- Share:



Unit 6 Exercises
Exercise 1: Learning Rate Warmup
This exercise asks you to experiment with learning rate warmup during cosine annealing.
Learning rate warmup is a technique that involves gradually increasing the learning rate from a small value to a larger target value over a certain number of iterations or epochs. Learning rate warmup has empirically been shown to stabilize training and improve convergence.
In this notebook, we are adapting the cosine annealing code from Unit 6.2 Part 5.
In particular, your task is to replace the torch.optim.lr_scheduler.CosineAnnealingLR scheduler with a similar scheduler that supports warmup. For this, we are going to use the LinearWarmupCosineAnnealingLR class from the PyTorch Lightning Bolts library, which can be installed via
pip install pl-bolts
And you can find more about the LinearWarmupCosineAnnealingLR usage in the documentation here
Note that you can use the accompanying notebook as a template and fill in the marked blanks. If you use a schedule similar to the one shown in the image below, you should get ~89% accuracy.
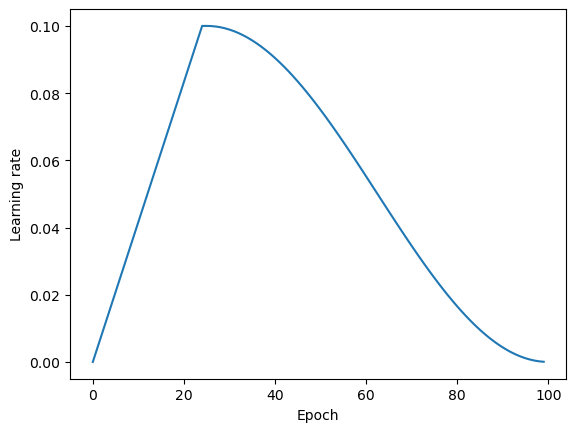
Starter code: https://github.com/Lightning-AI/dl-fundamentals/tree/main/unit06-dl-tips/exercises/1_cosine-with-warmup
Exercise 2: Adam With Weight Decay
The task of this exercise is to experiment with weight decay. Note that we haven’t covered weight decay in the lecture. Related to Dropout (which we covered in Unit 6), weight decay is a regularization technique used in training neural networks to prevent overfitting.
Traditionally, a related method called L2-regularization is used to add a penalty term to the loss function (e.g., the cross entropy loss) that encourages the network to learn smaller weight coefficients. And smaller weights can often lead to less overfitting. That’s because smaller weights can help with overfitting. They encourage the model to learn simpler, more generalizable patterns from the training data, rather than fitting the noise or capturing complex, specific patterns that may not generalize well to new, unseen data.
If you want to learn more about L2 regularization, I covered it in this video here..
Now weight decay is a technique that is directly applied to the weight update rule in the optimizer, skipping the loss modification step. However, it has the same effect as L2-regularization.
For this, we are going to use the so-called AdamW optimizer. AdamW is a variant of the Adam optimization algorithm that decouples weight decay from the adaptive learning rate. In AdamW, weight decay is applied directly to the model’s weights instead of incorporating it into the gradients as in the standard Adam. This decoupling is particularly beneficial when using adaptive learning rate methods like Adam, as it allows weight decay to work more effectively as a regularizer.
If you are interested, you can read more about AdamW in the original research paper here..
And here is the relevant PyTorch documentation page for the AdamW optimizer.
Your task is now to take the template code and swap the Adam optimizer with AdamW to reduce overfitting. You can mainly ignore the other hyperparameters and focus on changing the weight_decay parameter of AdamW.
