Takeaways
In this blog, we’ll learn how to build a chatbot using open-source LLMs. We will be using Lit-GPT and LangChain. Lit-GPT is an optimized collection of open-source LLMs for finetuning and inference. It supports – Falcon, Llama 2, Vicuna, LongChat, and other top-performing open-source large language models.
This article is outdated with respect to the latest LitGPT version. Please check the official repo for latest code samples.
Advancements of LLMs in Chatbot Development
Chatbots have become integral to many industries, including e-commerce, customer service, and healthcare. With advancements in large language models, building a chatbot has become easier than ever. Chatbots can find relevant information from a large knowledge base and present it to the user. It can connect to a database, query from a vector database, and answer questions based on documents.
LLMs have the ability to generate answers based on the given prompt. They can now even consume a whole document and respond to queries based on the document. In-context learning provides a way where LLM learns how to solve a new task at inference time without any change in the model weights. The prompt contains an example of the task that model is expected to do. The prompt engineering discussion can go much longer but we will be focusing on how to build your first MVP chatbot.
Making conversation with an LLM
Foundational large language models (LLMs) are trained to predict the next word. These LLMs are then finetuned on an instruction dataset, which consists of user input, context, and expected output, to follow human instruction and generate relevant responses. An example of an instruction prompt to make the LLM behave like a chatbot is provided below.
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: {input}
