Key Takeaway
Learn how to accelerate serving models with sequential inference steps, like Stable Diffusion.In this blog post, we demonstrate how we accelerated our serving of diffusion models by up to 18% for higher batch sizes and cover how to leverage expressive Lightning systems to design a new serving strategy for diffusion models.
What are diffusion models?
In Denoising Diffusion Probabilistic Models (2020), Jonathan Ho et al. introduce a new diffusion probabilistic model with a sampling strategy called DDPM. During training, random Gaussian noise is added gradually to the input image (the signal is destroyed) and the model is trained to predict the noise added to the image to recover the original image.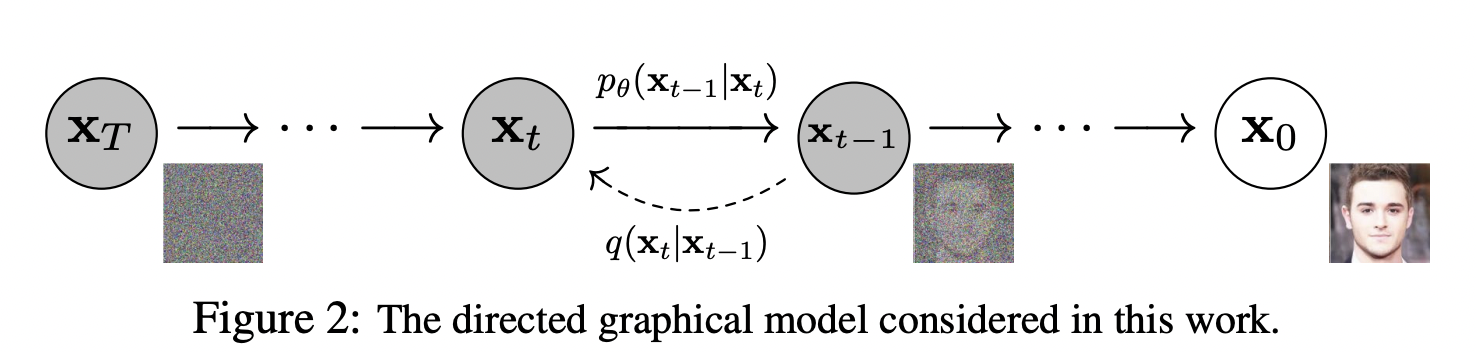
During inference, starting from random Gaussian noise, a sampler uses the trained model to sequentially predict and apply modifications to the noise to uncover the hidden image. In other words, the model is given multiple opportunities to progressively improve upon its prediction. The total number of attempts it is given to improve upon its prediction is a hyperparameter referred to as the number of inference steps. In practice, we’ve found that on average 30 is a good number of inference steps.
Here are the results where we used the same random seed but varied the number of model attempts from 1 to 30 steps with the following prompt: astronaut riding a horse, digital art, epic lighting, highly-detailed masterpiece trending HQ.

As you can see, the more attempts, the better the final prediction is.
If you are interested in learning more about the theory behind diffusion models, we recommend The Illustrated Stable Diffusion by Jay Alammar and How diffusion models work: the math from scratch by Sergios Karagiannakos and Nikolas Adaloglou.
Traditional inference method
When receiving multiple user requests, the current approach to serving is to group the prompts into a single input called “a batch” and run inference through the entire model using that same batch. Usually, the bigger the batch, the faster the inference per input is.
