings (RoPE) () similar to GPTNeo ().
So, , Falcon adopts the same RoPE embeddings as LLaMA (and GPTNeo) but otherwise shares the same architecture as GPT-3, except for using multiquery attention ().
Multiquery attention is a concept where the same key and value tensors are shared for efficiency across different attention heads, as illustrated for a multihead attention block below.

Multiquery attention
Furthermore, according to the , Falcon 40-B was trained on 1000B tokens, where 82% of these tokens were from corpus, and the remaining tokens stemmed from books, papers, conversations (Reddit, StackOverflow, and HackerNews), and code.
While the official Falcon paper has yet to be released, a related paper provides evidence that curated web data could have been the key to success here
To summarize, the Falcon architecture is very similar to GPT-3 and LLaMA. The key-differentiating factor that led to the good performance of Falcon can likely be attributed to its training dataset.
Parameter-Efficient Finetuning Methods
The remainder of this article will mostly focus on the Falcon 7B, which allows us to finetune the model on a single GPU. Falcon 7B is currently considered the best open-source LLM in its size class. (But the same code outlined in the remainder of this article can be used for the larger 40B variants as well.)

Notable open-source LLMs. Excerpt from the OpenLLM leaderboard
There are many parameter-efficient finetuning paradigms, as outlined in the excellent survey.
All of these methods achieve the same goal: They let us train a model in a more parameter-efficient fashion compared to conventional finetuning, where we update the original model parameters. The big question is, which ones are most worthwhile in practice?
Let’s start with a performance benchmark, then dive into how these different methods work.
Performance Comparison
To use a common dataset for this performance benchmark, we will consider the popular for instruction-finetuning, which consists of 52k instruction-finetuning examples. It’s structured as follows:
Instruction: “Give three tips for staying healthy.”