ASSISTANT:The first two lines serve as instructions to the LLM, directing it to provide helpful, detailed, and polite responses as a chatbot assistant. The third line, USER: {input}, represents the user input, where {input} will be replaced by the user’s query. The LLM will then start predicting the next words to produce a response to the user’s prompt.
In this tutorial, we will use an instruction-tuned model and provide the user input as a prompt. Let’s create our first chatbot by using the prompt defined above. We will use LongChat, which is a LLaMA-like model trained on a chat dataset with a context length of 16K (~12K words).
We will define our prompt template as longchat_prompt_template, and for each user query, we will format the string and feed it to the model.
longchat_template = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: {input}
ASSISTANT:"""
output = longchat_template.format(input="My name is Aniket?")We will be using the llm-inference library, which is just a wrapper over Lit-GPT to provide an API interface for loading the model and using the generation method. First, we load our model with 4-bit quantization using bnb.nf4 that will require about 6GB GPU memory.
# pip install llm-inference
from llm_inference import LLMInference, prepare_weights
from rich import print
path = str(prepare_weights("lmsys/longchat-7b-16k"))
model = LLMInference(checkpoint_dir=path, quantize="bnb.nf4")Next, use the model.chat method, an API interface for the Lit-GPT chat script, to generate the response from the formatted template with user input.
# pip install llm-inference
from llm_inference import LLMInference, prepare_weights
from rich import print
path = str(prepare_weights("lmsys/longchat-7b-16k"))
model = LLMInference(checkpoint_dir=path, quantize="bnb.nf4")
longchat_template = """A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: {input}
ASSISTANT:"""
output = model.chat(longchat_template.format(input="My name is Aniket?"))