Here is the pseudo-code associated with diffusion model inference. We pass the prompts to a text encoder, then run the encoded text and noisy images through the sample for the given number of inference steps.
imgs = ... # batch of random noise images
text_conditions = model.text_encoder([prompt_1, prompt_2, ...])
for _ in range(steps):
imgs = sampler.step(imgs, text_conditions, ...)
final_imgs = imgs
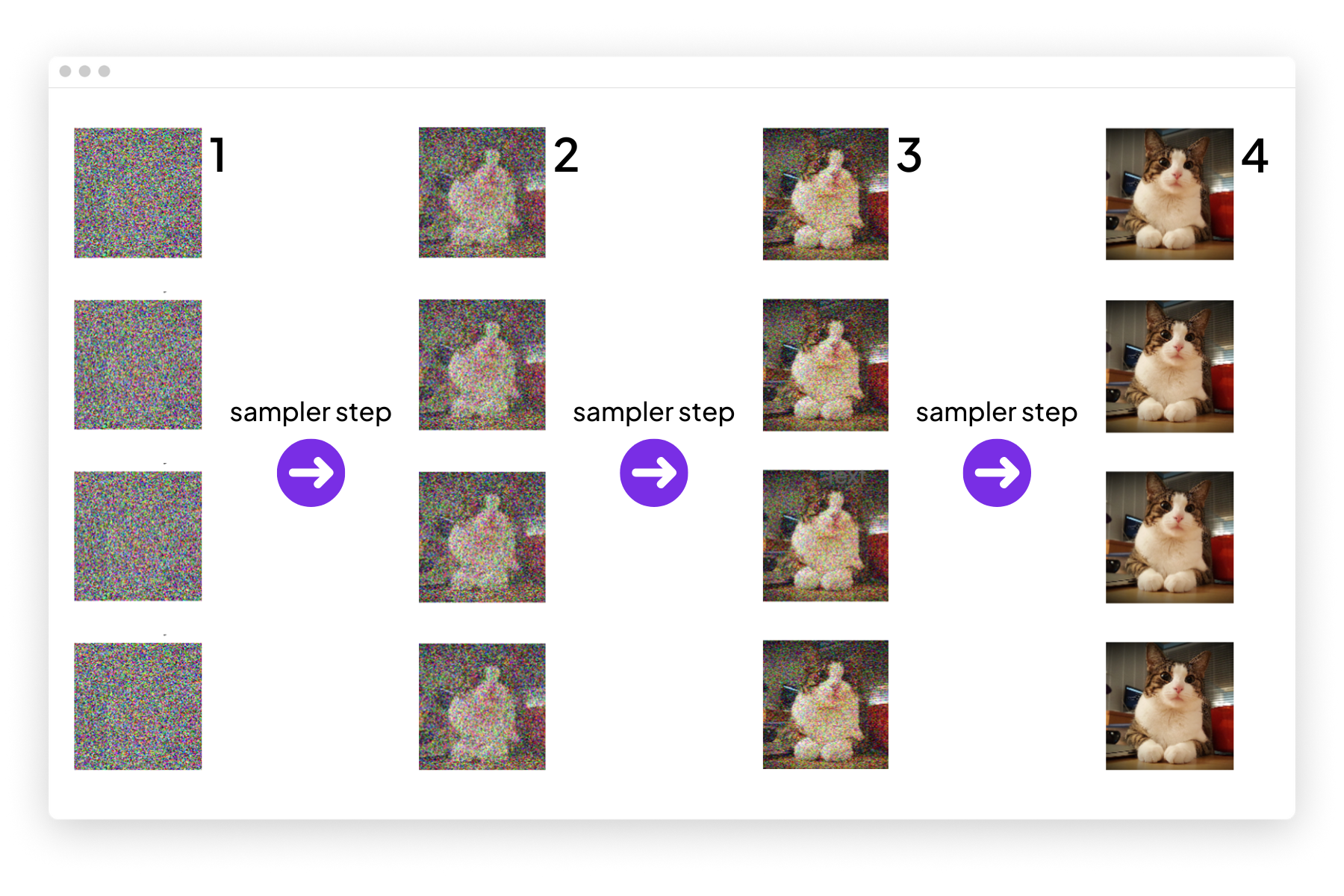
Here is an example of the 4-step diffusion process with a fixed batch of size 4. Each element within the batch is at the same diffusion step (1, 2, 3, 4).
