Learn how to:
Optimize your PyTorch model for inference using DeepSpeed Inference.Serving large models in production with high concurrency the ability to serve multiple simultaneous inference requests and throughputunits of data processed per unit of time is essential for businesses to respond quickly to users and be available to handle a large number of requests. Previously, we’ve shown you how to scale model serving with dynamic batching and autoscaling in order to serve Stable Diffusion and scale your performance to handle over 1000 concurrent users.
the ability to serve multiple simultaneous inference requests and throughputunits of data processed per unit of time is essential for businesses to respond quickly to users and be available to handle a large number of requests. Previously, we’ve shown you how to scale model serving with dynamic batching and autoscaling in order to serve Stable Diffusion and scale your performance to handle over 1000 concurrent users.
Below, we explore how we leveraged several optimizations from PyTorch and other third-party libraries such as DeepSpeed to reduce the cost of serving Stable Diffusion without significant impact on the quality of the images generated.
Using the following prompts, here are some examples of the generated images before and after optimization:
“astronaut riding a horse, digital art, epic lighting, highly-detailed masterpiece trending HQ”

No significant loss in image quality after optimizing.
As can be seen from the example above, we observed no significant change or loss in the quality of images generated despite improving inference speed by over 300%.
We focused on optimizing the original Stable Diffusion and managed to reduce serving time from 6.4 to 2.09 seconds for batch size 1 on A10. This is one of the most powerful and cost-effective machines available on the Lightning Platform. All measurements were taken in production using this server and load testing app.
(In case you’re wondering how much time these optimizations can save you, it took 19 seconds on an M1 Mac Metal GPU and 134 seconds on an M1 Mac CPU).