print(output)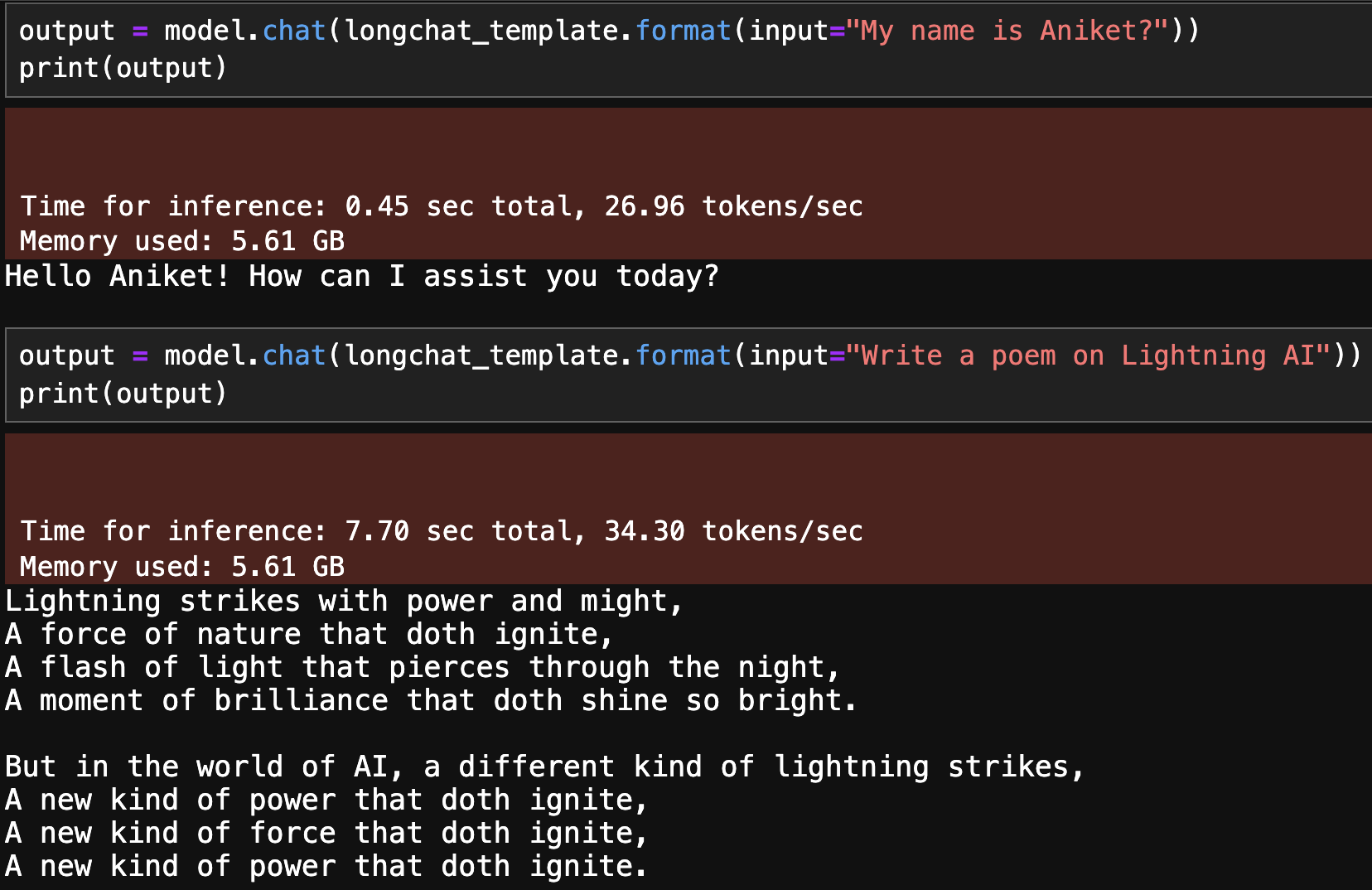
Assistant doesn’t have a memory
Our chatbot works great, but there is an issue: our assistant is stateless and forgets the previous interactions. As you can see below, the user prompts the bot with their name and then, in the second interaction, asks “What is my name?” However, the assistant is not able to provide the requested information due to its lack of memory.
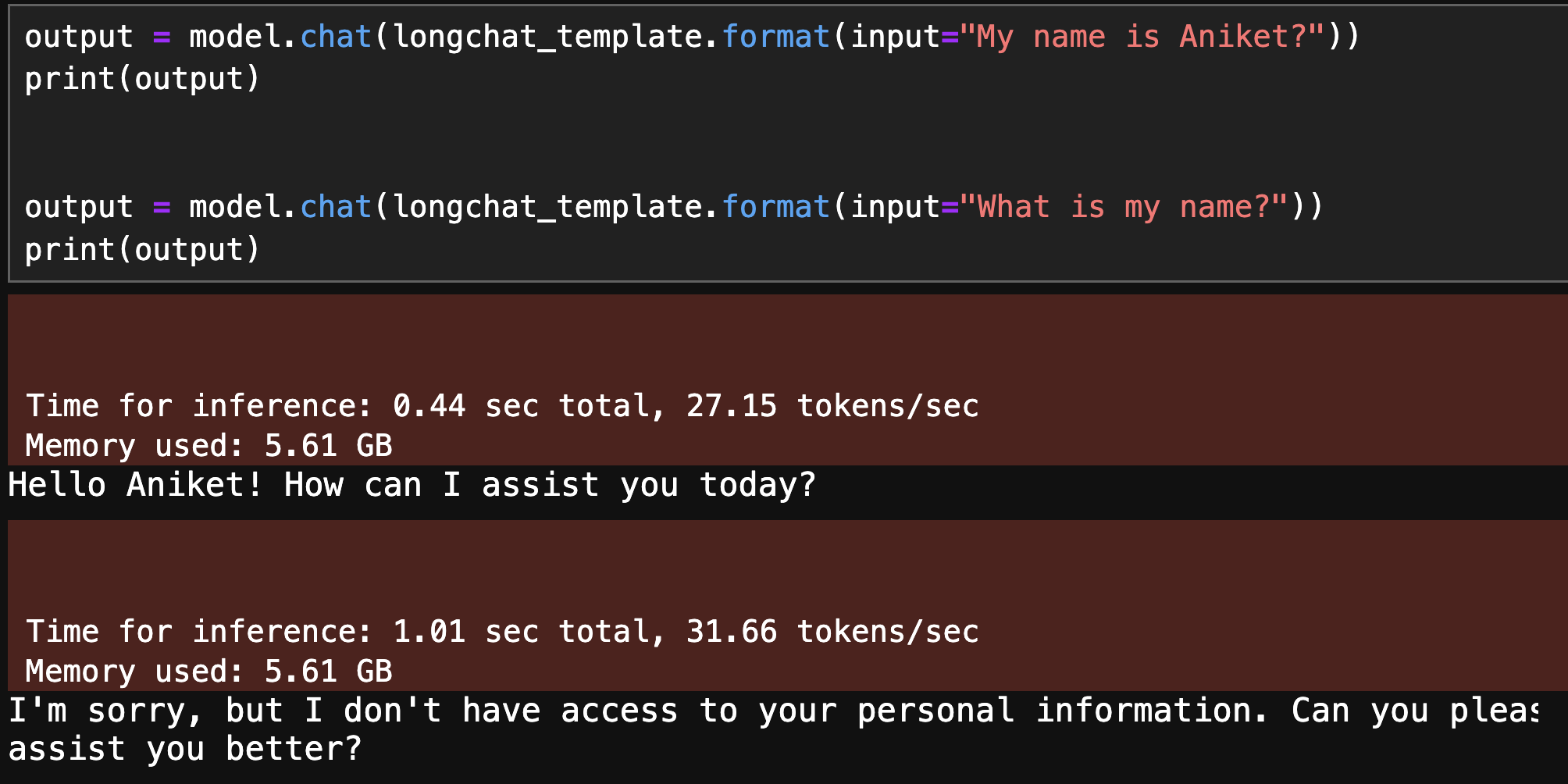
Fixing this issue is not too difficult. We can provide the context to the LLM through the prompt and it should be able to look it up. We can store our conversation history and inject it into the prompt like the example below where the user provides their name as context, and the model was able to answer their name in a follow-up question.
Memory and prompting – Maintaining a continued conversation
LLMs are stateless interfaces that provide language understanding and retrieval capabilities. However, LLMs do not have memory, so subsequent queries are not affected by earlier calls. Therefore, if you provide your name in one query and expect the LLM to remember it for the next query, it will not happen.
To give LLMs the ability to remember previous interactions, we can store the conversation history in the prompt template as context for the model. We create the following prompt template –
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
Context:
{history}
USER: {input}
ASSISTANT:{history} is replaced with the previous conversations, and {input} is replaced by the current query from the user. We keep updating the history and input for each interaction. LangChain provides some useful classes for formatting prompts and updating the context using more advanced ways, like looking up context from a vector database.
We will use the PromptTemplate class with history and input as variables.