In reality, however, requests to a server aren’t made at the exact same time, and the first requests end up waiting for the next ones to compose a batch. Put another way, think of this like ordering at a coffee shop: you place your order, but your barista won’t start making your coffee until three additional people line up behind you and place their orders.
Here is an illustration of the overall process:
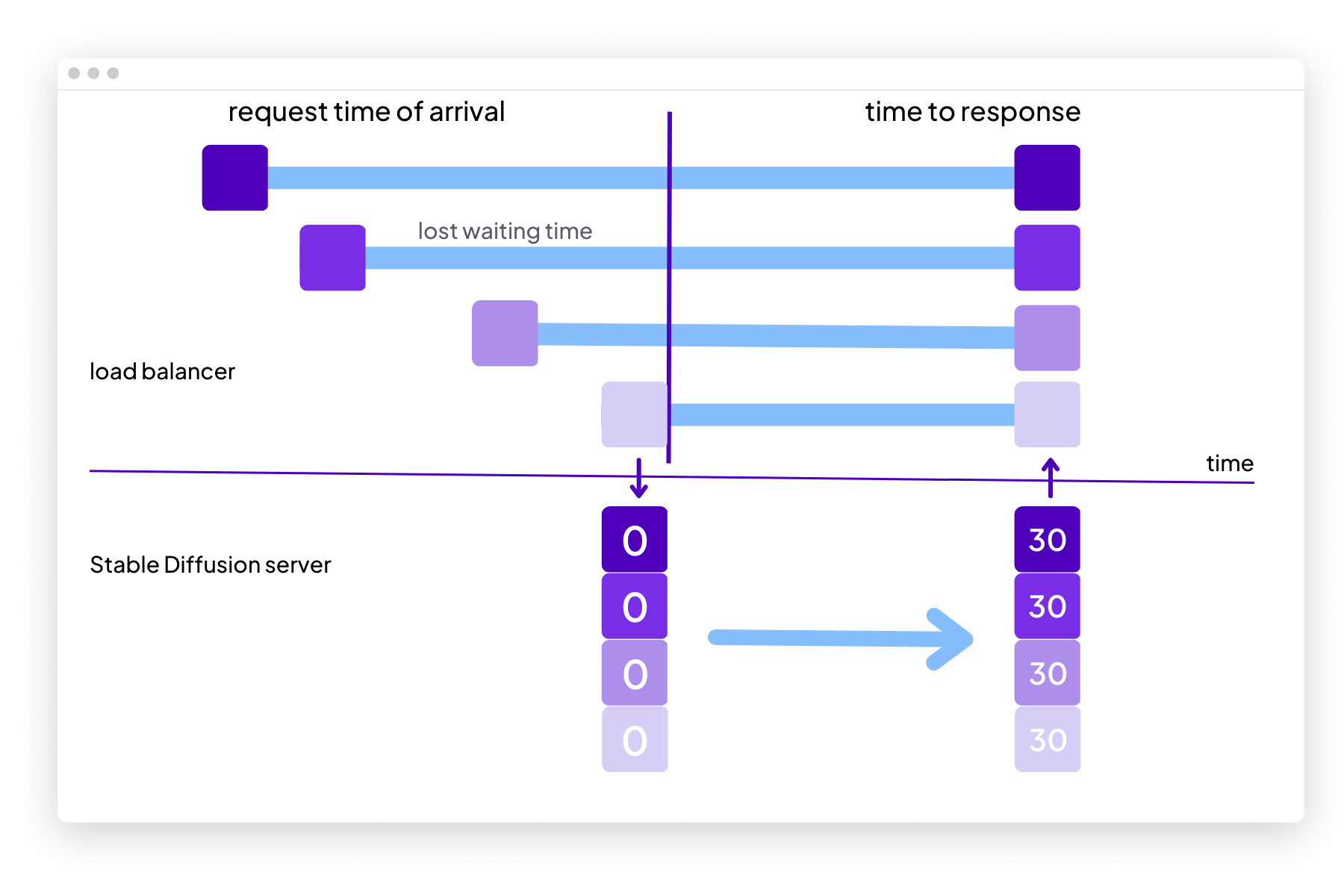
Additionally, once a batch is being processed, any new requests need to wait for the entire diffusion process to complete.