PyTorch Optimizations
Optimization #1
Usetorch.float16 instead of torch.float32 with mixed precision from PyTorch.Result: 40% gain in inference speed
import torch
from torch import autocast
model = model.to(device="cuda", dtype=torch.float16)
# Mixed precision
with autocast("cuda"):
data = ...
model(data.to(device="cuda"))
Optimization #2
usetorch.inference_mode (where the model achieves better performance by disabling view tracking and version counter bumps) or torch.no_grad.Result: <1% gain in inference speed
import torch
from torch import inference_mode, no_grad
model = model.to(device="cuda", dtype=torch.float16)
# Inference mode
with inference_mode():
with autocast("cuda"):
data = ...
model(data.to(device="cuda"))
# No gradients mode
with no_grad():
with autocast("cuda"):
data = ...
model(data.to(device="cuda"))
Optimization #3
Use CUDA Graphs.Result: 5% gain in inference speed
In this technique, the graph of operations is captured and replayed at once, rather than in a sequence of individually-launched operations. This reduces overhead as GPU kernels are not returning back to Python.
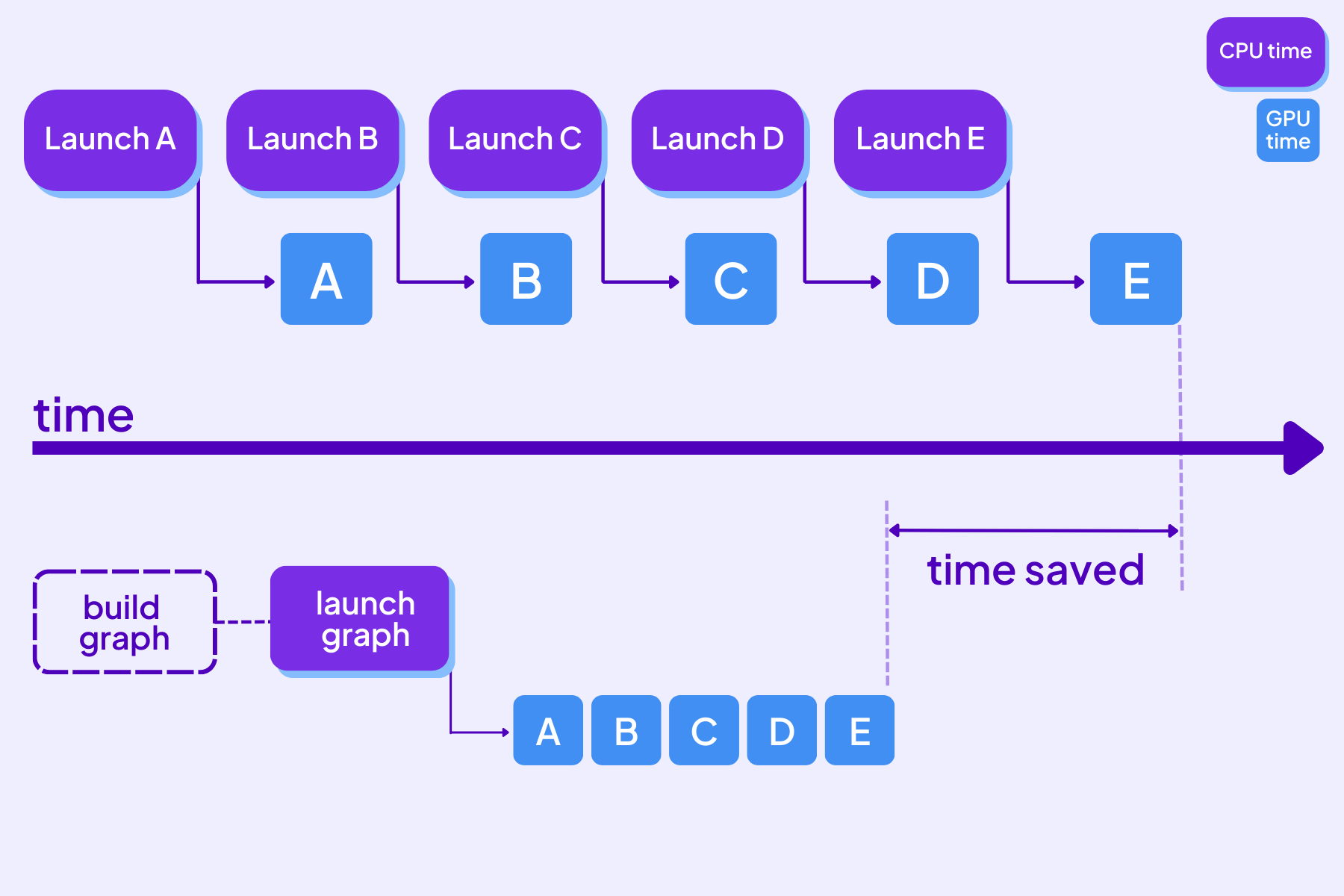
Benefits of using CUDA graphs.
If you’ve used TensorFlow before, this should look very familiar. We created placeholders and captured the static graph applied to them. In order to re-evaluate, you would need to copy the data in the placeholder.
Here’s how this works in 2 steps:
Step 1: Capture the PyTorch operations
# 1. Placeholders inputs used for capture
placeholder_input = torch.randn(N, D_in, device='cuda')
# 2. Capture operations
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
# some torch operations
placeholder_output = fn(static_input)
Step 2: Replay the graph
real_input = torch.rand_like(static_input)
static_input.copy_(data)
g.replay()
print(placeholder_output)
We applied this mechanism to the Clip Text Encoder, the U-Net, and VAE portions of the model. To learn more about the architecture of Stable Diffusion, you can read more in this article.