from langchain.prompts import PromptTemplate
longchat_template = """A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
Context:
{history}
USER: {input}
ASSISTANT:"""
longchat_prompt_template = PromptTemplate(
input_variables=["input", "history"], template=longchat_template
)
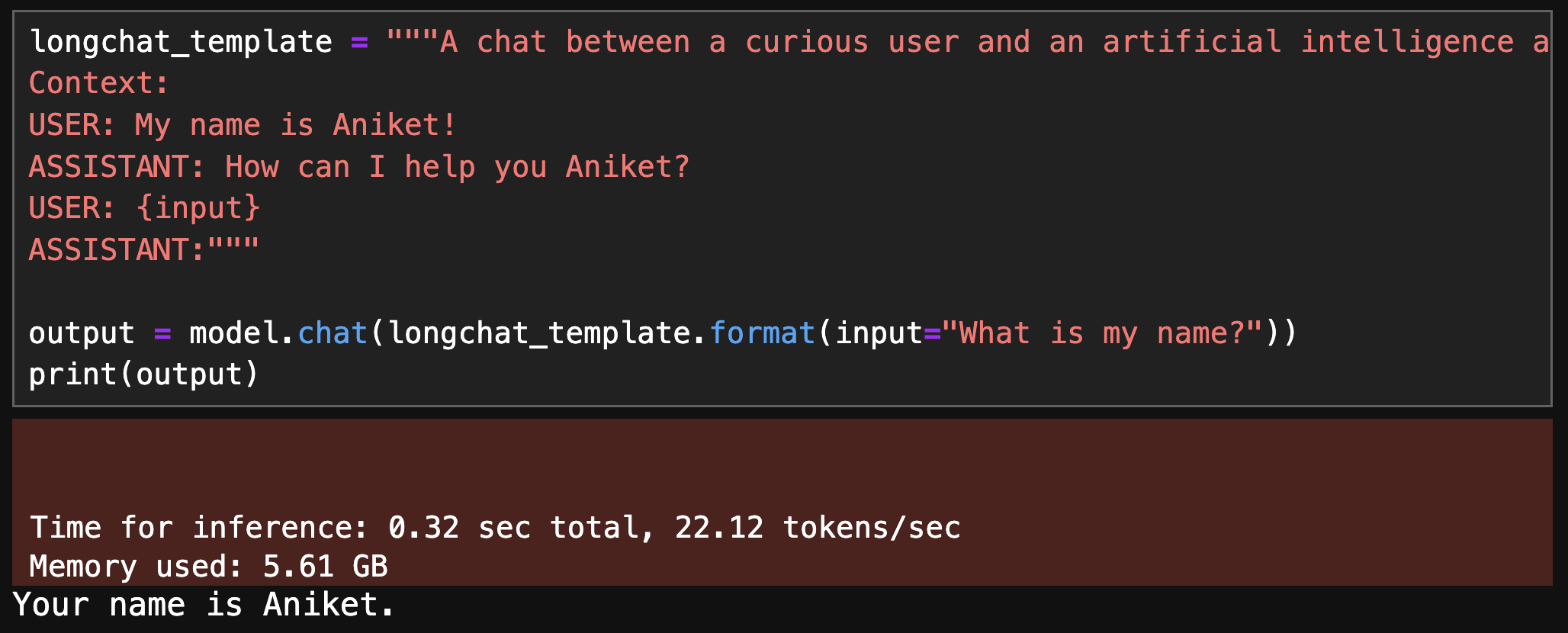
print(longchat_prompt_template.format(
input = "What is my name?",
history ="USER: Hi, I am Aniket!\nAssistant: How can I help you Aniket?"
))You can format the longchat_prompt_template using longchat_prompt_template.format method by providing input and history .
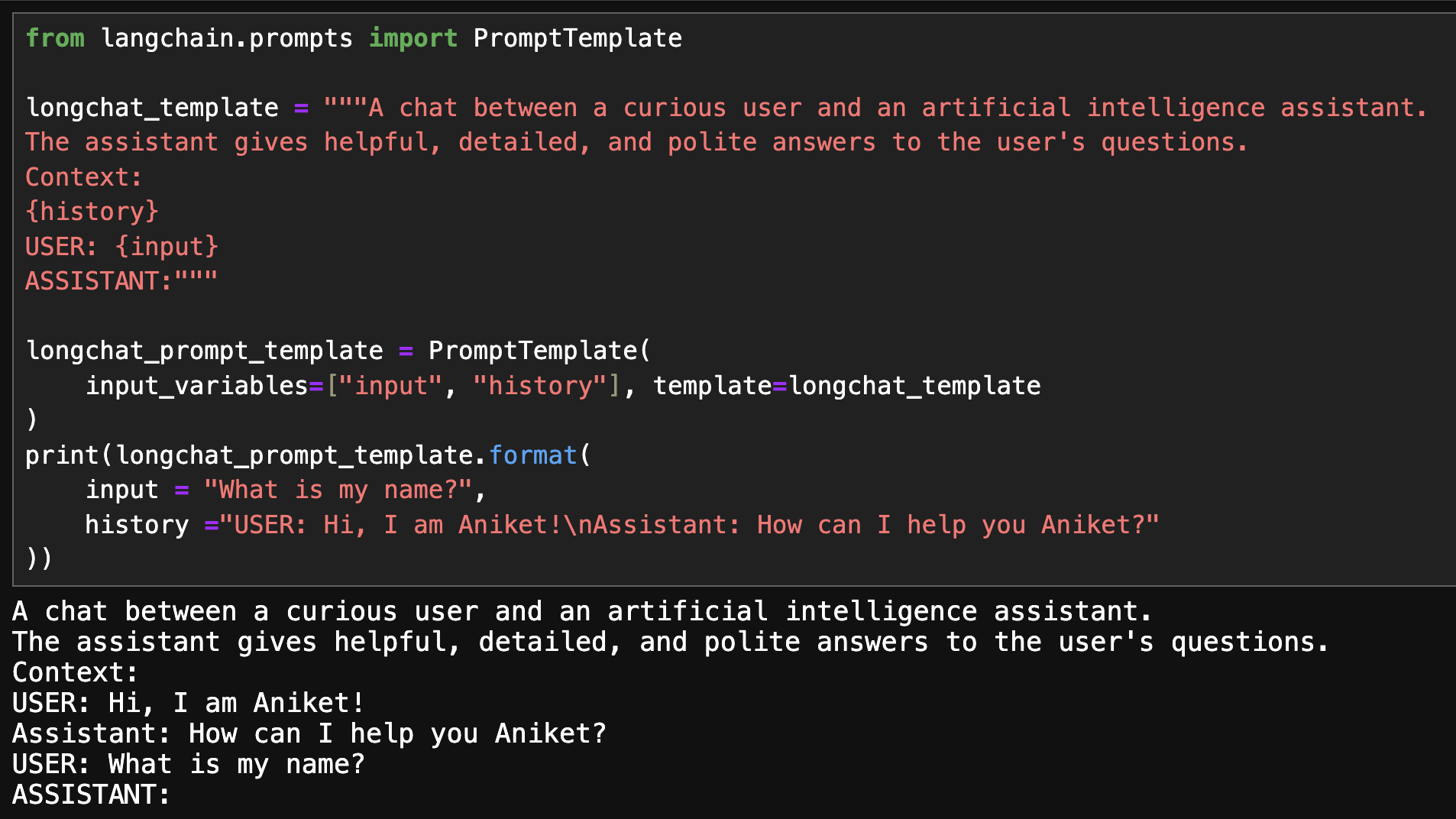
Next, we create a conversation chain using the ConversationChain class. It takes the LLM, prompt template, and a memory manager object as input. We will use ConversationBufferMemory, which stores all our conversations and update the prompt template history on each interaction.
from langchain.chains import ConversationChain
from llm_chain import LitGPTLLM
