Tensor Parallelism¶
Tensor parallelism is a technique for training large models by distributing layers across multiple devices, improving memory management and efficiency by reducing inter-device communication. However, for smaller models, the communication overhead may outweigh its benefits. This method is most effective for models with very large layers, significantly enhancing performance and memory efficiency.
How to exploit parallelism in linear layers¶
In tensor parallelism, the computation of a linear layer can be split up across GPUs. This saves memory because each GPU only needs to hold a portion of the weight matrix. There are two ways a linear layer can be split up: row-wise or column-wise.
Column-wise Parallel¶
In a column-wise parallel layer, the weight matrix is split evenly along the column dimension. Each GPU is sent the same input, and computes a regular matrix multiplication with its portion of the weight matrix. At the end, the outputs from each GPU can be concatenated to form the final output.
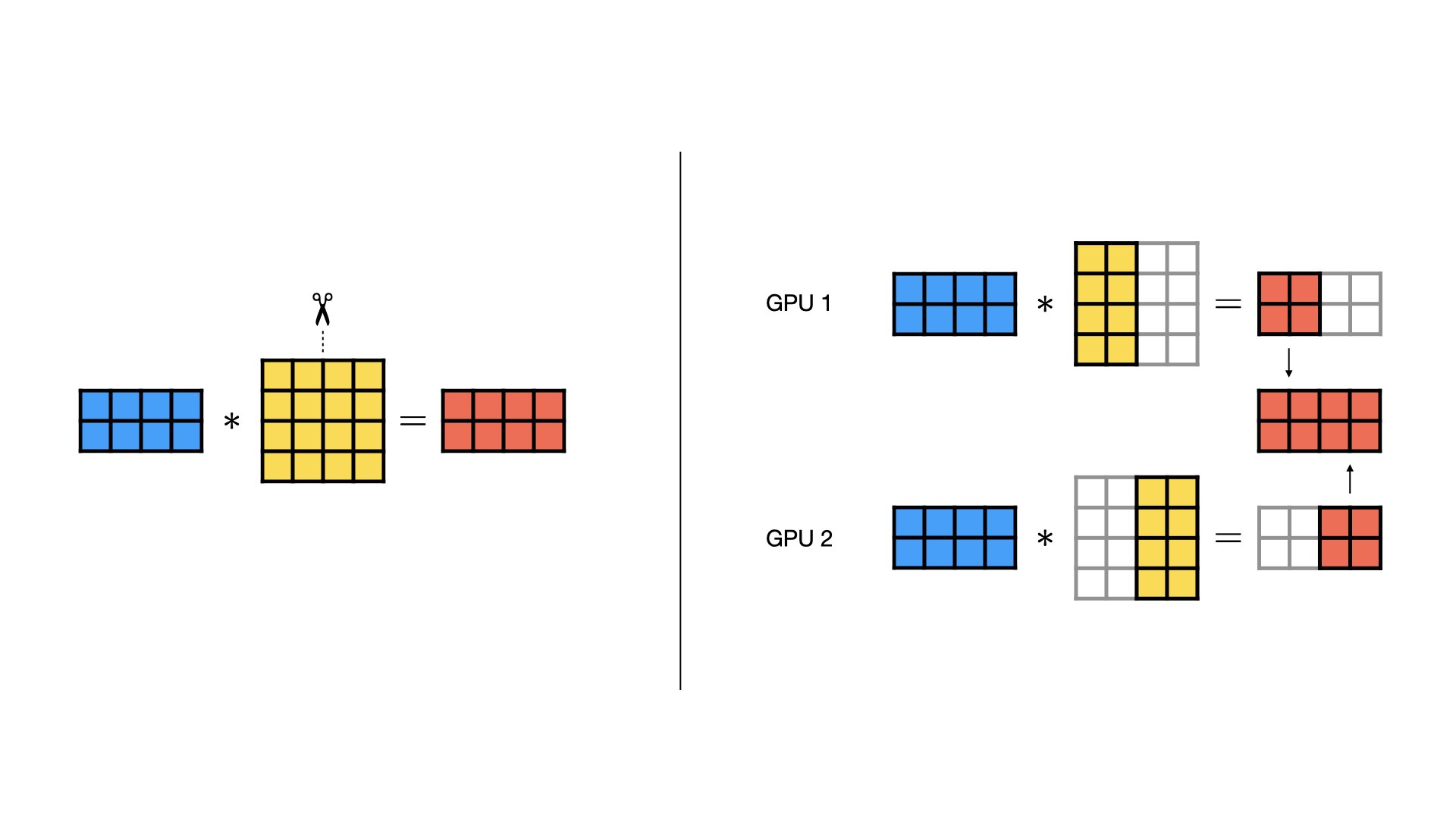
Row-wise Parallel¶
Row-wise parallelism divides the rows of the weight matrix evenly across devices. In addition, the input gets split the same way along the inner dimension (because the weight matrix now has fewer rows). Each GPU then performs a regular matrix multiplication with its portion of the weight matrix and inputs. At the end, the outputs from each GPU can be summed up element-wise (all-reduce) to form the final output.
