What Is Distributed Training?
Key takeaways
In this tutorial, you’ll learn how to scale models and data across multiple devices using distributed training.The GPU is the most popular choice of device for rapid deep learning research. This is a direct result of the speed, optimizations, and ease of use that these frameworks offer. From PyTorch to TensorFlow, support for GPUs is built into all of today’s major deep learning frameworks. Thankfully, running experiments on a single GPU does not currently require many changes to your code. As models continue to increase in size, however, and as the data needed to train them grows exponentially, running on a single GPU begins to pose severe limitations. Whether it’s running out of memory or dealing with slow training speeds, researchers have developed strategies to overcome the limitations posed by single-GPU training. In this tutorial, we’ll cover how to use distributed training to scale your research to multiple GPUs.
With Lightning Trainer, scaling your research to multiple GPUs is easy. Even better – if a server full of GPUs isn’t enough, you can train on multiple servers (also called nodes) in parallel. Lightning takes care of this by abstracting away boilerplate code, leaving you to focus on the research you actually care about. Under the hood, Lightning is modular, meaning it can adapt to whatever environment you are running in (for example, a multi-GPU cluster).
Below, we provide a theoretical overview of distributed deep learning, and then cover how Distributed Data Parallel (DDP) works internally.
· · ·
When Do I Need Distributed Training?
Distributed training is a method that enables you to scale models and data to multiple devices for parallel execution. It generally yields a linear increase in speed that grows according to the number of GPUs involved.
Distributed training is useful when you:
- Need to speed up training because you have a large amount of data.
- Work with large batch sizes that cannot fit into the memory of a single GPU.
- Have a large model parameter count that doesn’t fit into the memory of a single GPU.
- Have a stack of GPUs at your disposal. (wouldn’t that be nice?)
The first two of these cases, speeding up training and large batch sizes, can be addressed by a DDP approach where the data is split evenly across all devices. It is the most common use of multi-GPU and multi-node training today, and is the main focus of this tutorial.
The third case (large model parameter count) is becoming increasingly common, particularly as models like GPT-3, BERT, and Stable Diffusion grow in size exponentially. With billions of parameters, these models are too large to fit into a single multi-GPU machine. In other words, without distributed training, these models wouldn’t exist.
· · ·
How Does Distributed Training Work?
In order to understand distributed training, it is essential to understand that the optimization in a distributed setting does not change when compared to a single-device setting. We minimize the same cost function with the same model and optimizer.
The difference is that the data gets split into multiple devices, which leads to a reduced batch size per GPU. Gradient computation thus does not create any memory overhead and runs in parallel. This works because of the linearity of the gradient operator: computing the gradient for individual data samples and then averaging them is the same as computing the gradient using the whole batch of data at once on a single device.
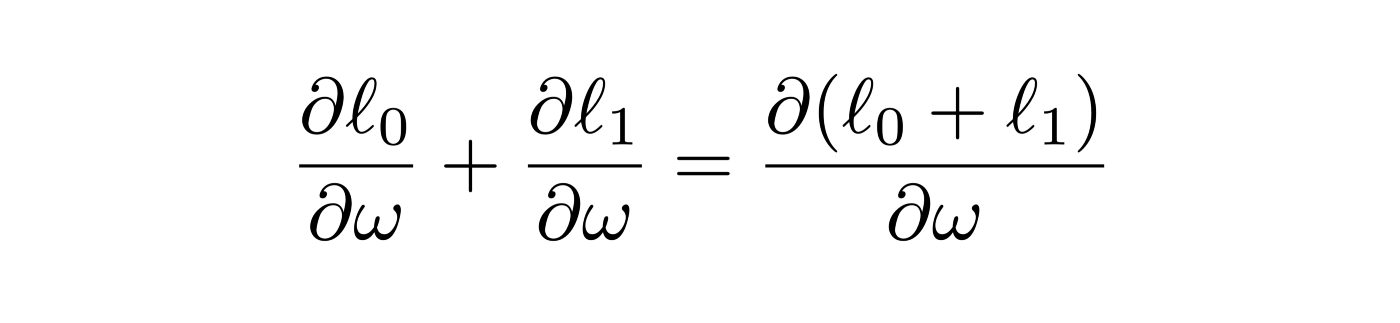
Linearity: The sum of the gradients computed in each node is the same as the gradient of the combined cost function computed on one node.
Step 1
We start with the same copy model weights on all devices (handled by PyTorch’s DistributedDataParallel). Each device gets its split of the data batch (handled by PyTorch’s DistributedSampler) and performs a forward pass. This yields a different loss value per device.