The trade-off between delaying inference in order to fill the batch and running a partially filled batch must be carefully considered, and can ultimately result in degraded user experience and underutilized servers.
Here are the logs for the current approach with a batch of 5:
inputs=[Text(text='astronaut riding a horse, digital art, epic lighting, highly-detailed masterpiece trending HQ')]
inputs=[Text(text='portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile')]
inputs=[Text(text='Keanu Reeves portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile, looking away')]
inputs=[Text(text='astronaut riding a horse, digital art, epic lighting, highly-detailed masterpiece trending HQ')]
[0, 0, 0, 0]
[1, 1, 1, ]
[2, 2, 2, 2]
[3, 3, 3, 3]
[4, 4, 4, 4]
[5, 5, 5, 5]
[6, 6, 6, 6]
[7, 7, 7, 7]
[8, 8, 8, 8]
[9, 9, 9, 9]
[10, 10, 10 10]
[11, 11, 11, 11]
[12, 12, 12, 12]
[13, 13, 13, 13]
[14, 14, 14, 14]
[15, 15, 15, 15]
[16, 16, 16, 16]
[17, 17, 17, 17]
[18, 18, 18, 18]
[19, 19, 19, 19]
[20, 20, 20, 20]
[21, 21, 21, 21]
[22, 22, 22, 22]
[23, 23, 23, 23]
[24, 24, 24, 24]
[25, 25, 25, 25]
[26, 26, 26, 26]
[27, 27, 27, 27]
[29, 29, 29, 29]
[Response: ...]
[Response: ...]
[Response: ...]
[Response: ...]
...
What we’ve devised to improve both user experience and server utilization is a novel method of leveraging the sequential diffusion process, to simultaneously improve latency and utilization.
Leveraging the diffusion process to accelerate inference
One approach to accelerate serving is to rely on the sequential behavior of diffusion models. Rather than having a fixed batch size for the n-steps of the diffusion process, we can dynamically adapt the size of the batch at every sampler step depending on the number of pending requests. To do this, not only does the batch size need to change dynamically, but we also need to keep track of the progress steps associated with each element.
Below is an illustration of this novel approach. When a new request is received, it is added to the current batch and processed in real-time. If an image has made its way through the entire diffusion process, it is removed from the batch.
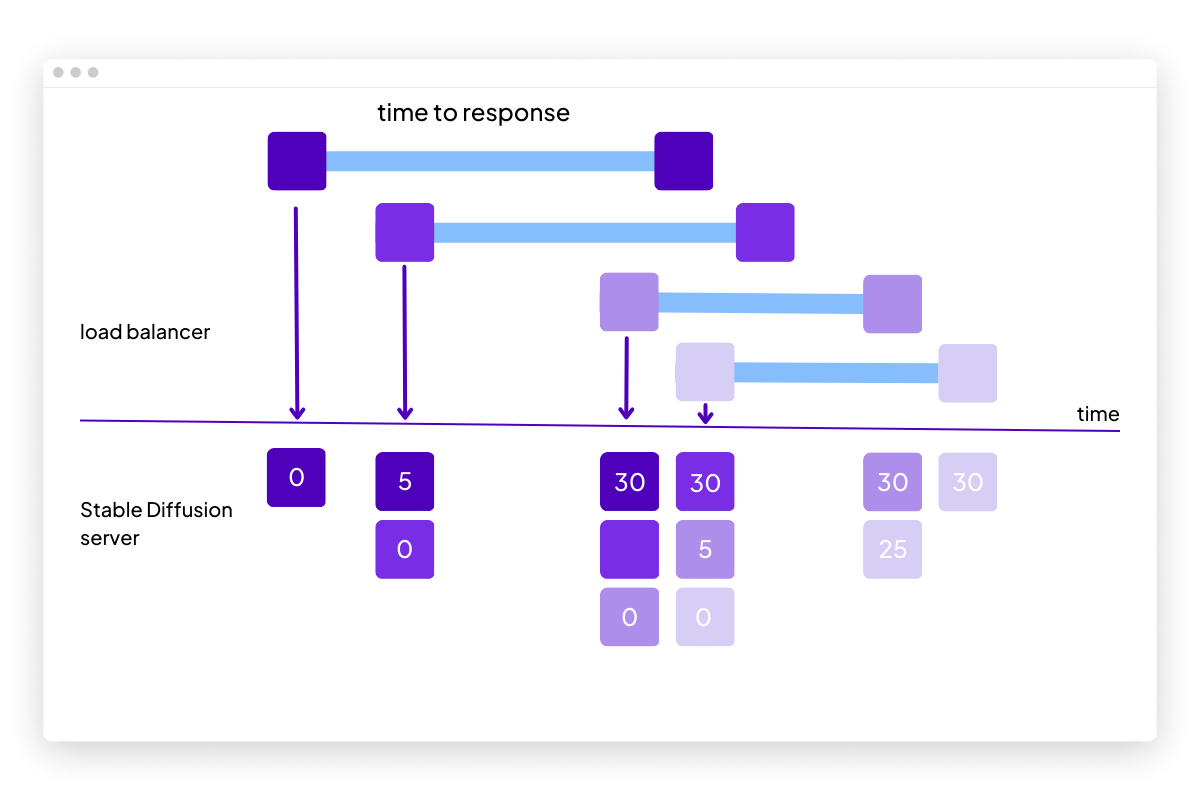
Here is another illustration of the process described above with images:

Here are the logs where we print the inputs, the steps for each sample in the batch, and the responses.
