Takeaways
One of the challenges with LLMs is their cost and large memory footprint. In the upcoming Lightning 2.1 release, we introduce new features that optimize all three stages of LLM usage: pretraining, finetuning, and inference!
One of the biggest challenges with LLMs is dealing with their large GPU memory requirements. In our Lit-LLaMA and Lit-Parrot open-source LLM repositories, we’ve implemented a few tricks that make it possible to run these models efficiently on consumer GPUs with limited memory. In the upcoming Lightning 2.1 release, we’re making some of these improvements more widely available through Lightning Fabric so you can apply them to your own models by changing just one line of code!
 Figure 1: We’re introducing Fabric.init_module(), a trick to get your LLM onto the GPU faster while also saving on peak memory. And by enabling quantization and lazy loading, you can squeeze out even more memory savings. Lower numbers are better.
Figure 1: We’re introducing Fabric.init_module(), a trick to get your LLM onto the GPU faster while also saving on peak memory. And by enabling quantization and lazy loading, you can squeeze out even more memory savings. Lower numbers are better.
Efficient initialization with Fabric
Lightning Fabric is what we use in our Lit-* repositories to minimize the boilerplate code needed to run models on different hardware without changing the code. Recently, we’ve added a convenient context manager called Fabric.init_module() that handles a couple of things for you, which includes the following:
- Creating the model directly on the target device (e.g., GPU) without first allocating memory on the CPU
- Creating the weight tensors in the desired precision (e.g., float 16) without first allocating memory for full-precision
- Optionally delaying allocation of memory if the model is so large that it needs to be spread across multiple GPUs (FSDP, DeepSpeed). More on this in a future blog post!
These three features combined reduce the peak memory usage during initialization and ultimately reduce the risk of you running out of memory.
Here is the naive way of getting the model on the GPU for inference. We’re initializing the weights of the Lit-LLaMA model, moving it to the GPU, and then converting it to a lower precision, which in total will require around 28 GB of memory if done this way:
from lit_llama import LLaMA
model = LLaMA.from_name("7B") model.cuda().bfloat16()
It is pretty slow, and we would run out of memory if our GPU has less than 28 GB. Here is the efficient alternative with Fabric and Fabric.init_module():
from lit_llama import LLaMA
import lightning as L
fabric = L.Fabric(accelerator="cuda", precision="bf16-true")
with fabric.init_module():
model = LLaMA.from_name("7B")This is much faster and only takes half the memory.
Let’s take a look at some concrete numbers in an end-to-end example where we will compare the memory consumption and loading speed of LLaMA 7B on a consumer GPU.
Full example
Here we want to look at a realistic example of performing inference with a 7B LLaMA model. But before we can do that, we need to download and install a few things:
- Install Lit-LLaMA following the steps in the README:
git clone <https://github.com/Lightning-AI/lit-llama>
cd lit-llama
pip install -r requirements.txt
- Download and convert the weights using the how-to guide.
python scripts/download.py --repo_id openlm-research/open_llama_7b --local_dir checkpoints/open-llama/7Bpython scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/open-llama/7B --model_size 7B ls checkpoints/lit-llama
At this point, you should already be able to use the model for inference by running
python generate.pybut we will now write our own minimal inference code to measure a few things. Let’s start with the baseline implementation, the standard way to load and run a model in PyTorch, without any optimizations applied. Hence, we simply create the model, load the checkpoint and measure how long that takes:
# BASELINE - no optimizations
import time
import lightning as L
import torch
from generate import generate
from lit_llama import LLaMA, Tokenizer
# Init Fabric: Run on 1 GPU, with 16-bit precision
fabric = L.Fabric( accelerator="cuda", devices=1, precision="bf16-true", )
# Load pretrained weights file
checkpoint = torch.load("checkpoints/lit-llama/7B/lit-llama.pth")
# Measure the time it takes to init the model and load weights
t0 = time.time()
model = LLaMA.from_name("7B")
model.load_state_dict(checkpoint)
print(f"Time to load model: {time.time() - t0:.02f} seconds.")
