Key takeaways
How to scale model serving in production with dynamic batching and autoscaling.Get started with the Lightning Autoscaler
Serving large models in production with high concurrency and throughput is essential for businesses to respond quickly to users and be available to handle a large number of requests. Below, we share how we took advantage of Dynamic Batching and Autoscaling to serve Stable Diffusion in production and scaled it to handle over 1000 concurrent users.
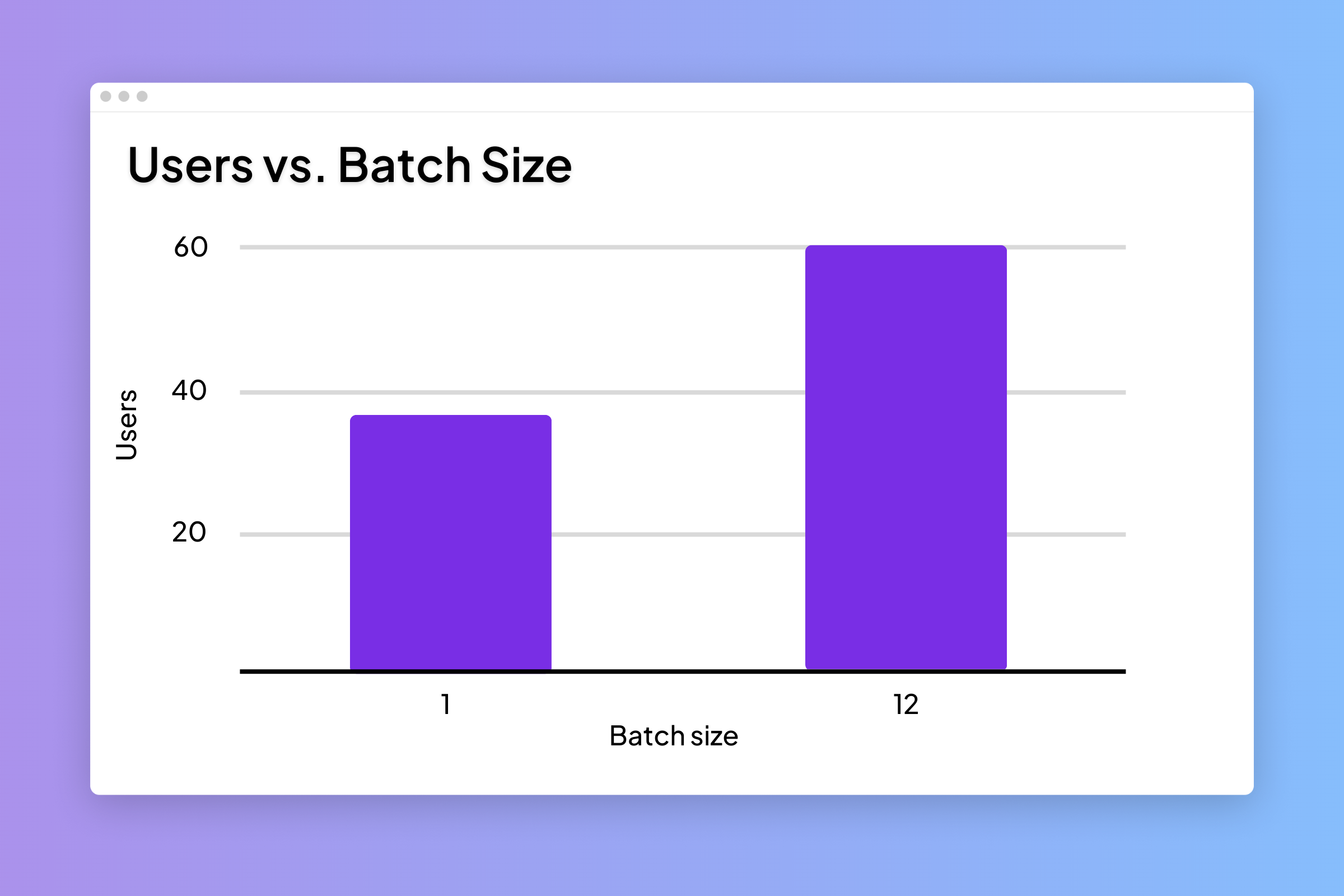
Throughput comparison with batch sizes 1 and 12.
