Takeaways
In this blog you will learn about the latest open-source large language model Falcon. How to efficiently fine-tune Falcon and run inference on consumer-grade hardware with less than 4.5 GB of GPU memory!
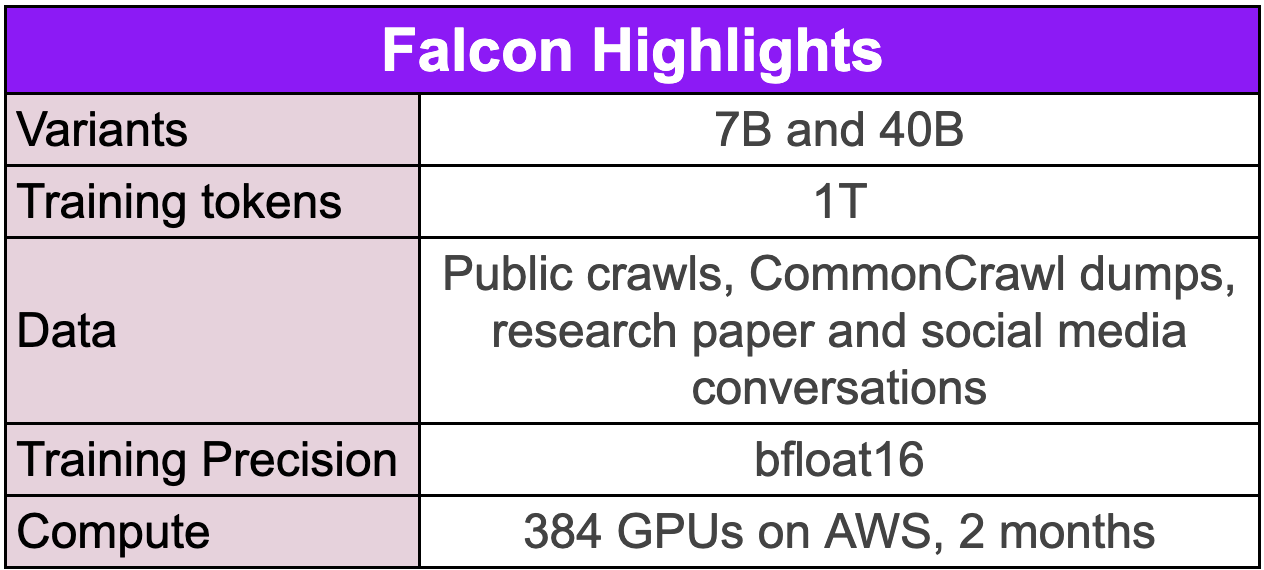
Falcon is the latest open-source large language model released by Technology Innovation Institute. It is an autoregressive decoder-only model with two variants: a 7 billion parameter model and a 40 billion parameter model. The 40B model variant was trained on 384 GPUs on AWS for 2 months.
We have integrated Falcon into Lit-GPT. You can use it for finetuning, quantization, and running inference with quantization that uses less than ~4.5 GB GPU memory.
Finetune Falcon in 3 steps
You can finetune it on a single GPU with at least 14 GB of memory when using parameter-efficient finetuning techniques. The finetuning of Falcon 40B on the Alpaca instruction dataset can be reduced from 30 hours to 30 minutes using the LLaMA Adapter (8 A100s).
Lit-Parrot provides the script for data preparation and finetuning. It provides scripts for downloading weights, preparing datasets, finetuning, and performing inference. To finetune a custom dataset using Falcon, follow these three steps:
- Download the weights.
- Prepare the dataset.
- Perform finetuning.
Download and convert the Falcon weights
This blog post is using the Falcon-7B variant, but you can also run all the scripts with 40B.
# download the model weights
python scripts/download.py --repo_id tiiuae/falcon-7b
# convert the weights to Lit-Parrot format
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7b
Prepare the dataset
We will use the Alpaca dataset from Stanford, a 52K instruction example dataset. You can customize the prepare_alpaca script to use your own custom dataset.