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. 2. Exercise regularly to keep your body active and strong. 3. Get enough sleep and maintain a consistent sleep schedule.”
The three methods we consider are
Low-Rank Adaptation (LoRA) ();
LLaMA Adapter ();
LLaMA-Adapter v2 ().
Yes, we can use LLaMA-Adapter methods for finetuning — despite the name, these adapter methods are not specific to the LLaMA architecture, as we will discuss later.
Preparing the model and dataset
For this benchmark, we will be using the open-source library, which provides efficient implementations for training and using various LLMs.

The Lit-Parrot repository (https://github.com/Lightning-AI/lit-parrot)
The first step is to download the model:
python scripts/download.py --repo_id tiiuae/falcon-7b(This requires approximately 20 Gb of storage.)
Second, we convert the weights into a standardized form:
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7bThird, we have to download the dataset. For this example, we will be using the Alpaca dataset consisting of 52k instruction pairs:
python scripts/prepare_alpaca.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
(More on using custom datasets later.)
Running the code
Now, we are running the finetuning scripts for the Falcon 7B model. We are going to compare 4 different methods below. For now, we are going to focus on the finetuning results. And we will discuss how these methods work later in this article.
Adapter:
python finetune/adapter.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/Adapter v2:
python finetune/adapter_v2.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/LoRA:
python finetune/lora.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/Full finetuning (updating all layers):
python finetune/lora.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/Let’s take a look at the time it takes to finetune the LLM first:
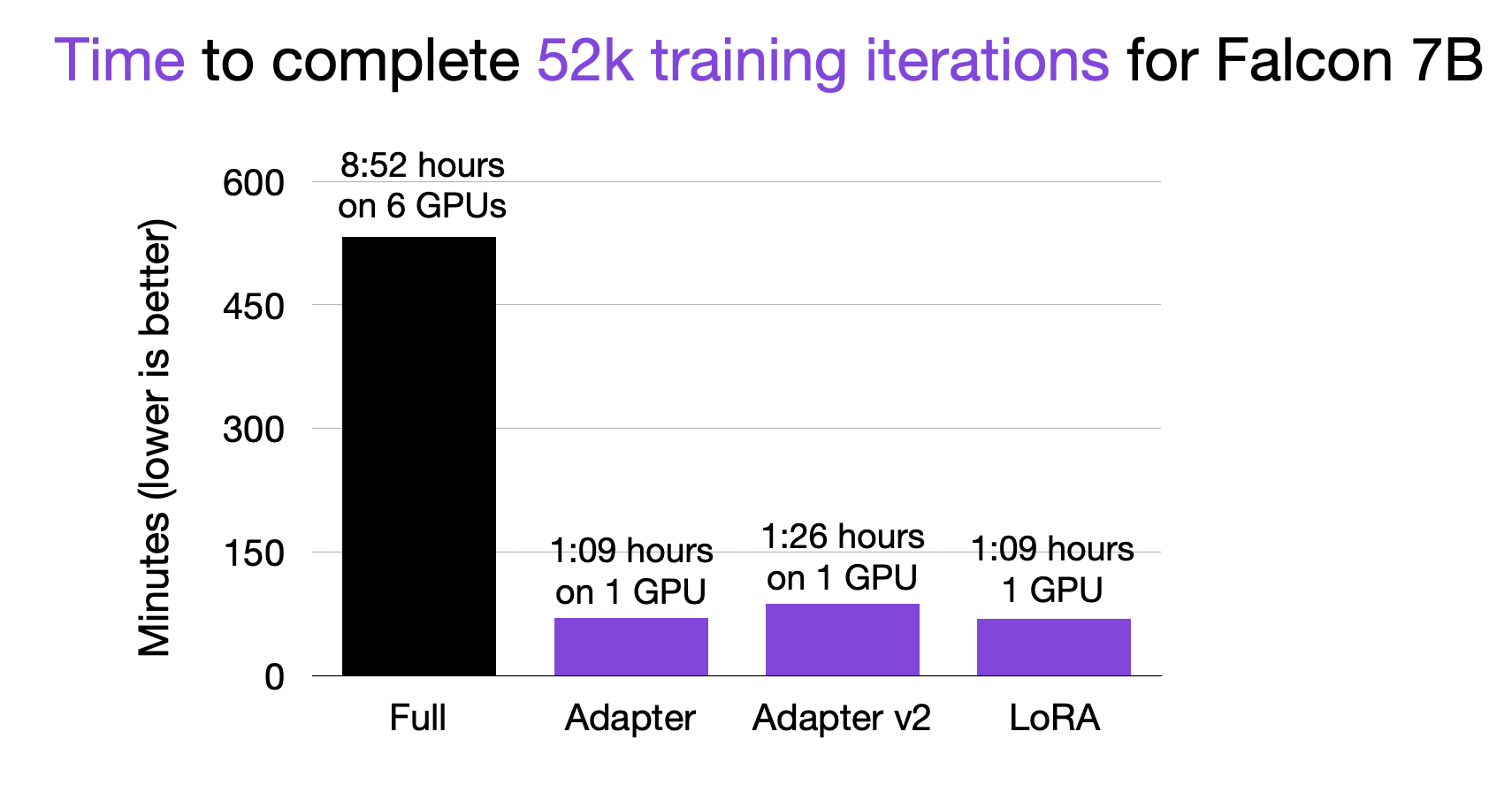
As we can see in the chart above, using a parameter-efficient finetuning method is about 9 times faster than finetuning all layers (“full”). Moreover, finetuning all layers required 6 GPUs due to memory constraints, whereas the Adapter methods and LoRA could be used on a single GPU.