from llm_inference import LLMInference
path = "checkpoints/lmsys/longchat-7b-16k"
model = LLMInference(checkpoint_dir=path, quantize="bnb.nf4")
llm = LitGPTLLM(model=model)
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory(ai_prefix="Assistant", human_prefix="User"),
prompt=longchat_prompt_template,
)
conversation("hi, I am Aniket")["response"]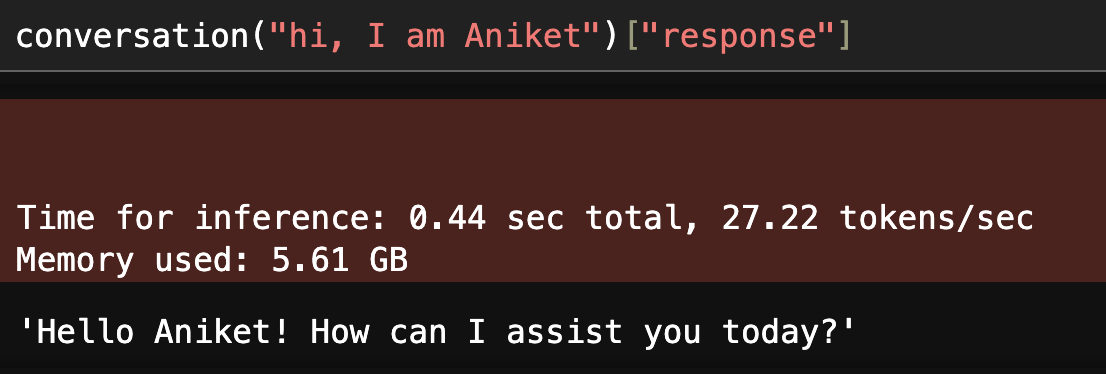
You can access the memory using the conversation object and manipulate it as well. To print the current conversation we can run print(conversation.memory.buffer)
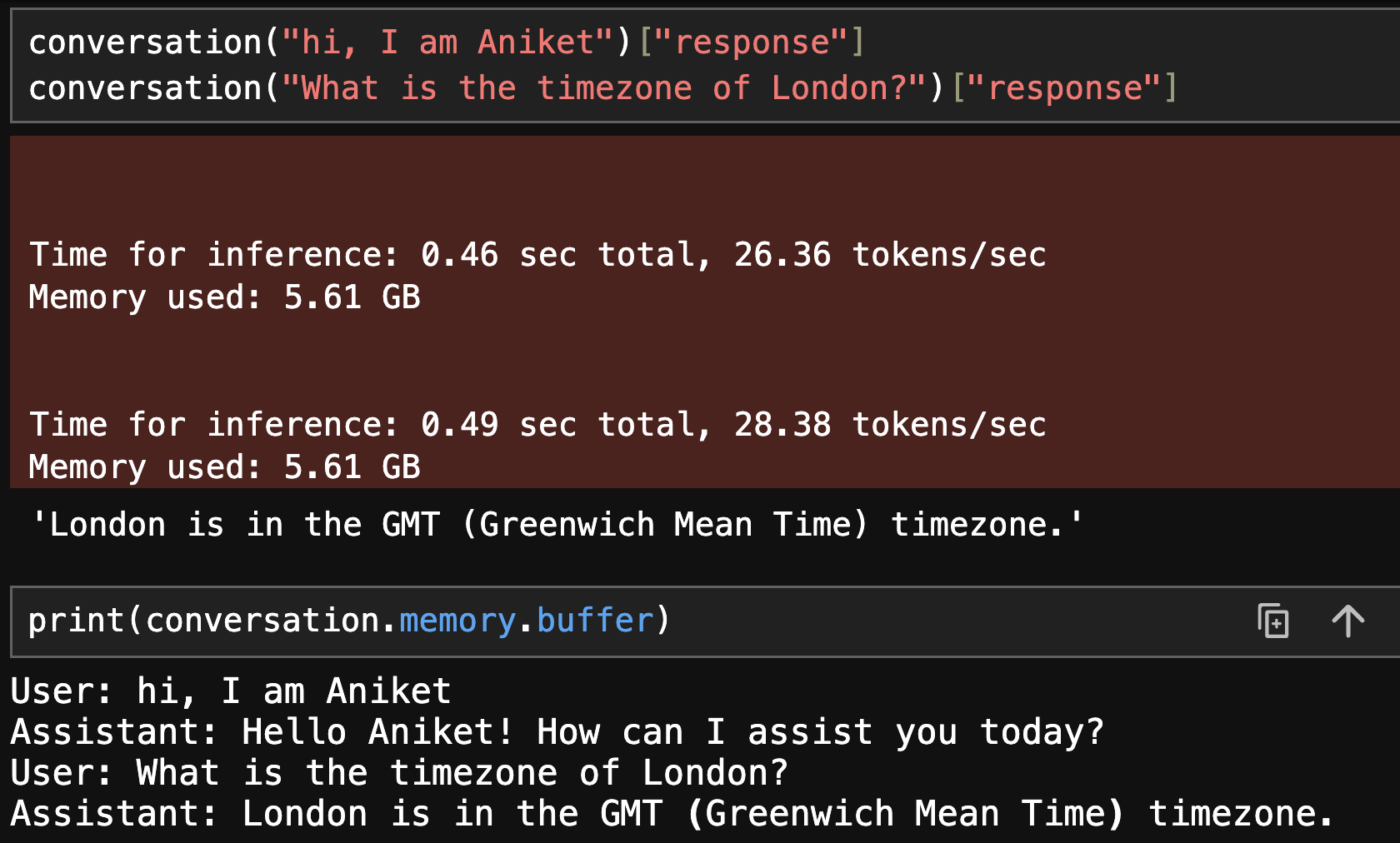
This memory is updated into the prompt as context after each conversation.
QA over Documents as context
The chatbots can be further extended to do more complex tasks like extracting documents from a database and answering questions based on the given document as context. You can build a document QnA bot with this technique. We won’t go deep here in this blog, but if you’re curious, you can replace the model memory with another LLM that searches for relevant documents and update the context in the prompt template with the extracted document. You can read more about it on the LangChain example here.
Conclusion
In conclusion, building a chatbot using open-source LLMs has become easier than ever with advancements in large language models. The ability of LLMs to generate answers based on the given prompt, even from a whole document, has made them an integral part of many industries. By using instruction-tuned models and providing user input as a prompt, we can create chatbots that provide helpful, detailed, and polite responses. While chatbots are stateless, we can use chat history as context for the model to remember previous interactions. Finally, the chatbots can be further extended to do more complex tasks like extracting documents from a database and answering questions based on the given document as context.
Resources
Join our Discord community to chat and ask your questions!