inputs=[Text(text='astronaut riding a horse, digital art, epic lighting, highly-detailed masterpiece trending HQ')]
[0]
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
[22]
[23]
inputs=[Text(text='portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile')]
[24, 0]
[25, 1]
[26, 2]
[27, 3]
[28, 4]
inputs=[Text(text='Keanu Reeves portrait photo of a asia old warrior chief, tribal panther make up, blue on red, side profile, looking away')]
[29, 5, 0]
[Response: ...]
[6, 1]
# Note: This is where the previous approach starts.
# Request 1 has finished and 2, 3 have already started.
inputs=[Text(text='portrait photo of a african old warrior chief, tribal panther make up, gold on white, side profile, looking away, serious eyes, 50mm portrait photography')]
[7, 2, 0]
[8, 3, 1]
[9, 4, 2]
[10, 5, 3]
[11, 6, 4]
[12, 7, 5]
[13, 8, 6]
[14, 9, 7]
[15, 10, 8]
[16, 11, 9]
[17, 12, 10]
[18, 13, 11]
[19, 14, 12]
[20, 15, 13]
[21, 16, 14]
[22, 17, 15]
[23, 18, 16]
[24, 19, 17]
[25, 20, 18]
[26, 21, 19]
[27, 22, 20]
[28, 23, 21]
[29, 24, 22]
[Response: ...]
[25, 23]
[26, 24]
[27, 25]
[28, 26]
[29, 27]
[Response: ...]
[28]
[29]
[Response: ...]
Below is the code for the process described above where new requests are added dynamically to the model predict step. This is how it works:
Step 1
For the very first request, a prediction task is created to perform inference through the model. For subsequent requests, the request and its future result are stored in a dictionary.
async def (self, request: BatchText):
# 1. On very first batch, create predictor task
if self._lock is None:
self._lock = asyncio.Lock()
if self._predictor_task is None:
self._predictor_task = asyncio.create_task(self.predict_fn())
assert len(request.inputs) == 1
# 2. Create future
future = asyncio.Future()
# 3. Add the request to the requests dictionarry
async with self._lock:
self._requests[uuid.uuid4().hex] = {
"data": request.inputs[0],
"response": future
}
# 4. Wait for the request to be ready
result = await future
return result
Step 2
The prediction task looks over the available requests and forwards them through the model in the following format, so the model can keep track of each request progress independently with their ID.
inputs = {
"ID_0": "prompt_0",
"ID_1": "prompt_1",
...