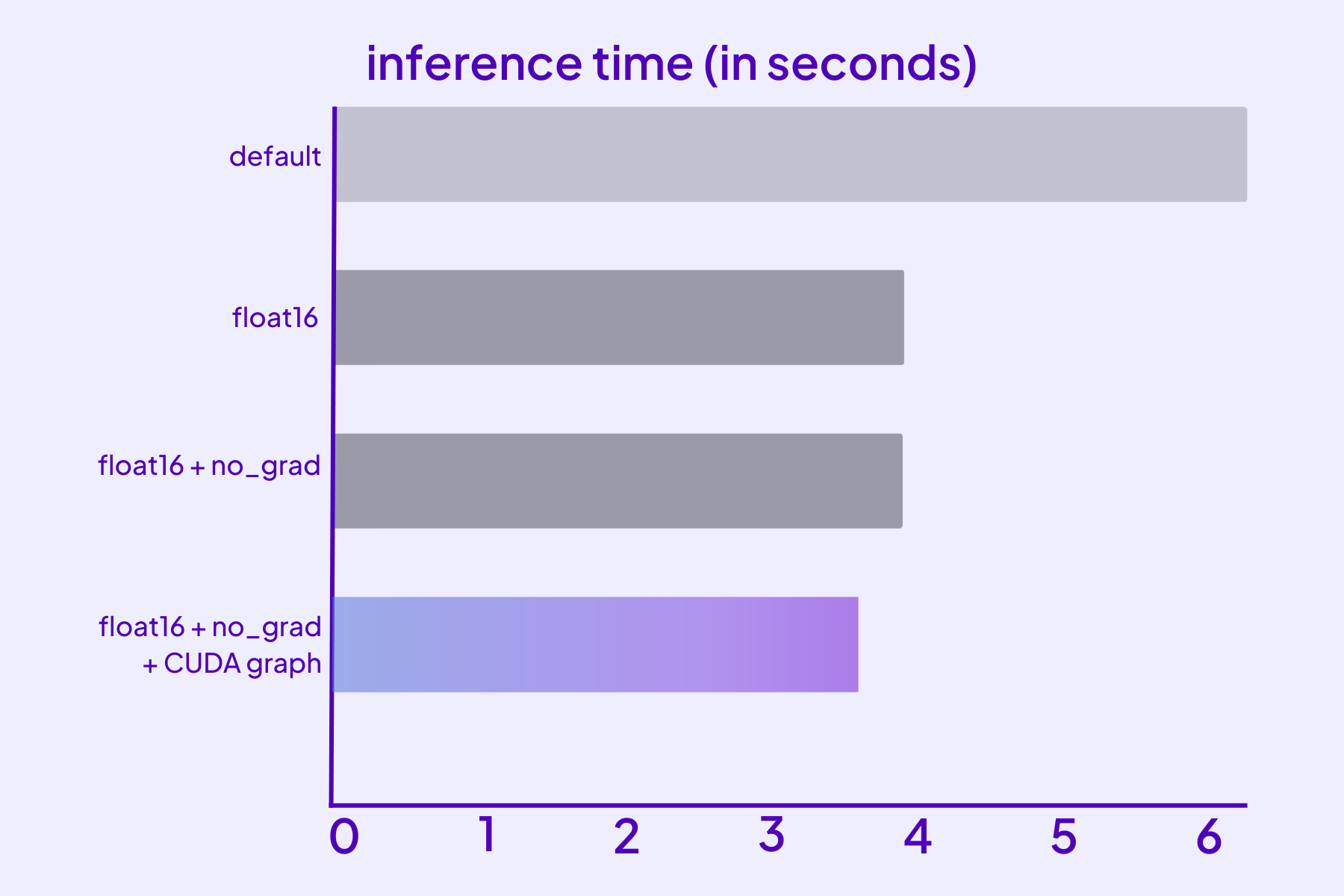
Inference speed with various optimizations. (warmed up over 5 inferences, results averaged over 10 inferences)
DeepSpeed Inference
DeepSpeed Inference
Using DeepSpeed Inference introduces several features to efficiently serve transformer-based PyTorch models with custom fused GPU kernels.Result: 44% gain in inference speed
Learn more with this tutorial.
We use DeepSpeed inference as follows:
import deepspeed
model = ...
# Initialize the DeepSpeed-Inference engine
ds_engine = deepspeed.init_inference(model, dtype=torch.half)
Behind the scenes, DeepSpeed Inference replaces any layers with their optimized versions if they match DeepSpeed internal registered layers. For example, only models from HuggingFace or Timm are already pre-registered and supported out-of-the-box by DeepSpeed Inference.
