Takeaways
Learn how to build and train a Reinforcement Learning model with PyTorch and Lightning Fabric. You will also create and train a Reinforcement Learning agent to play a game in a simulated environment using Proximal Policy Optimization (PPO) algorithm. Based on the contribution hereAbout the Author
Federico is currently working as Data Scientist at Orobix, a front-runner in the AI industry in Italy, where he not only solves complex, real-world problems but also effectively bridges the gap between theory and application. With 3.5 years of rich experience in the fields of Computer Vision, with an emphasis on Self-Supervised Learning, segmentation, and classification, and Reinforcement Learning, his work consistently aims to push the envelope in terms of what AI can achieve in the industry.
Introduction to Reinforcement Learning
Reinforcement Learning (RL) is a type of machine learning algorithm that trains intelligent agents to make decisions by interacting with an environment and adapting their behavior to maximize a certain goal over time. It is inspired by how humans and animals learn from their experiences and adjust their actions accordingly.
Reinforcement learning has been extremely successful in various applications, including robotics, autonomous vehicles, recommendation systems, and game-playing. One of the most famous examples is AlphaGo, an AI system developed by DeepMind. It combined reinforcement learning with deep neural networks to defeat the world champion Go player. Go is a strategy board game for two players that was invented in China more than 2500 years ago. There are almost 2×10170 possible legal board positions, and the game is played on a 19×19 board. The aim is to surround more territory than the opponent.
Components of reinforcement learning
- Agent: The agent is the entity (e.g., an AI algorithm or a robot) that learns and makes decisions based on its interactions with the environment.
- Environment: The environment represents the external context or the world in which the agent operates. It can be as simple as a 2D Tic-Tac-Toe grid or as complex as the real world.
- States: A state is a snapshot of the environment at a given point in time and represents what the agent perceives. It provides the agent with the necessary information to make decisions.
- Actions: Actions are the set of possible moves or choices the agent can make in a given state. The agent’s objective is to choose the most appropriate action based on its current understanding of the environment.
- Rewards: Rewards are the feedback the agent receives from the environment after performing an action. They indicate how well the agent is doing in achieving its goal. The agent’s objective is to learn a strategy that maximizes the cumulative reward over time.
The high-level representation is shown in the following figure:

In the above figure, time is discretized and represented by t, the agent interacts with the environment. The agent receives an observation from the environment, which represents the state of the environment at that point in time. The agent then performs an action based on that state and receives a reward in return. The reward is a scalar value that indicates how good or bad the action was with respect to the particular goal or task that the agent is trying to achieve.
Journey with PyTorch for Reinforcement Learning
Orobix, an AI company from Italy, worked with a video game company to develop an RL framework. The goal is to improve the racing performance of non-player characters (NPCs) in the game. This collaboration aims to create a more competitive and immersive experience.
The framework was built from scratch to allow us to have full flexibility over the training loop and the distributed training infrastructure.
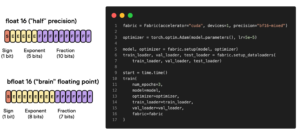
We needed manual control over distributed training, half-precision, and every part of the code to make it more flexible. Fabric, a new library launched by Lightning AI (formerly PyTorch Lightning) team, stepped our way. It helped us give full flexibility over the custom training loop and at the same time abstract multiple devices, distributed and half-precision training.
Fabric-accelerated Reinforcement Learning
Now we will build and train an RL agent to play in a CartPole environment, where a pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. This agent is based on the Proximal Policy Optimization (PPO) algorithm. The objective is to balance the pole by applying forces in the left and right direction on the cart:

What’s needed
We need to install the following libraries:
- Gymnasium: a standard API for reinforcement learning containing a diverse collection of reference environments
- Fabric: used to accelerate and distribute our training
The complete list of requirements can be looked up here.
Environment coupled with the Agent
Let’s first understand when environment is coupled with the agent. The main idea is depicted in the following figure:

where we will spawn N+1 processes, called rank-0, …, rank-N; every process contains both the environment (possibly multiple, M+1 in the above figure, and different copies) and the agent: they are coupled together in the same process.
Let us first define our main(...) function where we will initialize the distributed training settings using Fabric.
from lightning.fabric import Fabric
def main(args):
# Initialize Fabric
fabric = Fabric()
rank = fabric.global_rank # The rank of the current process
world_size = fabric.world_size # Number of processes spawned
device = fabric.device
fabric.seed_everything(42) # We seed everything for reproduciability purpose
Next, we create the environment using gymnasium. First, we define a helper function make_env that creates a single environment.
def make_env(env_id: str, seed: int, idx: int, capture_video: bool, run_name: Optional[str] = None, prefix: str = ""):
def thunk():
env = gym.make(env_id, render_mode="rgb_array")
env = gym.wrappers.RecordEpisodeStatistics(env)
if capture_video:
if idx == 0 and run_name is not None:
env = gym.wrappers.RecordVideo(
env, os.path.join(run_name, prefix + "_videos" if prefix else "videos"), disable_logger=True
)
env.action_space.seed(seed)
env.observation_space.seed(seed)
return env
return thunk
Now, we will create a pool of parallel synchronized environments through the SyncVectorEnv object using the make_env function we just created.
import gymnasium as gym
# given an initial seed of 42 and 4 environments per rank, then
# rank-0 will seed the environments with --> 42, 43, 44, 45
# rank-1 will seed the environments with --> 46, 47, 48, 49
# and so on
rl_environment = gym.vector.SyncVectorEnv([
make_env(
args.env_id,
args.seed + rank * args.num_envs + i,
rank,
args.capture_video,
logger.log_dir,
"train"
)
for i in range(args.num_envs)
])
In the last step, we create the agent, optimizer and integrate it with Fabric for faster training.
We have defined PPOLightningAgent, a LightningModule, which is an Actor-Critic agent. In Actor Critic Agent, the actor proposes a set of possible actions in a given state, and the critic evaluates actions taken by the actor.
agent = PPOLightningAgent(
rl_environment,
act_fun=args.activation_function,
vf_coef=args.vf_coef,
ent_coef=args.ent_coef,
clip_coef=args.clip_coef,
clip_vloss=args.clip_vloss,
ortho_init=args.ortho_init,
normalize_advantages=args.normalize_advantages,
)
optimizer = agent.configure_optimizers(args.learning_rate)
# accelerated training with Fabric
agent, optimizer = fabric.setup(agent, optimizer)
Now we need to create the “infinite” loop in which:
- the agent collects experiences interacting with the environment, where a single experience is composed by $$(\text{observation}_t, \text{reward}_t, \text{action}_t, \text{done}_t)$$, where the $$\text{done}_t$$ is a boolean flag indicating whether the game has finished or not. The agent collects experiences until the game terminates or a predefined number of steps has been played.
- given the collected experiences, train the agent to improve its behaviour
- repeat from step 1 until convergence or a maximum number of interactions with environment has been reached
The experience-collecting loop is the following:
import torch
with fabric.device:
# with fabric.device is only supported in PyTorch 2.x+
obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape)
actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape)
rewards = torch.zeros((args.num_steps, args.num_envs))
dones = torch.zeros((args.num_steps, args.num_envs))
# Log-probabilities of the action played are needed later on during the training phase
logprobs = torch.zeros((args.num_steps, args.num_envs))
# The same happens for the critic values
values = torch.zeros((args.num_steps, args.num_envs))
# Global variables
global_step = 0
single_global_rollout = int(args.num_envs * args.num_steps * world_size)
num_updates = args.total_timesteps // single_global_rollout
with fabric.device:
# Get the first environment observation and start the optimization
next_obs = torch.tensor(envs.reset(seed=args.seed)[0])
next_done = torch.zeros(args.num_envs)
# Collect `num_steps` experiences `num_updates` times
for update in range(1, num_updates + 1):
# Learning rate annealing
if args.anneal_lr:
linear_annealing(optimizer, update, num_updates, args.learning_rate)
for step in range(0, args.num_steps):
global_step += args.num_envs * world_size
obs[step] = next_obs
dones[step] = next_done
# Sample an action given the observation received by the environment
with torch.no_grad():
action, logprob, _, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten()
actions[step] = action
logprobs[step] = logprob
# Single environment step
next_obs, reward, done, truncated, info = envs.step(action.cpu().numpy())
# Check whether the game has finished or not
done = torch.logical_or(torch.tensor(done), torch.tensor(truncated))
with fabric.device:
rewards[step] = torch.tensor(reward).view(-1)
next_obs, next_done = torch.tensor(next_obs), done
To train both the actor and the critic we need to estimates returns and advantages:
- the advantage describes how much better it is to take a specific action $$a$$ in state $$s$$, over randomly selecting an action according to the actor
- the return is the sum of discounted rewards received by the environments: $$G_t=\sum_{t=t’}^{T}\gamma^{t-t’}r_t$$, where $$y \in (0,1)$$ is the discount factor. Intuitively, the return simply implies that rewards now are better than rewards later
# Estimate advantages and returns with GAE ()
returns, advantages = agent.estimate_returns_and_advantages(
rewards, values, dones, next_obs, next_done, args.num_steps, args.gamma, args.gae_lambda
)
We are now finally able to train the agent:
# Flatten the batch
local_data = {
"obs": obs.reshape((-1,) + envs.single_observation_space.shape),
"logprobs": logprobs.reshape(-1),
"actions": actions.reshape((-1,) + envs.single_action_space.shape),
"advantages": advantages.reshape(-1),
"returns": returns.reshape(-1),
"values": values.reshape(-1),
}
# Train the agent
train(fabric, agent, optimizer, local_data, global_step, args)
from torch.utils.data import BatchSampler, RandomSampler
def train(
fabric: Fabric,
agent: PPOLightningAgent,
optimizer: torch.optim.Optimizer,
data: Dict[str, Tensor],
global_step: int,
args: argparse.Namespace,
):
sampler = RandomSampler(list(range(data["obs"].shape[0])))
sampler = BatchSampler(sampler, batch_size=args.per_rank_batch_size, drop_last=False)
for _ in range(args.update_epochs):
for batch_idxes in sampler:
loss = agent.training_step({k: v[batch_idxes] for k, v in data.items()})
optimizer.zero_grad(set_to_none=True)
fabric.backward(loss)
fabric.clip_gradients(agent, optimizer, max_norm=args.max_grad_norm)
optimizer.step()
agent.on_train_epoch_end(global_step)
For more detailed information on the complete training step of the agent, please refer to this link.
As we have witnessed, there is no boilerplate code required for distributed training; Fabric abstracts that process for us. To train our agent in a distributed way, simply execute the following command:
lightning run model \
--accelerator=gpu \
--strategy=ddp \
--devices=2 \
train_fabric.py \
--capture-video \
--env-id CartPole-v1 \
--total-timesteps 100000 \
--num-envs 2 \
--num-steps 512
The trained agent should then play the game like the following:

Conclusion
Reinforcement learning is a powerful machine learning technique that enables agents to learn from their experiences and improve their decision-making capabilities over time. It has the potential to revolutionize various industries and contribute to the development of more intelligent and adaptive AI systems.
In this blog-post we have briefly introduced the high-level concepts of Reinforcement Learning and showcase how to train an agent to play optimally the Cart-Pole game and thanks to Fabric we were able to accelerate the training without boilerplate code.