So, speaking of GPU memory requirements, the peak memory requirements are plotted below:
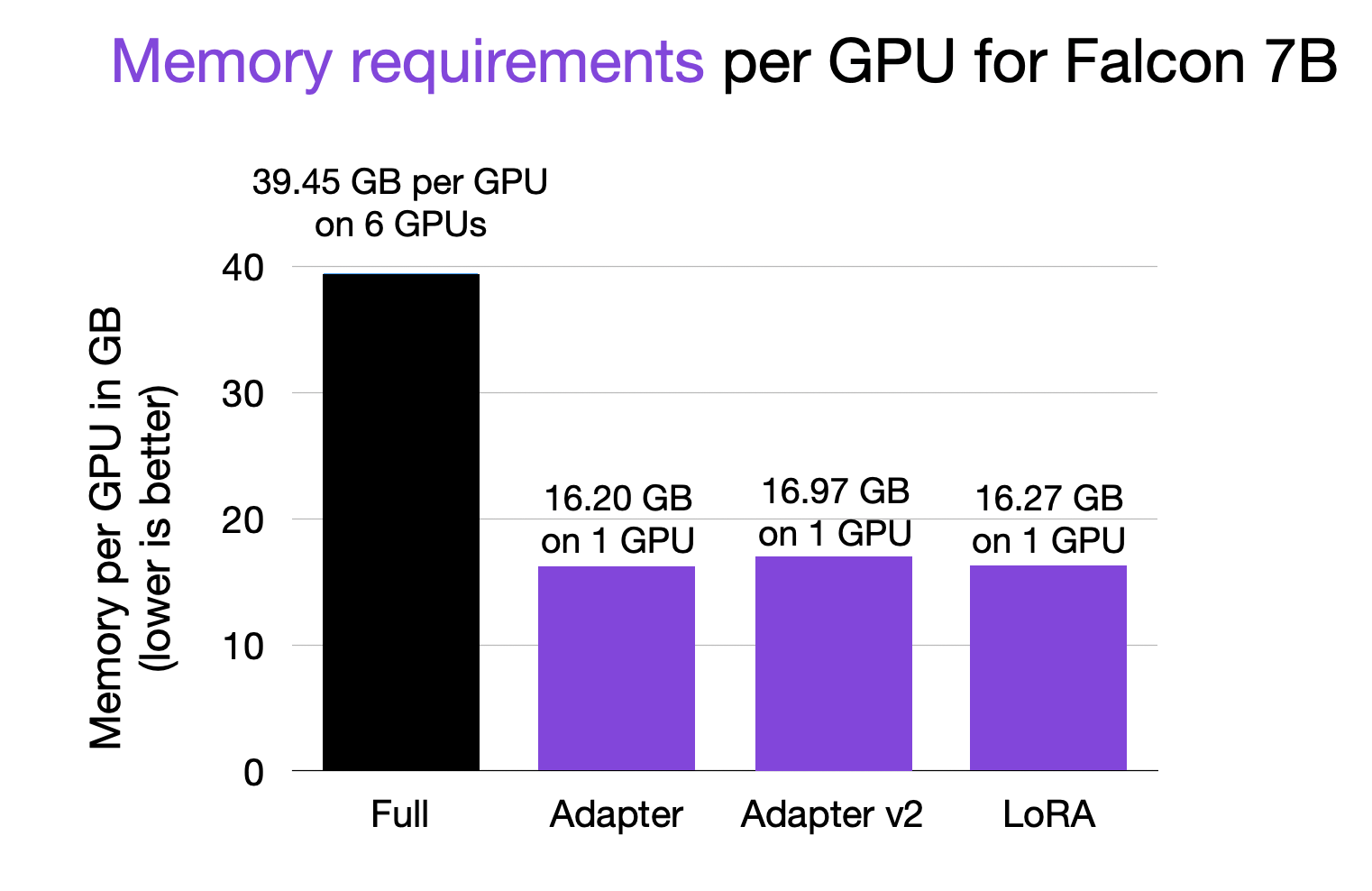
Finetuning all layers of Falcon 7B required ~40 GB on each of the 6 GPUs (here, via tensor sharding using DeepSpeed). So, that’s 240 Gb in total. In contrast, the parameter-efficient finetuning methods only required ~16 GB RAM, which allows users to even finetune these models on a single consumer-grade GPU.
By the way, note that the memory requirements are directly related to the number of parameters that are required to be updated for each method:
Full finetuning: 7,217,189,760
Adapter: 1,365,330
Adapter v2: 3,839,186
LoRA: 3,506,176
Yes, that’s right, full finetuning (updating all layers) requires updating 2000 times more parameters than the Adapter v2 or LoRA methods, while the resulting modeling performance of the latter is equal to (and sometimes even better than) full finetuning, as reported in .
And regarding inference speed, we have the following performance:
- LoRA: 21.33 tokens/sec; Memory used: 14.59 GB (it is possible to merge the LoRA weights with the original weights to improve the performance to >28 tokens/s)
- Adapter: 26.22 tokens/sec; Memory used: 14.59 GB
- Adapter v2: 24.73 tokens/sec; Memory used: 14.59 GB
Hyperparameters
If you want to replicate the results above, here is an overview of the hyperparameter settings I used:
bfloat16precision (I wrote more about bfloat 16 in the article ).Also, the scripts were configured to train the models for 52k iterations (the size of the Alpaca dataset) using an effective batch size of 128 with gradient accumulation (more details on gradient accumulation in my article ).