Dynamic Batching
Batch processing increases the throughput or number of requests processed in a certain timeframe with some added latency. Dynamic batching is a method in which we aggregate requests and batch them for parallel processing. In our recent deployment of Stable Diffusion, we implemented a dynamic batching system that improved throughput by 50%. Before batching, we were able to handle ~30 concurrent users, and after enabling batching with a maximum batch size of 12, we were able to handle 60 concurrent users per process. The batch size can be finetuned based on the capability of your hardware.
To build a dynamic batching system, we took a consumer-publisher approach in which we continuously add incoming requests to a queue, and the queue items are consumed for model prediction in a background process This is technically a Python coroutine, but we’ll use the term ‘process’ for simplicity.. Once the prediction result is ready, the producer publishes the prediction to a
This is technically a Python coroutine, but we’ll use the term ‘process’ for simplicity.. Once the prediction result is ready, the producer publishes the prediction to a result dictionary and finally returns the generated image to the client.
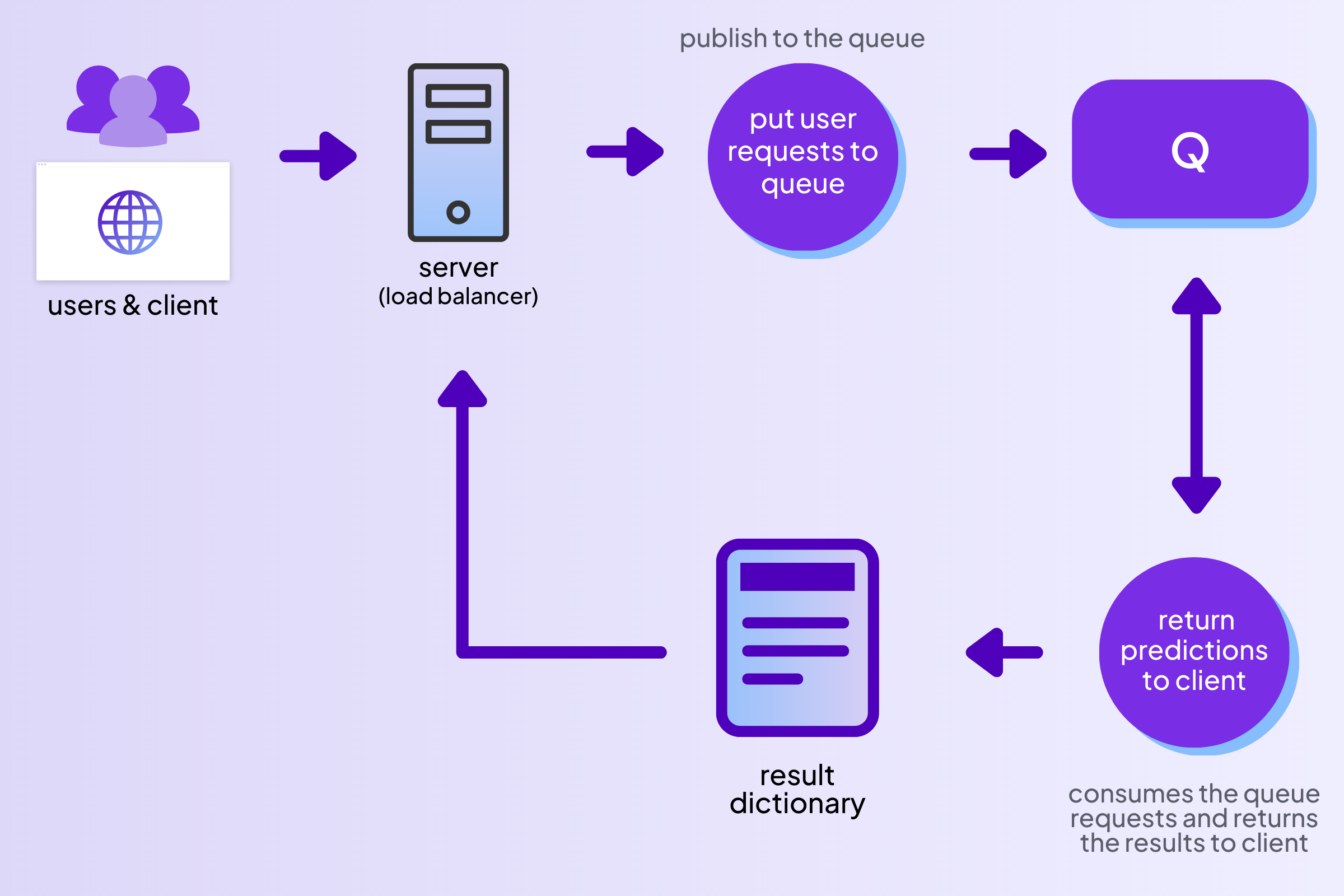
Fig. Flow of requests through the queue for batch aggregation
Autoscaling
With dynamic batching, concurrency is limited to the maximum batch size a model server can handle without running out of memory on the GPU.