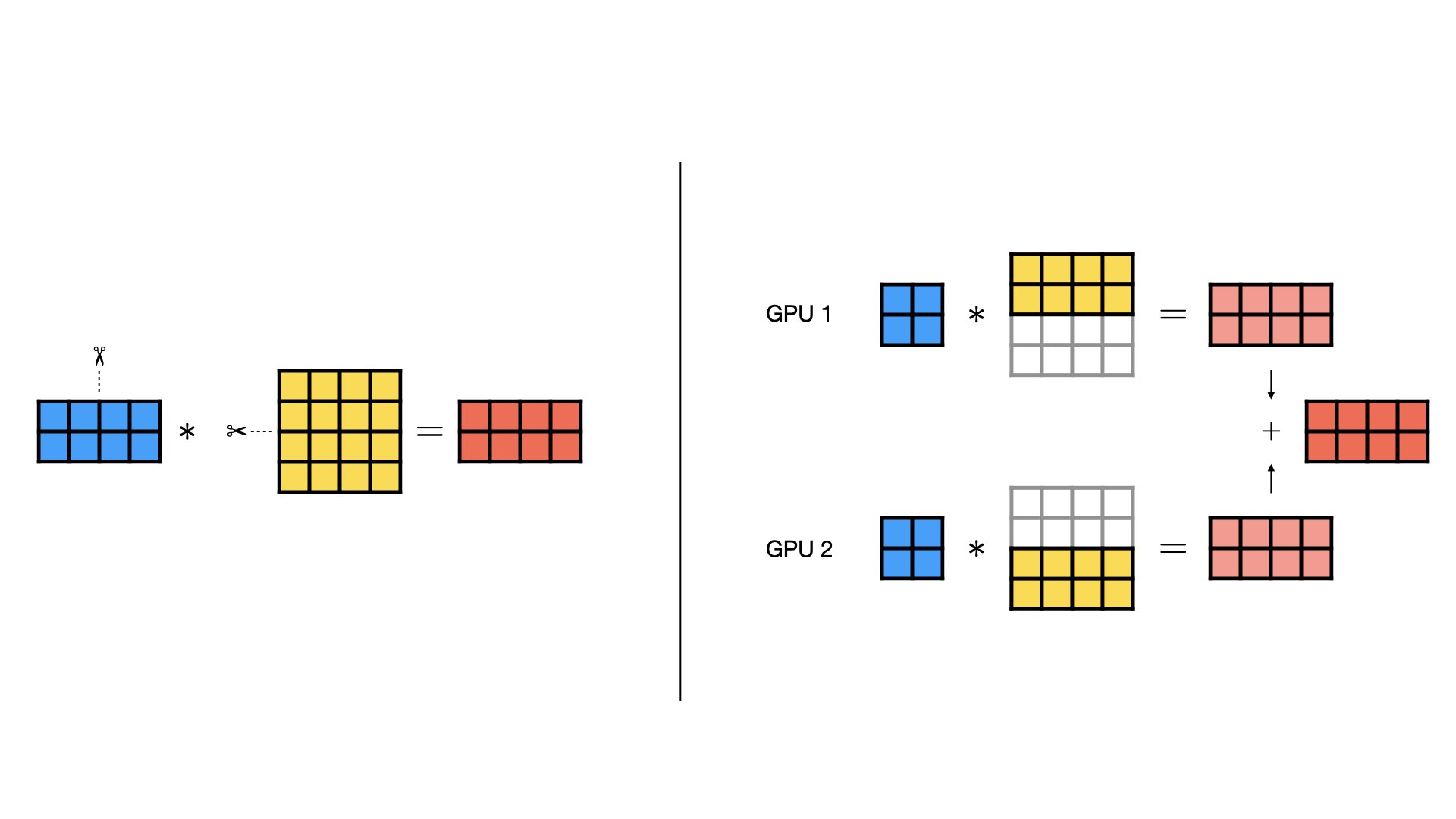
Combined Column- and Row-wise Parallel¶
When there are multiple linear layers in sequence, e.g., in a MLP or a Transformer, the column-wise and row-wise parallel styles can be combined for maximum effect. Instead of concatenating the output of the column-wise parallel layer, we keep the outputs separate and feed them directly to the row-wise parallel layer. This way, we avoid costly data transfers between GPUs.