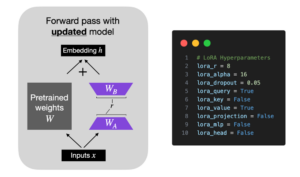
For LoRA, I used a rank of 8 to roughly match the number of parameters added by Adapter v2.
adapter.py,adapter_v2.py, andlora.pywere trained on a single A100 GPU each. Thefull.pyscript required 6 A100 GPUs and tensor sharding via DeepSpeed.
In addition, I uploaded the scripts with the modified settings on GitHub for reference purposes.
Quality Comparison
While a detailed performance benchmark on real-world tasks is out-of-scope for this blog article, the qualitative model performance of these methods is approximately the same. It matches the full finetuning performance as discussed in the and papers.
If you want to use and evaluate these models, you can use the following generate scripts provided in lit-parrot, for example:
python generate/lora.py --checkpoint_dir checkpoints/tiiuae/falcon-7b --lora_path out/lora/alpaca/lit_model_lora_finetuned.pth LLaMA-Adapter
In short, the LLaMA-Adapter method (which we referred to as Adapter in the blog post) adds a small number of trainable tensors (parameters) to an existing LLM. Here, the idea is that only the new parameters are trained, whereas the original parameters are left frozen. This can save a lot of compute and memory during backpropagation.
In a bit more detail LLaMA-Adapter adds prepends tunable prompt tensors (prefixes) to the embedded inputs. In the LLaMA-Adapter method, these prefixes are learned and maintained within an embedding table rather than being provided externally. Each transformer block in the model has its own distinct learned prefix, allowing for more tailored adaptation across different model layers.
In addition, LLaMA-Adapter introduces a zero-initialized attention mechanism coupled with gating. The motivation behind this so-called zero-init attention and gating is that adapters and prefix tuning could potentially disrupt the linguistic knowledge of the pretrained LLM by incorporating randomly initialized tensors (prefix prompts or adapter layers), resulting in unstable finetuning and high loss values during initial training phases.
The main concept behind the LLaMA-Adapter method is illustrated in the visualization below, where the modified parts of a regular transformer block are highlighted in purple.
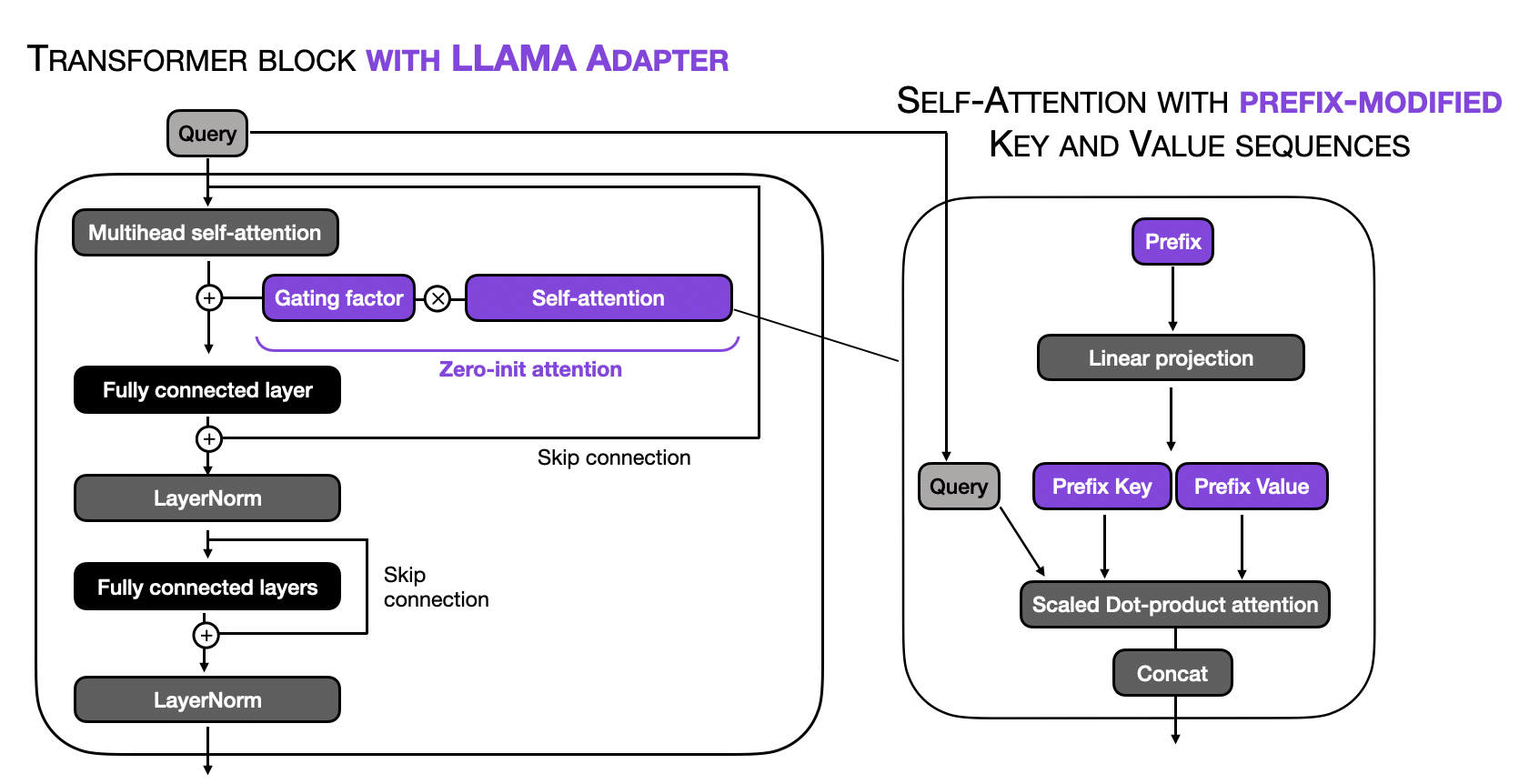
Outline of LLaMA-Adapter
One key idea is to add a small number of trainable parameters. The other important thing to notice here is that the method is not unique to LLaMA LLMs — this is why we could use it to finetune the Falcon model, for example.