We leveraged multiple GPUs by running the model server on each of the GPUs in parallel. We implemented an autoscaling feature that automatically increases the number of model servers with high traffic and downscales when traffic is idle. We are also able to configure a minimum number of servers that must be running at any given time.
To implement Autoscaling, we run a job every 30 seconds to check the traffic (defined as the number of current requests in the queue). Based on this traffic, we either upscale or downscale the model servers.
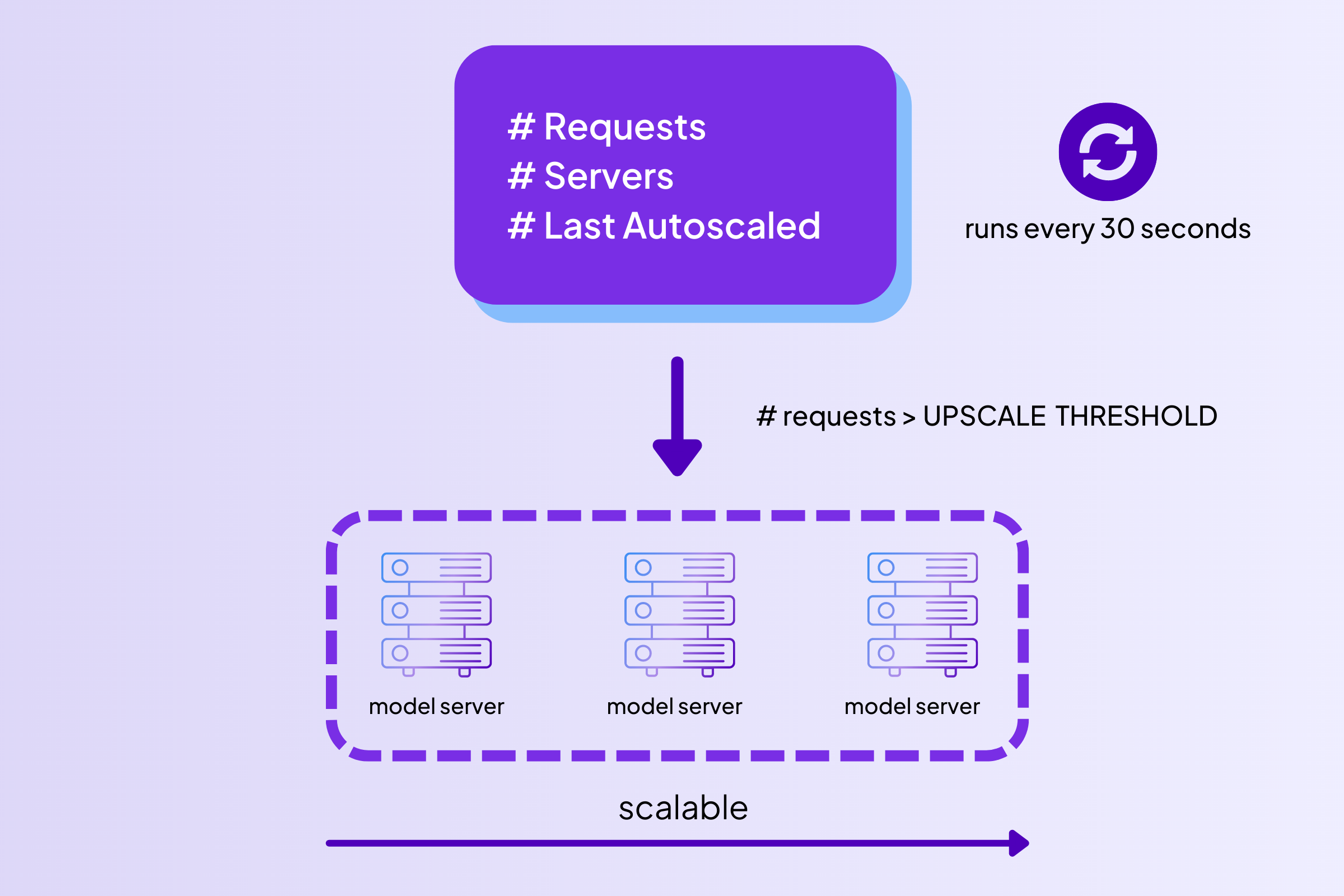
Fig. Autoscaling loops run after an interval to adjust the parallel servers.