Because we’re using Stable Diffusion directly from its GitHub repo, we first need to replace the layers using the DeepSpeed optimized Transformer Layer.
from ldm.modules.attention import CrossAttention, BasicTransformerBlock
First, we replace CrossAttention from Stable Diffusion with DeepSpeed DeepSpeedDiffusersAttention. Here’s the code to do so:
from deepspeed.ops.transformer.inference.diffusers_attention import DeepSpeedDiffusersAttention
import deepspeed.ops.transformer as transformer_inference
def replace_attn(child, policy):
policy_attn = policy.attention(child)
qkvw, attn_ow, attn_ob, hidden_size, heads = policy_attn
config = transformer_inference.DeepSpeedInferenceConfig(
hidden_size=hidden_size,
heads=heads,
fp16=fp16,
triangular_masking=False,
max_out_tokens=4096,
)
attn_module = DeepSpeedDiffusersAttention(config)
def transpose(data):
data = data.contiguous()
data.reshape(-1).copy_(data.transpose(-1, -2).contiguous().reshape(-1))
data = data.reshape(data.shape[-1], data.shape[-2])
data.to(torch.cuda.current_device())
return data
attn_module.attn_qkvw.data = transpose(qkvw.data)
attn_module.attn_qkvb = None
attn_module.attn_ow.data = transpose(attn_ow.data)
attn_module.attn_ob.data.copy_(attn_ob.data.to(torch.cuda.current_device()))
return attn_module
Next, we replace the BasicTransformerBlock from Stable Diffusion with DeepSpeed DeepSpeedDiffusersTransformerBlock. Again, here’s the code to do so:
from deepspeed.ops.transformer.inference.diffusers_transformer_block import DeepSpeedDiffusersTransformerBloc
def replace_attn_block(child, policy):
config = Diffusers2DTransformerConfig()
return DeepSpeedDiffusersTransformerBlock(child, config)
Benchmarking
After performing these various optimizations, we visualized our results:
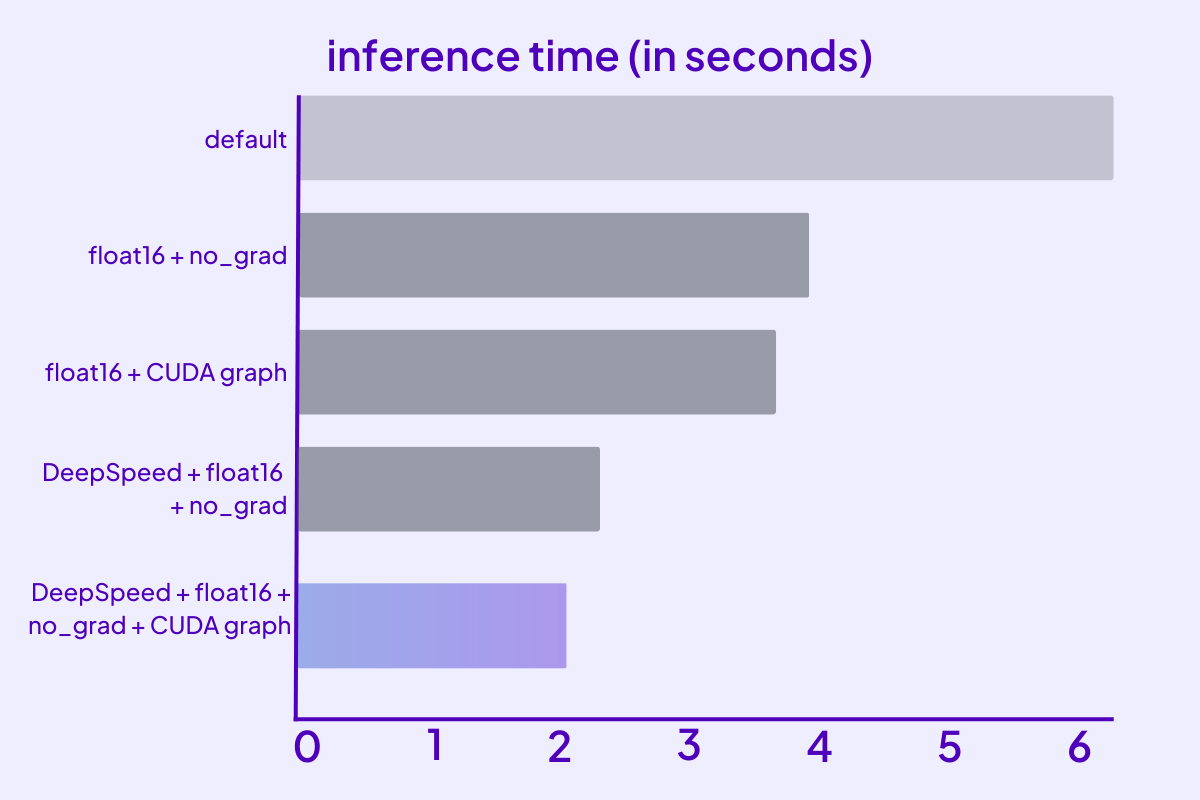
Improvements in inference time (seconds)
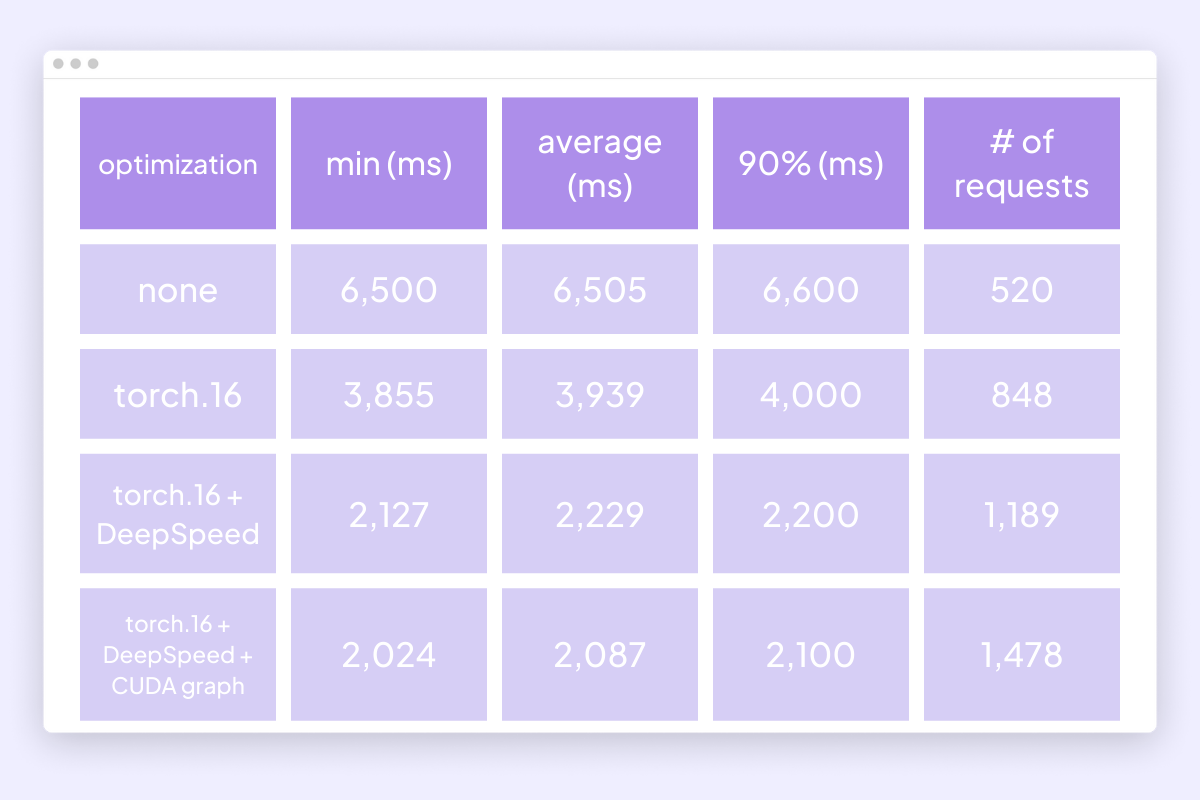
Optimization chart
Batching in Practice
Because CUDA graphs don’t support dynamic batch sizes, we didn’t account for these when we benchmarked across various batch sizes.
