Key Takeaways
Learn how you can use Lightning to build a model training and deployment pipeline that is customizable, integrated with tools (like monitoring, data warehouses, and feature stores), and deployed in production.MLOps is essential for companies both large and small that build products and services powered by AI. Given the wide variety of tools and platforms that aim to solve different parts of the machine learning lifecycle, choosing between them isn’t always easy. Building a machine learning training and deployment pipeline is a fractured experience from the get-go.
Below, we’ll go through Lightning’s unified platform for training and deploying machine learning models in production.
What is Lightning?
Lightning (by the same people who built PyTorch Lightning) is a platform that augments the capabilities of PyTorch Lightning beyond training, into serving, deploying, monitoring, and data engineering. The user-centric Lightning Trainer already made distributed training simple and gave users control over their hardware selection. Lightning was built with these same principles in mind, giving researchers and practitioners full flexibility over their work while also abstracting away complex cloud infrastructure.
Lightning is designed around the Lightning App framework, an open-source library that enables you to build and run distributed Pythonic applications. With just a few extra flags in your CLI, you can run that Python code on your local system, the Lightning Cloud (backed by AWS), or even your own private cluster Got AWS credits kicking around? 😉 with minimal friction. Lightning brings the same robust simplicity for which PyTorch Lightning is loved to our fully-managed cloud service.
Got AWS credits kicking around? 😉 with minimal friction. Lightning brings the same robust simplicity for which PyTorch Lightning is loved to our fully-managed cloud service.
Is this the fastest way to build an ML pipeline?
We think so! For instance, you control infrastructure provisioning with the Lightning CloudCompute Python API. Anyone from your machine learning team can then customize and manage the infrastructure without needing expertise in cloud computing. This again removes the friction and dependency delay on cloud engineers, which is a time-consuming process for most organizations.
Lightning APIs
In the following section, we’ll go through the core Lightning APIsLightningWork and LightningFlow as well as some examples of them in use.
LightningWork
This is the building block for long-running jobs like model training, serving, and ETL.
LightningWork gives users the flexibility to customize machine configurations like RAM, CPU/GPU, and disk allocation.
Here’s an example of how you can create an Nvidia T4 GPU machine with a 50 GB disk size and add PyTorch and FastAPI as dependency requirements:
Lightning will automatically spawn a GPU machine with the specified disk size and install the necessary requirements for you. LightningWork runs on a separate machine on the cloud and a separate process on the local system.
You can run any kind of process with LightningWork. Here are some use cases:
- Model Training
- Model Deployment
- Model Demo with Gradio or Streamlit
- ETL Pipeline
Here’s a more complex example that deploys an image classification model using the PythonServer component:
LightningFlow
This is used to manage multiple LightningWorks — those long-running jobs we mentioned above. The children of a Flow can be other Flows or a Work.
The execution of a Flow begins with the run(...) method, which will run forever in a loop.
A full-scale machine learning application can thus be composed of Flows and Works, where the Works run the computationally heavy script which is managed by the Flows.