Just by increasing the number of servers to 4, we scaled concurrency from 60 users to 400. This can be further upscaled to handle additional traffic.
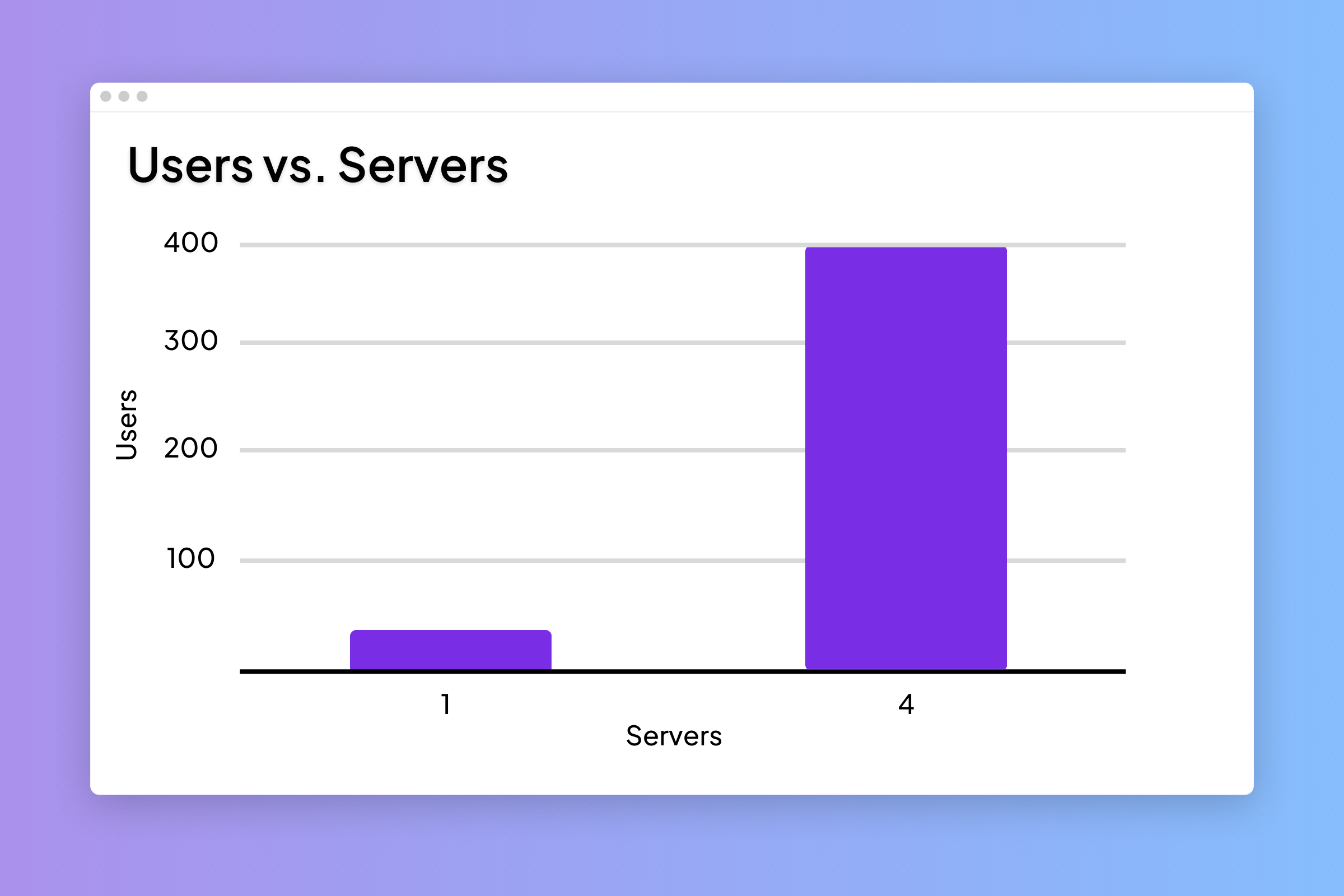
Fig. Overall throughput comparison with parallel servers at 1 and 4
Performance Testing
We ran the tests using Locust, an open-source performance testing library for Python, which we deployed as a component in our Lightning App. (Remember, a Lightning App is just organized Python code you can run anywhere, so adding this kind of third-party integration is simple!)
