Torchmetrics v1.2 is out now! The latest release includes 11 new metrics within a new subdomain: Clustering. In this blog post, we briefly explain what clustering is, why it’s a useful measure, and newly added metrics that can be used with code samples.
Clustering: What is it?
Clustering is an unsupervised learning technique. The term unsupervised here refers to the fact that we do not have ground truth targets as we do in classification. The primary goal of clustering is to discover hidden patterns or structures within data without having any prior knowledge about the data meaning or importance of particular features. Thus, clustering is a form of data exploration compared to supervised learning, where the goal is “just” to predict if a data point belongs to one class.
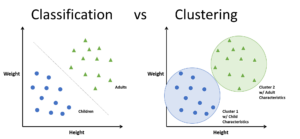
Clustering is, at a glance, closely related to classification; however, there are core differences. In classification, we know beforehand how many classes we are trying to model. For clustering, we do not. Figure from here.
The key goal of clustering algorithms is to split data into clusters/sets where data points from the same cluster are more similar to each other than any other points from the remaining clusters. Some of the most common and widely used clustering algorithms are K-Means, Hierarchical clustering, and Gaussian Mixture Models (GMM).
An objective quality evaluation/measure is required regardless of what clustering algorithm or internal optimization criterion is used. In general, we can divide all clustering metrics into two categories: extrinsic metrics and intrinsic metrics.
Extrinsic metrics
Extrinsic metrics are characterized by requirements of some kind of ground truth labeling, even if it is used for an unsupervised method. This may seem counter-intuitive at first as we, by clustering definition, do not use such ground truth labeling. However, most clustering algorithms are still developed on datasets that have labels available so these metrics use this fact as an advantage.
Takeaways
💡 NOTE: The core difference between extrinsic clustering metrics and classification metrics is that clustering metrics still allow for a different number of clusters in the ground truth labeling vs. the predicted labeling.In total, 8 of the 11 new clustering metrics fall into this category:
- Adjusted Mutual Information Score
- Adjusted Rand Score
- Completeness Score
- Homogeneity Score
- Mutual Information Score
- Normalized Mutual Information Score
- Rand Score
- V-Measure Score
The common signature for all these metrics is preds, and target. Both inputs are 1D tensors with predicted and target cluster labels. An example using the rand score can be seen below:
from torchmetrics.clustering import RandScore
import torch
preds = torch.tensor([2, 1, 0, 1, 0])
target = torch.tensor([0, 2, 1, 1, 0])
metric = RandScore()
print(metric(preds, target)) # tensor(0.6)Intrinsic metrics
In contrast, intrinsic metrics do not need any ground truth information. These metrics estimate inter-cluster consistency (cohesion of all points assigned to a single set) compared to other clusters (separation). This is often done by comparing the distance in the embedding space.
There are three these metrics in the new Torchmetrics release:
Common for all these metrics is that they take two inputs: data and labels. The data is a (N,d) matrix containing a d-dimensional embedding per datapoint, and labels are (N,) shaped vectors containing predicted labels.
from torchmetrics.clustering import DunnIndex
import torch
data = torch.tensor([[0, 0], [0.5, 0], [1, 0], [0.5, 1]])
labels = torch.tensor([0, 0, 0, 1])
dunn_index = DunnIndex(p=2)
print(dunn_index(data, labels)) # tensor(2.0)Update to Mean Average Precision
MeanAveragePrecision, the most widely used metric for object detection in computer vision, now supports two new arguments: average and backend.
The average argument controls how averaging is done over multiple classes. By the core definition, the default way to do so is macro averaging where the metric is calculated for each class separately and then averaged together. This will continue to be the default in Torchmetrics, but now we also support the setting average="micro" . Every object under this setting is essentially considered to be the same class, and the returned value is therefore calculated simultaneously over all objects.
The second argument backend is important, as it indicates what computational backend will be used for the internal computations. Since MeanAveragePrecision is not a simple metric to compute, and we value the correctness of our metric, we rely on some third-party library to do the internal computations. By default, we rely on users to have the official pycocotools installed, but with the new argument, we will also be supporting other backends.
To begin with, we will be supporting the faster-coco-eval which is both faster than the original official implementation but also fixes some corner cases. In the future we hope to support more backends, in particular a pure PyTorch based implementation.
Other Bugfixes
Since Torchmetrics v1.1, there have been two small bugfix releases v1.1.1 and v1.1.2.
MetricCollectionhas been fixed for cases where the collection contained multiple metrics that returned dictionaries that contained the same keyword. Before v1.2, this was not correctly identified, an only the results of the last metric were returned. This has been fixed in v1.2 such that keywords are now appended a prefix if duplicates exist.- The
higher_is_betterandis_differentiableattributes that all metrics (should) have, for respectively determining if a metric is optimal when minimized or maximized and if it is differentiable, have now been added to metrics that were missing the attributes or, in some cases, they where incorrectly set. BootStrapperfrom wrappers,PearsonCorrCoeffrom regression, andRecallAtFixedPrecisionfrom classification have all gotten small bugfixes.
We always recommend upgrading to the latest Torchmetrics release. Please refer to our changelog for the full overview of newly added features, changes, deprecations, and bug fixes.
Thank you!
As always, we offer a big thank you to all of our community members for their contributions and feedback. Please open an issue in the repo if you have any recommendations for the next metrics we should tackle.
We are happy to see the continued adoption of TorchMetrics in over 2,400 projects, and we are proud to release that we have passed 1,600 GitHub stars.
If you want to ask a question or join us in expanding Torchmetrics, please join our discord server, where you can ask questions and get guidance in the #torchmetrics channel.
🔥 Check out the documentation and code! 🚀