For example, a training and deployment application where we train a machine learning model and then deploy it might look like this:
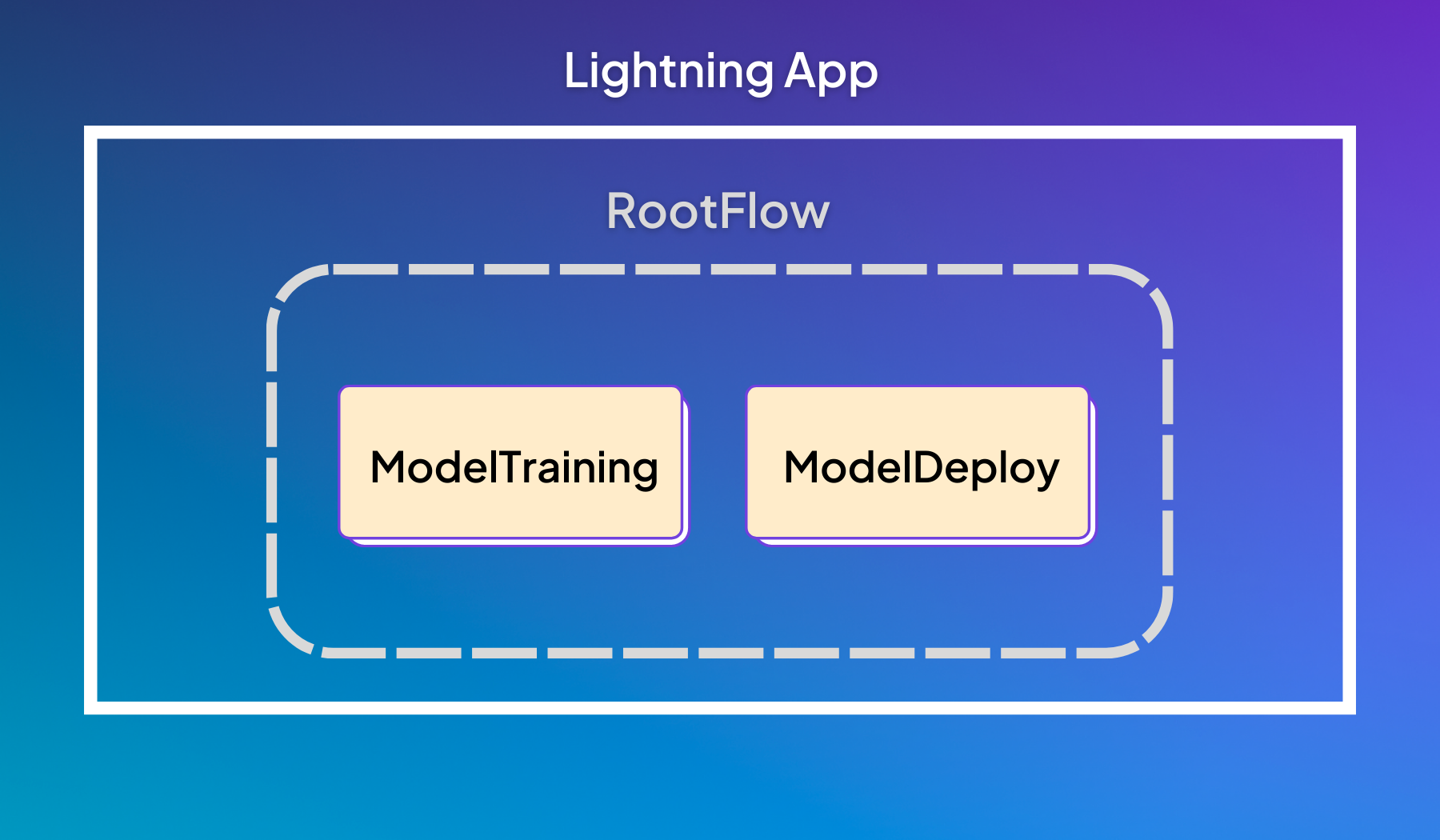
Example app with a RootFlow that contains a training and deployment step.
The Lightning App above is composed of a RootFlow which contains two works: ModelTraining and ModelDeploy. As the scope of your machine learning system increases, you can add extra components to the RootFlow like Drift detection and model monitoring.
The RootFlow is a LightningFlow with two LightningWork children. The run(...) method defines how this app will be executed. In this example, we’ll train the model first and then deploy it:
Because the ModelTraining class is a LightningWork, we execute the training in the run method:
Similarly, the ModelDeploy class is also a LightningWork:
In this application, let’s say I want to train my model on a GPU but deploy it on a CPU machine. Lightning makes this process trivial:
To run this Lightning App, you need to wrap the RootFlow inside L.LightningApp and run lightning run app app.py from your terminal. To deploy this on the cloud, all you need to do is add the --cloud flag and run the command lightning run app app.py --cloud.
Wrap up
If you’ve been following these steps, you’re ready to train and deploy machine learning models in production. As a next step, you can add more functionality to your pipelines like autoscaling, dynamic batching, hyperparameter optimization, and drift detection. Lightning gives you full flexibility to run any Python code wherever you want — that’s what we call a Lightning App.
To learn more about training machine learning models on the cloud or building production machine learning systems, check out our documentation!