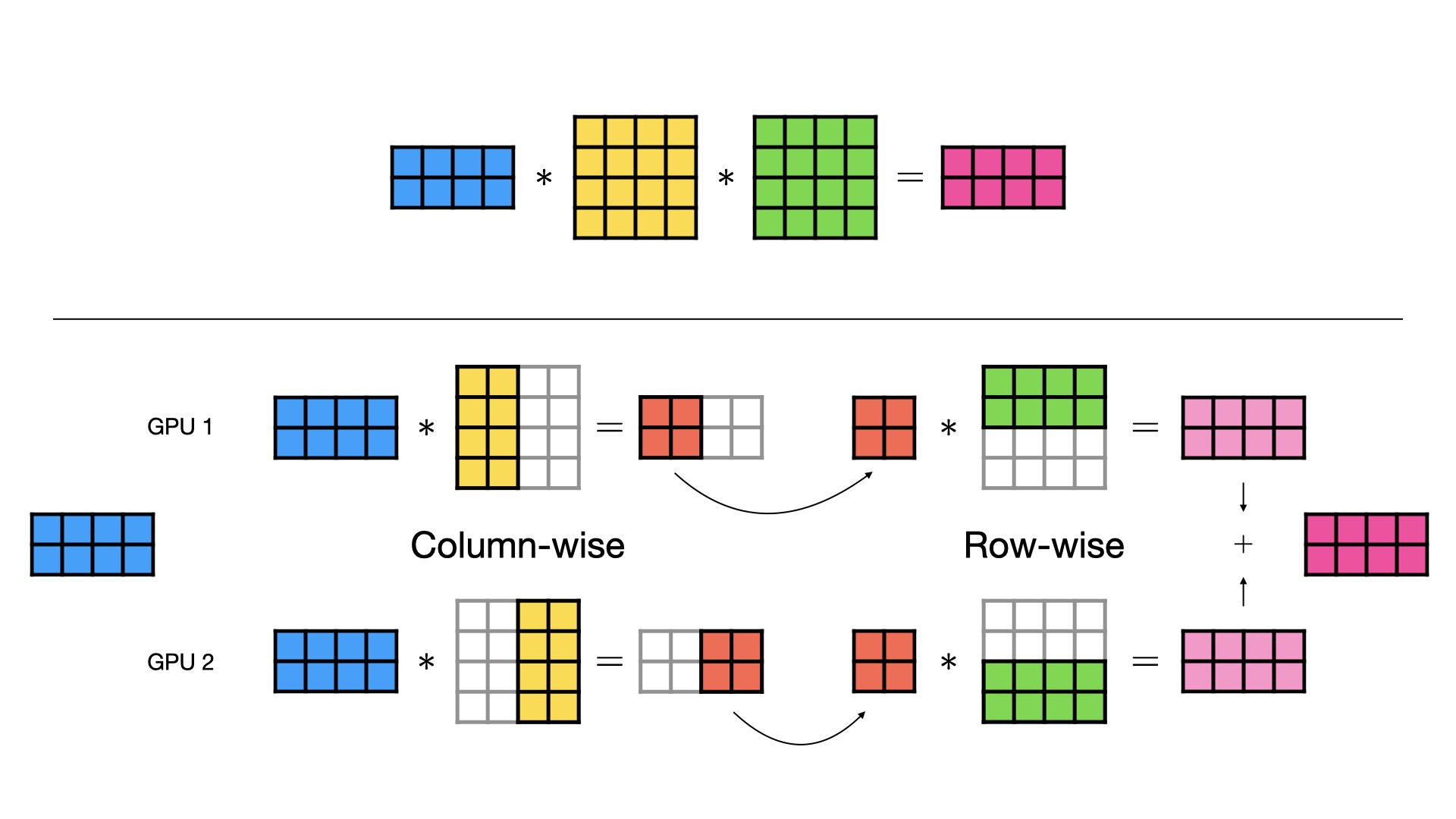
Note that activation functions between the layers can still be applied without additional communication because they are element-wise, but are not shown in the figures for simplicity.