}
Step 3
Each model inference step modifies the inputs in-place by replacing the prompt with a batch and sample state used to track the intermediate steps and generated images.
inputs = {
"ID_0": {"img": ..., "step": ...}
"ID_1": {"img": ..., "step": ...}
...
"global_state": {"batch_img": ..., "batch_steps": ...}
}
Step 4
The states above are stored with the request for the next step generation. These states are stored after every sub inference. If a result is found e.g. an input has finished its diffusion process, it is attached as the result to the response future, unblocking the server response.
async def predict_fn(self):
while True:
async with self._lock:
keys = list(self._requests)
if len(keys) == 0:
await asyncio.sleep(0.0001)
continue
# Prepare prompts for the model
inputs = {
key: self.sanetize_data(self._requests[key])
for key in keys
}
# Apply model
results = self.apply_model(inputs)
# Keep track of the state of each request
for key, state in inputs.items():
if key == "global_state":
self._requests['global_state'] = {"state": state}
else:
self._requests[key]['state'] = state
# If any results is available, make response ready.
if results:
for key in results:
self._requests[key]['response'].set_result(
self.sanetize_results(results[key])
)
del self._requests[key]
# Sleep for python to check if any request has been received.
await asyncio.sleep(0.0001)
You can explore the source code here. Additionally, the model inference step tracks each element as it progresses through the diffusion steps within the batch. You can explore the new model inference step source code here.
Benchmarking Serving Strategies
To benchmark our new serving strategy, we deployed both versions on lightning.ai cover both T4 and A10 GPU machines. You can find the scripts here and here, respectively.
We then deployed a Locust server that creates multiple http users to load test the servers and collect benchmarks. The code for that is here.
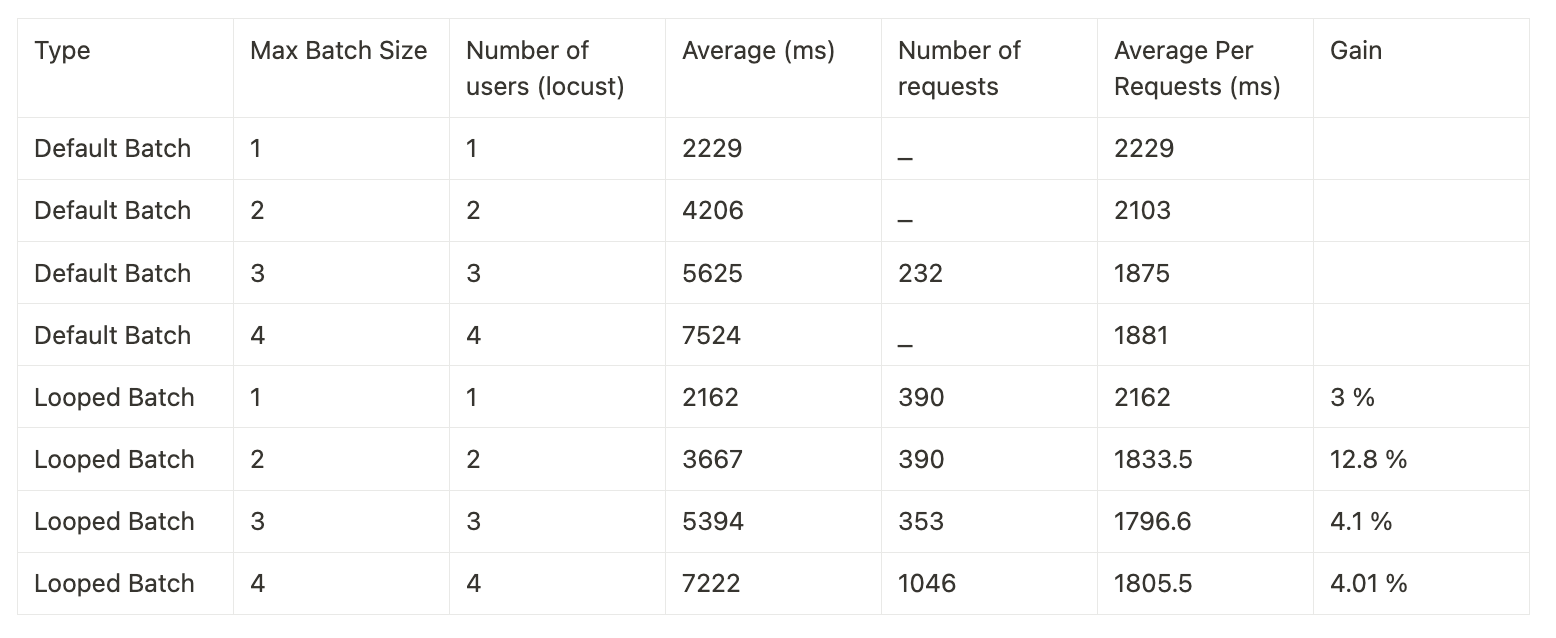
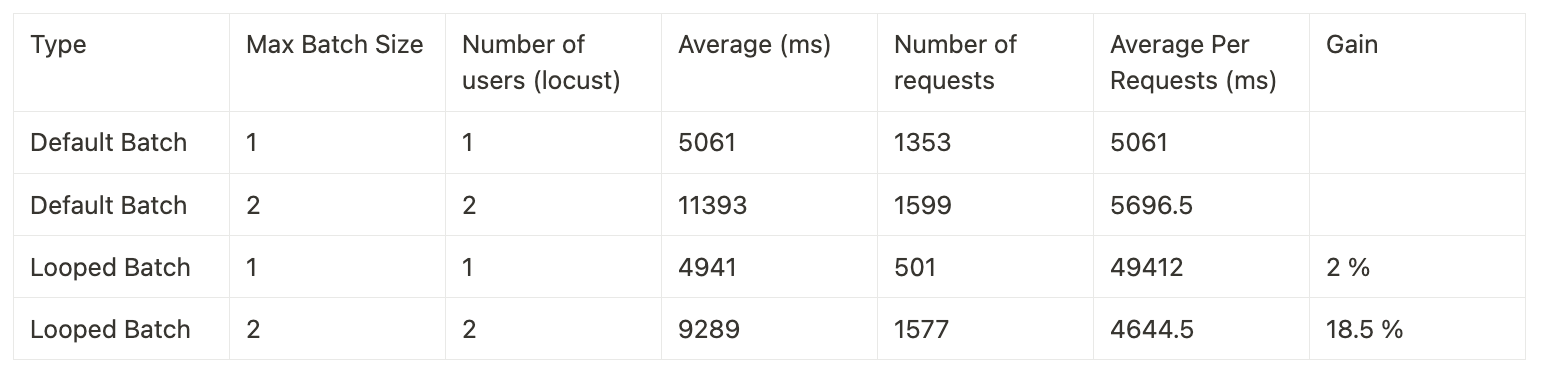
The new approach resulted in speedups ranging from 3-12.8% on A10 and 2-18.5% on T4.
Here are the benchmarks with an A10 GPU:
Here are the benchmarks with a T4 GPU:
Benchmark it yourself for free
- Create a Lightning account and get $30USD worth of credits
 Lightning Credits are used to pay for cloud compute for free.
Lightning Credits are used to pay for cloud compute for free. - Duplicate the Autoscaled Stable Diffusion Server Recipe on your Lightning account
- Use the DiffusionWithAutoscaler github repository to replicate the benchmark.