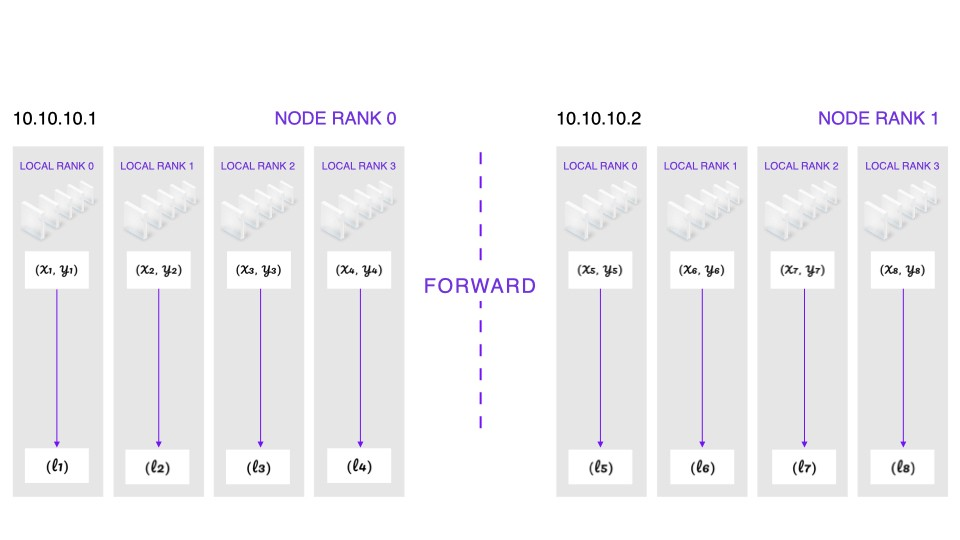
Forward: Each device holds the same model weights but gets different data samples. Each device independently computes a loss value for that batch of data.
Step 2
Given the loss value, we can perform the backward pass, which computes the gradients of the loss with regard to the model weights. We now have a different gradient per GPU device.
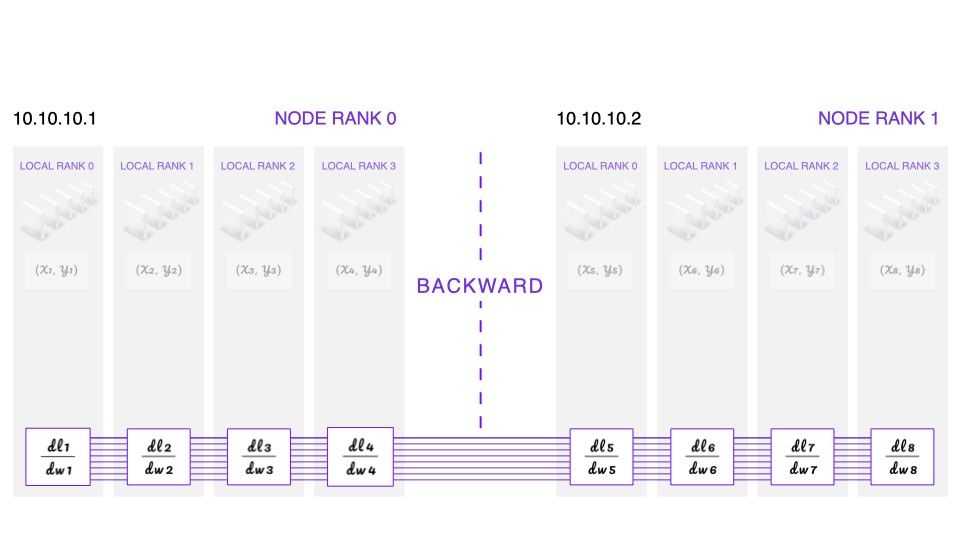
Backward: Each device computes gradients independently. The gradients get averaged, and all devices receive the same averaged gradients for the weight update
Step 3
We synchronize the gradients by summing them up and dividing them by the number of GPU devices involved. Note that this happens during the backward pass. At the end of this process, each GPU now has the same averaged gradients.
Step 4
Finally, all models can update their weights with the synchronized gradient. Because the gradient is the same on all GPUs, we again end up with the same model weights on all devices, and the next training step can begin.
· · ·
Challenges with DDP
Splitting data evenly across multiple devices is done using the DistributedSampler. To balance the workload for all GPU workers and avoid synchronization issues, this strategy inserts duplicated samples if the size of the dataset is not evenly divisible by the number of GPUs and batch size. Lightning takes care of all of this automatically. However, during testing/evaluation, duplicated samples can lead to incorrect metrics (test accuracy). Lightning is currently working on an “uneven” DDP feature to alleviate this shortcoming in the future.
If you need to sync metrics across devices like gradients, this creates a communication overhead that can slow down the process. If you are interested in syncing those metrics easily, you can try torchmetrics.
If processes get stuck (a subset hangs or errors), you might end up with zombie processes and have to kill them manually. Lightning has a mechanism to detect deadlocks and will exit all processes after a specific timeout.
Key Points to Note
Only gradients are synced across devices to update the model weights. No other metrics or loss is synced by default. Although you can do that using all_reduce, which we will learn about in the next blog.
DDP splits the data, not the model weights. So if your model can’t be loaded by one GPU, DDP can’t help here. You need to adopt more advanced strategies, such as DeepSpeed or Sharding, which we will discuss in the following blog posts.
We recommend using DDP over DataParallel. You can read more about why here.
Further Reading
- PyTorch Distributed by Shen Li (tech lead for PyTorch Distributed team)