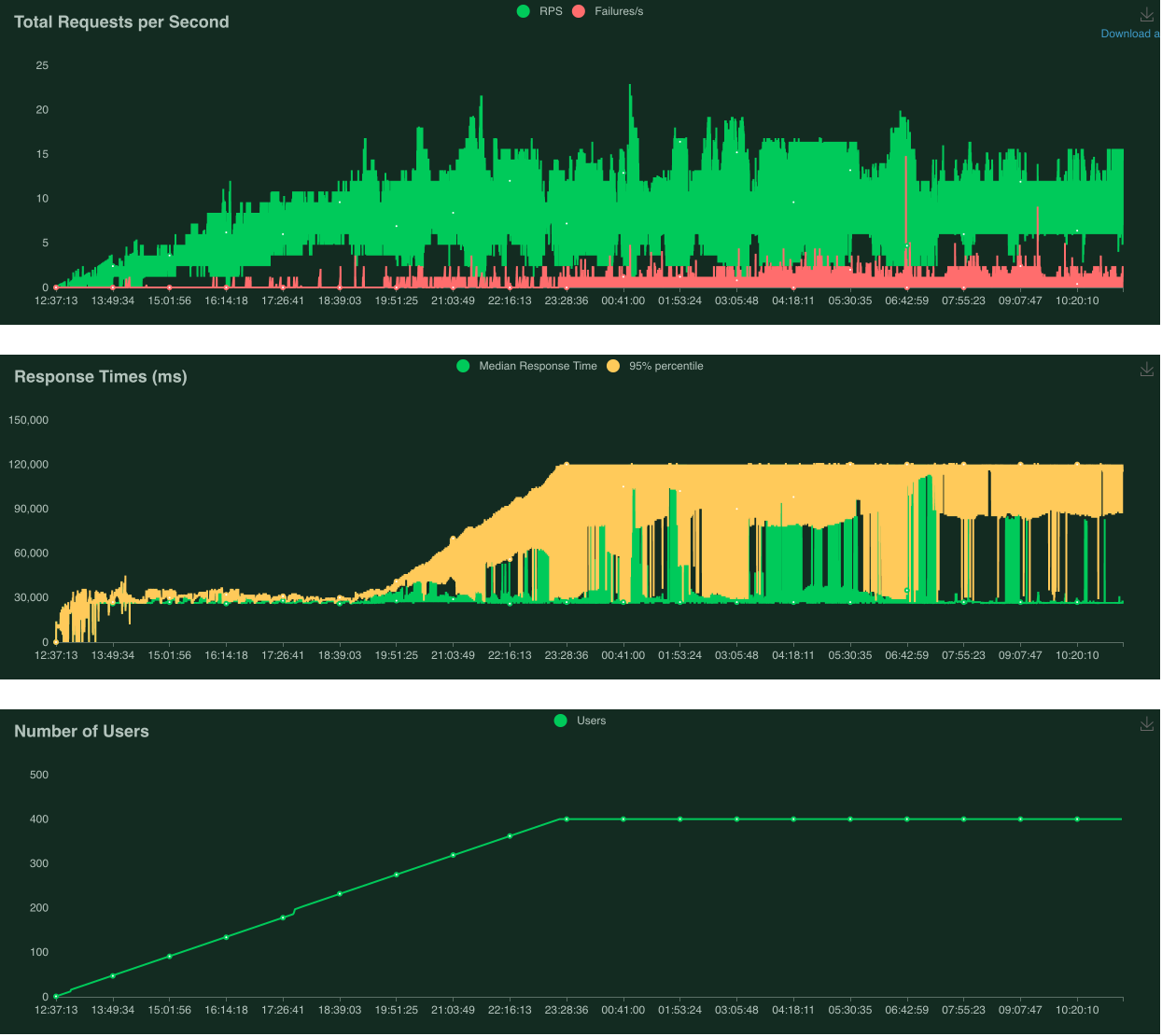
Fig. Performance testing chart
With the configuration of a maximum of 4 model servers and dynamic batching of size 12, we were able to increase the number of concurrent users this deployment could handle more than tenfold. With these techniques, we can easily increase the server to handle thousands of loads.
If you want to deploy your own Stable Diffusion server with a custom batch size and number of workers, you can clone the app from the App Gallery and run this command from your terminal:
lightning run app app.py --env MUSE_MIN_WORKERS=2 --env MUSE_GPU_TYPE=gpu-fast
Add autoscaling to your ML application with our open-source component!
Have questions about concurrency, latency, or other related topics? You can ask your questions in our community Slack or Forum. 💜