Apply tensor parallelism to a model¶
To apply tensor parallelism to a LightningModule, you need a good understanding of your model’s architecture to make the decision of where to apply the parallel styles you’ve seen above. Let’s start with a simple MLP toy example:
import torch.nn as nn
import torch.nn.functional as F
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
This model has three linear layers. Layers w1 and w3 produce an output that is later multiplied element-wise.
That output is then fed into layer w2.
Therefore, w1 and w3 are suitable candidates for column-wise parallelism, because their output(s) can easily be combined with w2 in row-wise fashion.
Now, when implementing the LightningModule, override the configure_model() hook and apply the tensor parallelism to the model:
import lightning as L
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel
from torch.distributed.tensor.parallel import parallelize_module
class LitModel(L.LightningModule):
def __init__(self):
super().__init__()
self.model = FeedForward(8192, 8192)
def configure_model(self):
# Lightning will set up a `self.device_mesh` for you
tp_mesh = self.device_mesh["tensor_parallel"]
# Use PyTorch's distributed tensor APIs to parallelize the model
plan = {
"w1": ColwiseParallel(),
"w2": RowwiseParallel(),
"w3": ColwiseParallel(),
}
parallelize_module(self.model, tp_mesh, plan)
def training_step(self, batch):
...
def configure_optimizers(self):
...
def train_dataloader(self):
...
By writing the parallelization code in this special hook rather than hardcoding it into the model, we keep the original source code clean and maintainable.
Next, configure the ModelParallelStrategy in the Trainer:
import lightning as L
from lightning.pytorch.strategies import ModelParallelStrategy
# 1. Create the strategy
strategy = ModelParallelStrategy()
# 2. Configure devices and set the strategy in Trainer
trainer = L.Trainer(accelerator="cuda", devices=2, strategy=strategy)
trainer.fit(...)
No other changes to your training code are necessary at this point.
When trainer.fit(...) (or validate(), test, etc.) gets called, the Trainer will call your configure_model() hook before the training loop starts.
Full training example (requires at least 2 GPUs).
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel
from torch.distributed.tensor.parallel import parallelize_module
import lightning as L
from lightning.pytorch.demos.boring_classes import RandomDataset
from lightning.pytorch.strategies import ModelParallelStrategy
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class LitModel(L.LightningModule):
def __init__(self):
super().__init__()
self.model = FeedForward(8192, 8192)
def configure_model(self):
if self.device_mesh is None:
return
# Lightning will set up a `self.device_mesh` for you
tp_mesh = self.device_mesh["tensor_parallel"]
# Use PyTorch's distributed tensor APIs to parallelize the model
plan = {
"w1": ColwiseParallel(),
"w2": RowwiseParallel(),
"w3": ColwiseParallel(),
}
parallelize_module(self.model, tp_mesh, plan)
def training_step(self, batch):
output = self.model(batch)
loss = output.sum()
return loss
def configure_optimizers(self):
return torch.optim.AdamW(self.model.parameters(), lr=3e-3)
def train_dataloader(self):
# Trainer configures the sampler automatically for you such that
# all batches in a tensor-parallel group are identical
dataset = RandomDataset(8192, 64)
return torch.utils.data.DataLoader(dataset, batch_size=8, num_workers=2)
strategy = ModelParallelStrategy()
trainer = L.Trainer(
accelerator="cuda",
devices=2,
strategy=strategy,
max_epochs=1,
)
model = LitModel()
trainer.fit(model)
trainer.print(f"Peak memory usage: {torch.cuda.max_memory_allocated() / 1e9:.02f} GB")
Note
Tensor Parallelism in PyTorch Lightning as well as PyTorch is experimental. The APIs may change in the future.
When measuring the peak memory consumption, we should see that doubling the number of GPUs reduces the memory consumption roughly by half:
1 GPU (no TP) |
2 GPUs |
4 GPUs |
8 GPUs |
|
|---|---|---|---|---|
Memory per GPU |
4.04 GB |
2.03 GB |
1.02 GB |
0.60 GB |
Beyond this toy example, we recommend you study our LLM Tensor Parallel Example (Llama 3).
Data-loading considerations¶
In a tensor-parallelized model, it is important that the model receives an identical input on each GPU. Otherwise, training won’t converge. Therefore, when you shuffle data in your dataset or data loader, or when applying randomized transformations/augmentations in your data, ensure that the seed is set appropriately.
Given this requirement, your global batch size will be limited by the memory of a single GPU. To scale the batch size and accelerate training further, you can combine tensor parallelism with data parallelism (in particular, FSDP).