To get a realistic use case, we should also include an actual inference pass:
model.eval()
model = fabric.setup(model)
# Let LLaMA complete the following sentence:
prompt = "Hello, my name is"
tokenizer = Tokenizer("checkpoints/lit-llama/tokenizer.model")
encoded = tokenizer.encode(prompt, bos=True, eos=False, device=fabric.device)
prompt_length = encoded.size(0)
y = generate(model, encoded, max_new_tokens=50, temperature=0.8, top_k=200)
# Print the response and the max. memory used by our GPU print(tokenizer.decode(y))
print(f"Memory used: {torch.cuda.max_memory_reserved() / 1e9:.02f} GB")
At the end, this script prints the time it took to load the model and the total amount of memory used on the GPU:
Time to load model: 38.99
seconds. Memory used: 13.54 GBOptimizing loading time and memory usage
The time to load the model is high because it first gets created on the CPU and then moved to the GPU later. The larger the model is, the higher this impact. To avoid the redundant creation on CPU, we could have PyTorch create the model directly on the GPU by making this modification:
with fabric.device: # <-- add this model = LLaMA.from_name("7B")
While this is faster now (only ~3 secs), the memory consumption got up to ~28 GB because the weights get allocated in full-precision (32-bit). However, we would like to run the model in 16-bit precision, or even 8-bit quantized (more about that later). A memory peak like we see here is undesirable if we anyway convert the model to lower bit precision later on. Consumer GPUs would have run out of memory here (and you might have just done so if you’re following this tutorial on a small GPU).
Finally, let’s try the new init_module() feature in Fabric by replacing the above code with this:
with fabric.init_module(): # <-- add this! model = LLaMA.from_name("7B") model.load_state_dict(checkpoint)
We’re getting a fast load time (~4 secs) and lower memory usage (~14 GB). We can summarize our findings in a table:
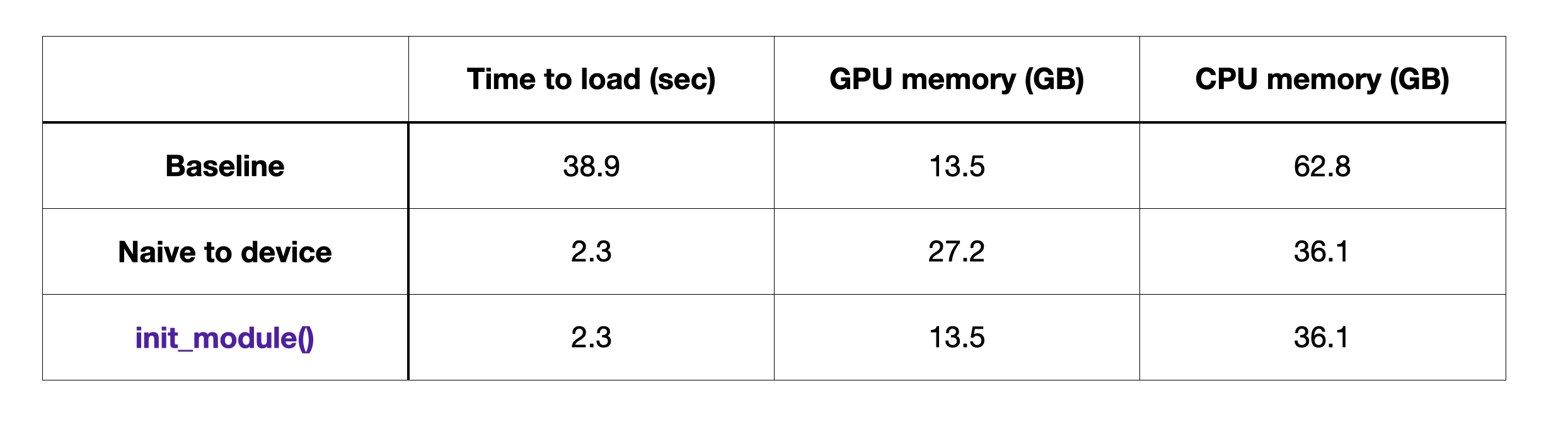
In addition, we’ve listed the CPU memory consumption. While it is great to see the 2x relative improvement with init_module() over the baseline, the absolute numbers here are still too high to make the 7B model run on a typical consumer machine with 12GB GPU memory and <32 GB CPU memory. Luckily, we have two more tricks up our sleeves.