If you are interested in additional details about the LLaMA-Adapter method, check out my article .
LLaMA-Adapter v2
When finetuning LLMs on text and instructions, the more recent LLaMA-Adapter v2 () increases the number of tunable parameters compared to LLaMA-Adapter V1 (, the first difference is that it adds bias units to the fully connected (linear) layers. Since it merely modifies the existing linear layers from input * weight to input * weight + bias, it only has a small impact on the finetuning and inference performance.
The second difference is that it makes the aforementioned RMSNorm layers trainable. While this has a small effect on the training performance due to updating additional parameters, it doesn’t impact the inference speed as it doesn’t add any new parameters to the network.
Low-Rank Adaptation (LoRA)
Low-Rank Adaptation () is similar to the Adapter methods above in that it adds a small number of trainable parameters to the model while the original model parameters remain frozen. However, the underlying concept is fundamentally very different from the LLaMA-Adapter methods.
In short, LoRA decomposes a weight matrix into two smaller weight matrices, as illustrated below:

Outline of LoRA
For more details about LoRA, please see my longer, more technical article .
Finetuning LLMs On Your Custom Dataset
In this article, we ran a few performance benchmarks on the Alpaca (52k instructions) dataset. In practice, you may be curious about how to apply these methods to your own dataset. After all, the advantage of open-source LLMs is that we can finetune and customize them to our target data and tasks.
In essence, all it takes to use any of these LLMs and techniques on your own dataset is to ensure they are formatted in a standardized form, which is described in more detail in Aniket Maurya’s blog post .
Conclusion
In this article, we saw how we can fientune a state-of-the-art open-source LLM like Falcon on a single GPU using LLaMA-Adapter methods on LoRA.
Whereas the conventional finetuning of all layers takes 9 hours and requires at least 6 A100 GPUs with 40 GB of RAM each, the parameter-efficient finetuning methods highlighted in this article can finetune the same model 9x faster on a single GPU, requiring 15x less GPU memory.
If you are interested in adopting these methods for your own projects, check out the open-source repository to get started.
Acknowledgements
I want to thank Carlos Mocholí, who has been a big help with fixing my LoRA scripts. Also, a big shoutout to Adrian Wälchli and Luca Antiga for integrating Falcon into the Lit-Parrot repository.