←
Back
to glossary
LoRA
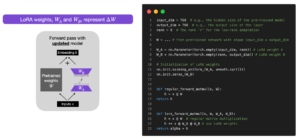
LoRA achieves parameter reduction in large language models by learning rank-decomposition matrices in conjunction with freezing the original weights. This significantly diminishes storage needs for task-specific adaptations, facilitates efficient task-switching during deployment without introducing inference latency, and exhibits superior performance compared to other adaptation methods like adapter, prefix-tuning, and fine-tuning.