Takeaways
Readers will learn the basics of Lightning Fabric’s plugin for 4-bit quantization.Introduction
The aim of 4-bit quantization is to reduce the memory usage of the model parameters by using lower precision types than full (float32) or half (bfloat16) precision. Meaning – 4-bit quantization compresses models that have billions of parameters like Llama 2 or SDXL and makes them require less memory.
Thankfully, Lightning Fabric makes quantization as easy as setting a mode flag in a plugin!
4-bit Quantization
4-bit quantization is discussed in the popular paper QLoRA: Efficient Finetuning of Quantized LLMs. QLoRA is a finetuning method that uses 4-bit quantization. The paper introduces this finetuning technique and demonstrates how it can be used to “finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance” by using the NF4 (normal float) format.
Lightning Fabric can use 4-bit quantization by setting the mode flag to either nf4 or fp4.
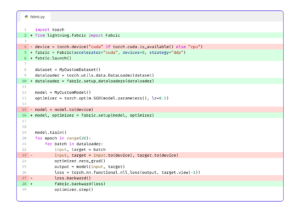
from lightning.fabric import Fabric
from lightning.fabric.plugins import BitsandbytesPrecision
# available 4-bit quantization modes
# ("nf4", "fp4")
mode = "nf4"
plugin = BitsandbytesPrecision(mode=mode)
fabric = Fabric(plugins=plugin)
model = CustomModule() # your PyTorch model
model = fabric.setup_module(model) # quantizes the layersDouble Quantization
Double quantization exists as an extra 4-bit quantization setting introduced alongside NF4 in QLoRA: Efficient Finetuning of Quantized LLMs. Double quantization works by quantizing the quantization constants that are internal to bitsandbytes’ procedures.
Lightning Fabric can use 4-bit double quantization by setting the mode flag to either nf4-dq or fp4-dq.
from lightning.fabric import Fabric
from lightning.fabric.plugins import BitsandbytesPrecision
# available 4-bit double quantization modes
# ("nf4-dq", "fp4-dq")
mode = "nf4-dq"
plugin = BitsandbytesPrecision(mode=mode)
fabric = Fabric(plugins=plugin)
model = CustomModule() # your PyTorch model
model = fabric.setup_module(model) # quantizes the layersConclusion
Quantization is a must for most production systems given that edge devices and consumer grade hardware typically require models of a much smaller memory footprint than more powerful hardware such as NVIDIA’s A100 80GB. Learning about this technique will enable a better understanding of deployment of LLMs like Llama 2 and SDXL, and requirements for edge devices in robotics, vehicles, and other systems.
Note
4-bit quantization and double quantization will only quantize the linear layers.Still have questions?
We have an amazing community and team of core engineers ready to answer your questions. So, join us on Discord or Discourse. See you there!
Resources and References
- Quantization in Lightning Fabric
- Introduction to Quantization
- Introduction to Quantization and API Summary
- Quantization in Practice
- Post Training Quantization
- QLoRA: Efficient Finetuning of Quantized LLMs
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- Automatic Mixed Precision for Deep Learning