The prepare_alpaca provides prepare function that loads the raw instruction dataset, creates prompts, and tokenizes them using the model tokenizer provided in the checkpoint_dir. The tokenized data is split into training and test sets based on the test_split_size provided and saved to the destination_path.
python scripts/prepare_alpaca.py \
--destination_path data/alpaca \
--checkpoint_dir checkpoints/tiiuae/falcon-7b
You can follow how to finetune LLM on a custom dataset blog for a step-by-step tutorial.
Finetuning the Falcon model
Once you have prepared your dataset, it is pretty straightforward to finetune the model. You can adjust the micro_batch_size, number of devices , epochs, warmup and other hyperparameters on the top of the finetuning script. We will be using the default hyperparameters to finetune Falcon on Alpaca dataset using the AdapterV2 technique.
python finetune/adapter_v2.py \
--data_dir data/alpaca \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--out_dir out/adapter/alpaca
You can find the model checkpoints in the out/adapter/alpaca folder and use the generation script to play around with the model. It takes approximately half an hour to finetune the model on a 8 A100 GPUs or approximately 3 hours on 1 GPU.
Running inference with the finetuned model
You can use the finetuned checkpoint of your LLM for generating texts. Lit-Parrot provides generation scripts. We will use the adapter_v2 for generating texts. It supports int8 and int4 quantization for devices with less GPU memory.
To run inference under 10 GB GPU memory you can use the int8 precision by using the llm.int8 quantize argument.
python generate/adapter_v2.py \
--adapter_path out/adapter/alpaca/lit_model_adapter_finetuned.pth \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--quantize llm.int8 \ # Quantization argument
--prompt "What food do lamas eat?"
If you have limited GPU memory and want to run Falcon-7B inference using less than 4.5 GB of memory, you can use the int4 precision. This reduces Falcon-40B memory usage from 80 GB to around 24 GB (note that the quantization process consumes around 32 GB). Lit-Parrot provides a GPTQ conversion script that you can find here.
python generate/adapter_v2.py \
--adapter_path out/adapter/alpaca/lit_model_adapter_finetuned.pth \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--quantize gptq.int4 \ # quantization argument
--prompt "What food do lamas eat?"
Below is a benchmark that shows how precision affects GPU memory and inference speed. For int4, we are using the Triton kernels released with the original GPTQ, which is slower but can be optimized with new GPTQ implementations or alternative quantization methods. Stay tuned to find out when we optimize the int4 precision!
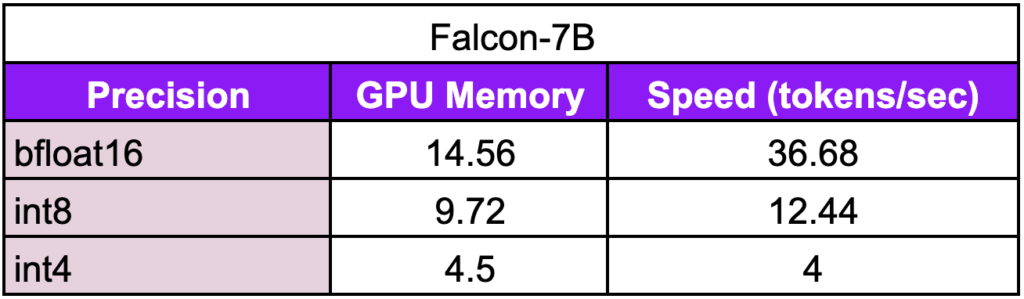
Evaluated on Nvidia A100
Learn more about large language models and efficient fine-tuning techniques 👇
This article provided you with short step-by-step instructions to finetune your own Falcon model. We saw that thanks to parameter-efficient finetuning techniques, it’s possible to do it on a single GPU. If you want to learn more about these techniques, check out our more in-depth guides below.
- How To Finetune GPT Like Large Language Models on a Custom Dataset
- Accelerating Large Language Models with Mixed-Precision Techniques
- Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
- Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters
Join our Discord community to chat and ask your questions!