Below is an illustration of how Adam compares to AdamW with a tuned weight decay parameter:
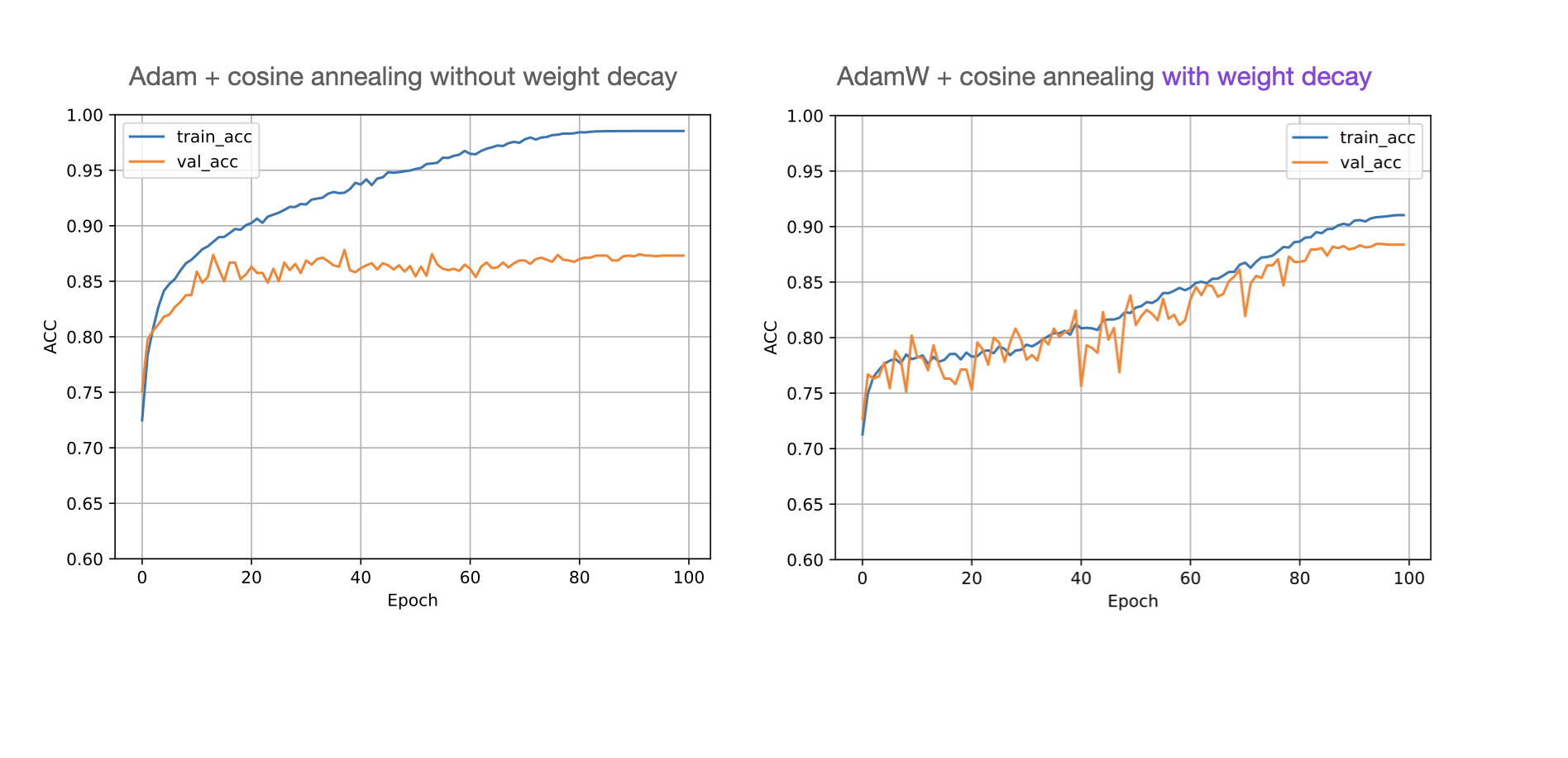
(Moreover, the test set performance should increase from 86% to 89%.)
Starter code: https://github.com/Lightning-AI/dl-fundamentals/tree/main/unit06-dl-tips/exercises/2_adam-with-weight-decay
Log in or create a free Lightning.ai account to access:
- Quizzes
- Completion badges
- Progress tracking
- Additional downloadable content
- Additional AI education resources
- Notifications when new units are released
- Free cloud computing credits
Watch Video 1
Unit 6 Exercises
Videos
Follow along in a Lightning Studio
DL Fundamentals 6: DL Tips & Tricks
 Sebastian
Sebastian