Lazy-loading and quantization
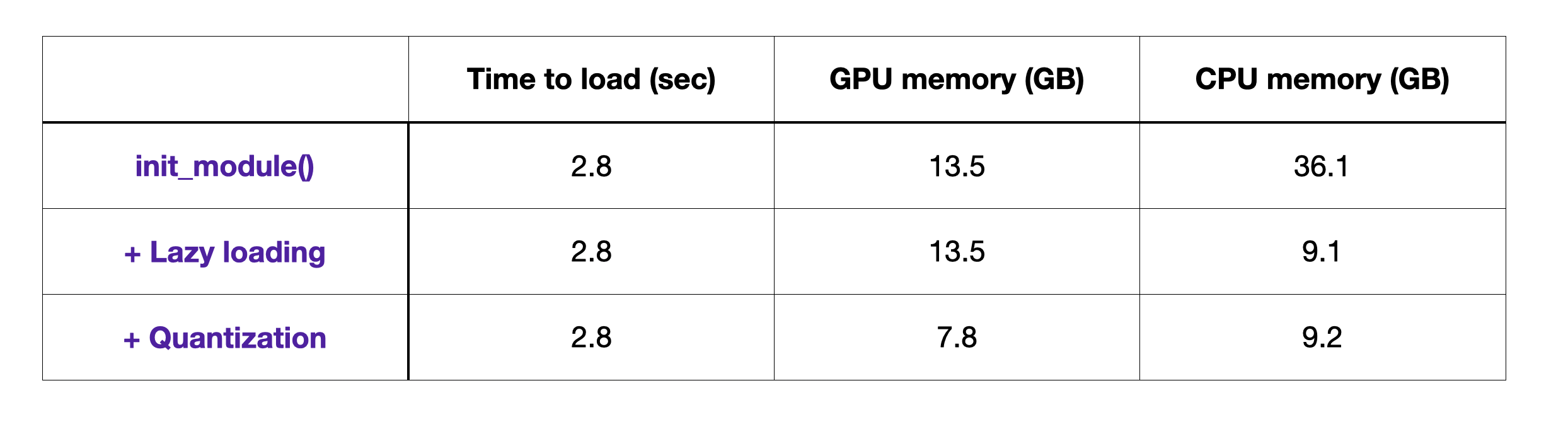
The high CPU memory usage is due to the fact that we’re loading the checkpoint into CPU memory first before we copy the weights into the model on the GPU. We eliminate this redundancy in Lit-LLaMA with lazy-loading the weight tensors in the checkpoint directly into the model on the GPU. In layman terms, the trick here is to load each weight tensor individually one by one from the checkpoint. This means we only ever need to consume memory for a single weight tensor at a time, and never have to load the entire checkpoints (30GB+) at once as is normally done in PyTorch.
Furthermore, we convert the weight matrices of the linear layers from 16-bit to 8-bit which results in a ~2x smaller memory footprint. To do this without a loss in predictive accuracy, we use a quantization method called LLM.int8() implemented in the bitsandbytes library. This transformation is inexpensive and works by identifying outliers, i.e., numbers that would result in a large error when truncating them to 8 bits, and performing the matrix multiplications in 16-bit while the majority of operations (inliers) can be performed in 8-bit.
The impact of lazy loading and quantization on top of init_module() is shown in the table below.
Conclusion
In this tutorial, we’ve learned about the init_module() feature in the upcoming Lightning Fabric release that helps us keep the peak GPU memory usage in control and enable fast loading times. It is especially helpful when we intend to run our model in lower bit precision since it avoids redundant memory allocation, both on GPU and on CPU. For highly-optimized inference and finetuning scripts, check out our lit-* repositories Lit-LLaMA and Lit-Parrot. They contain state of the art LLMs, highly-optimized with the techniques discussed here, and are easy to consume even if you are new to working with LLMs thanks to boilerplate-free, minimalistic code.
Join our Discord community to chat and ask your questions!