Here are the optimizations we performance according to batch size:
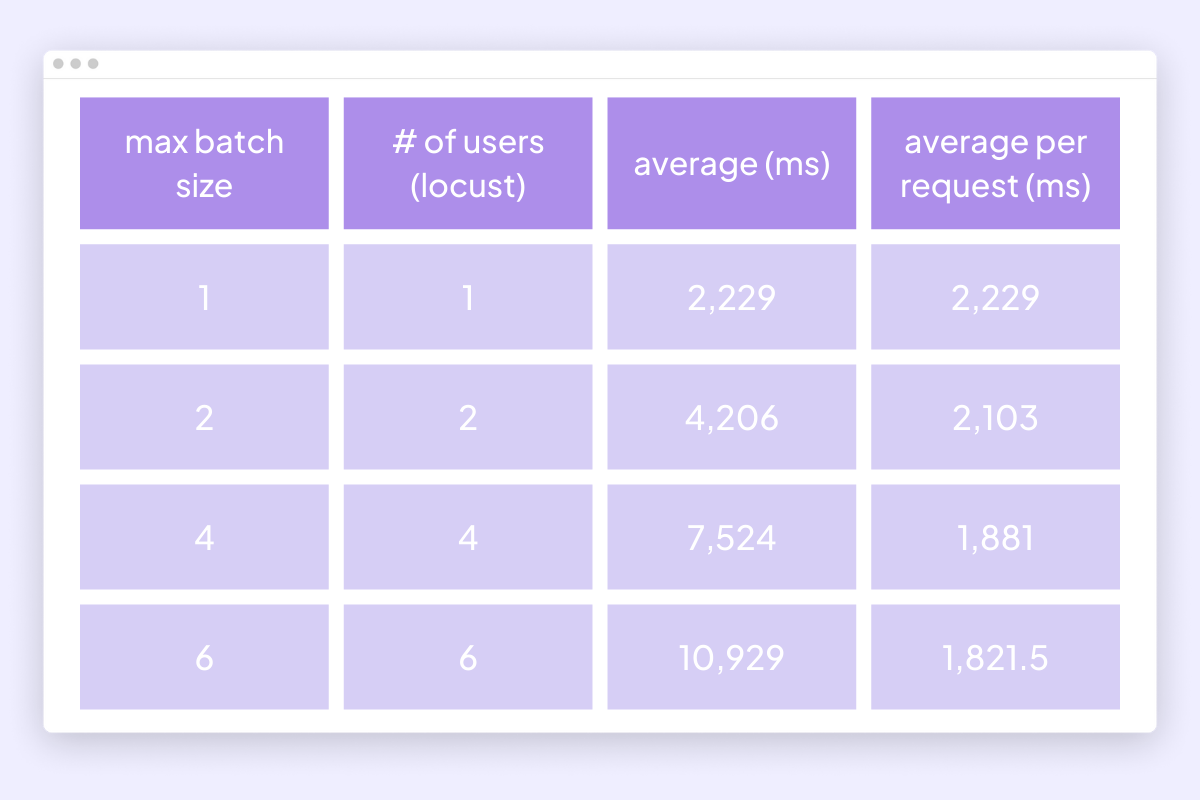
Optimizations according to batch size
These optimizations resulted in further inference speed improvements at larger batch sizes.
Conclusion
In this blog post, you learned how we leveraged several optimizations from PyTorch and DeepSpeed Inference to improve inference speed by over 300%.
In the future, we’d love to explore new ideas to even further improve inference time, such as dynamic batching on the U-Net or operators trace optimization. If you want to stay in the know about our latest improvements, join us on Discord or our Forums!
Benchmark this yourself!
To run your own benchmarks using these optimizations, just follow these three simple steps:
- Create a Lightning AI account and receive $30USD worth of free credits
- Duplicate (fork) our Autoscale Stable Diffusion Server on your account
- Navigate to our GitHub repo to replicate the benchmark.
