GPU training (Expert)¶
Audience: Experts creating new scaling techniques such as FSDP or DeepSpeed.
Warning
This is an experimental feature.
Lightning enables experts focused on researching new ways of optimizing distributed training/inference strategies to create new strategies and plug them into Lightning.
For example, Lightning worked closely with the Microsoft team to develop a DeepSpeed integration and with the Facebook (Meta) team to develop a FSDP integration.
What is a Strategy?¶
Strategy controls the model distribution across training, evaluation, and prediction to be used by the Trainer. It can be controlled by passing different
strategy with aliases ("ddp", "ddp_spawn", "deepspeed" and so on) as well as a custom strategy to the strategy parameter for Trainer.
The Strategy in PyTorch Lightning handles the following responsibilities:
Launch and teardown of training processes (if applicable).
Setup communication between processes (NCCL, GLOO, MPI, and so on).
Provide a unified communication interface for reduction, broadcast, and so on.
Owns the
LightningModuleHandles/owns optimizers and schedulers.
Strategy is a composition of one Accelerator, one Precision Plugin, a CheckpointIO plugin and other optional plugins such as the ClusterEnvironment.
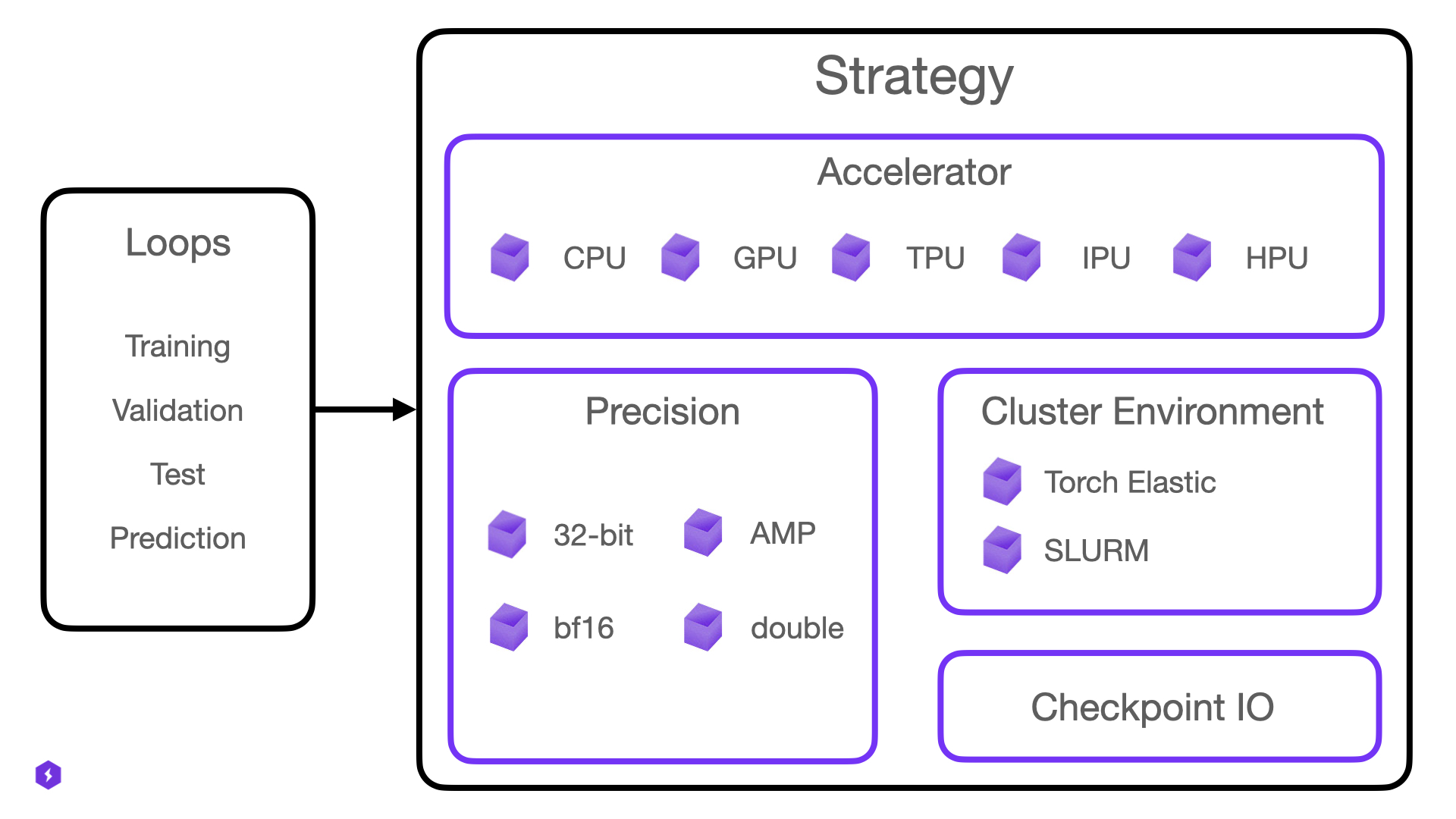
We expose Strategies mainly for expert users that want to extend Lightning for new hardware support or new distributed backends (e.g. a backend not yet supported by PyTorch itself).
Selecting a Built-in Strategy¶
Built-in strategies can be selected in two ways.
Pass the shorthand name to the
strategyTrainer argumentImport a Strategy from
lightning.pytorch.strategies, instantiate it and pass it to thestrategyTrainer argument
The latter allows you to configure further options on the specific strategy. Here are some examples:
# Training with the DistributedDataParallel strategy on 4 GPUs
trainer = Trainer(strategy="ddp", accelerator="gpu", devices=4)
# Training with the DistributedDataParallel strategy on 4 GPUs, with options configured
trainer = Trainer(strategy=DDPStrategy(static_graph=True), accelerator="gpu", devices=4)
# Training with the DDP Spawn strategy using auto accelerator selection
trainer = Trainer(strategy="ddp_spawn", accelerator="auto", devices=4)
# Training with the DeepSpeed strategy on available GPUs
trainer = Trainer(strategy="deepspeed", accelerator="gpu", devices="auto")
# Training with the DDP strategy using 3 CPU processes
trainer = Trainer(strategy="ddp", accelerator="cpu", devices=3)
# Training with the DDP Spawn strategy on 8 TPU cores
trainer = Trainer(strategy="ddp_spawn", accelerator="tpu", devices=8)
The below table lists all relevant strategies available in Lightning with their corresponding short-hand name:
Name |
Class |
Description |
|---|---|---|
fsdp |
Strategy for Fully Sharded Data Parallel training. Learn more. |
|
ddp |
Strategy for multi-process single-device training on one or multiple nodes. Learn more. |
|
ddp_spawn |
Same as “ddp” but launches processes using |
|
deepspeed |
Provides capabilities to run training using the DeepSpeed library, with training optimizations for large billion parameter models. Learn more. |
|
xla |
Strategy for training on multiple TPU devices using the |
|
single_xla |
|
Strategy for training on a single XLA device, like TPUs. Learn more. |
Third-party Strategies¶
There are powerful third-party strategies that integrate well with Lightning but aren’t maintained as part of the lightning package.
Checkout the gallery over here.
Create a Custom Strategy¶
Every strategy in Lightning is a subclass of one of the main base classes: Strategy, SingleDeviceStrategy or ParallelStrategy.
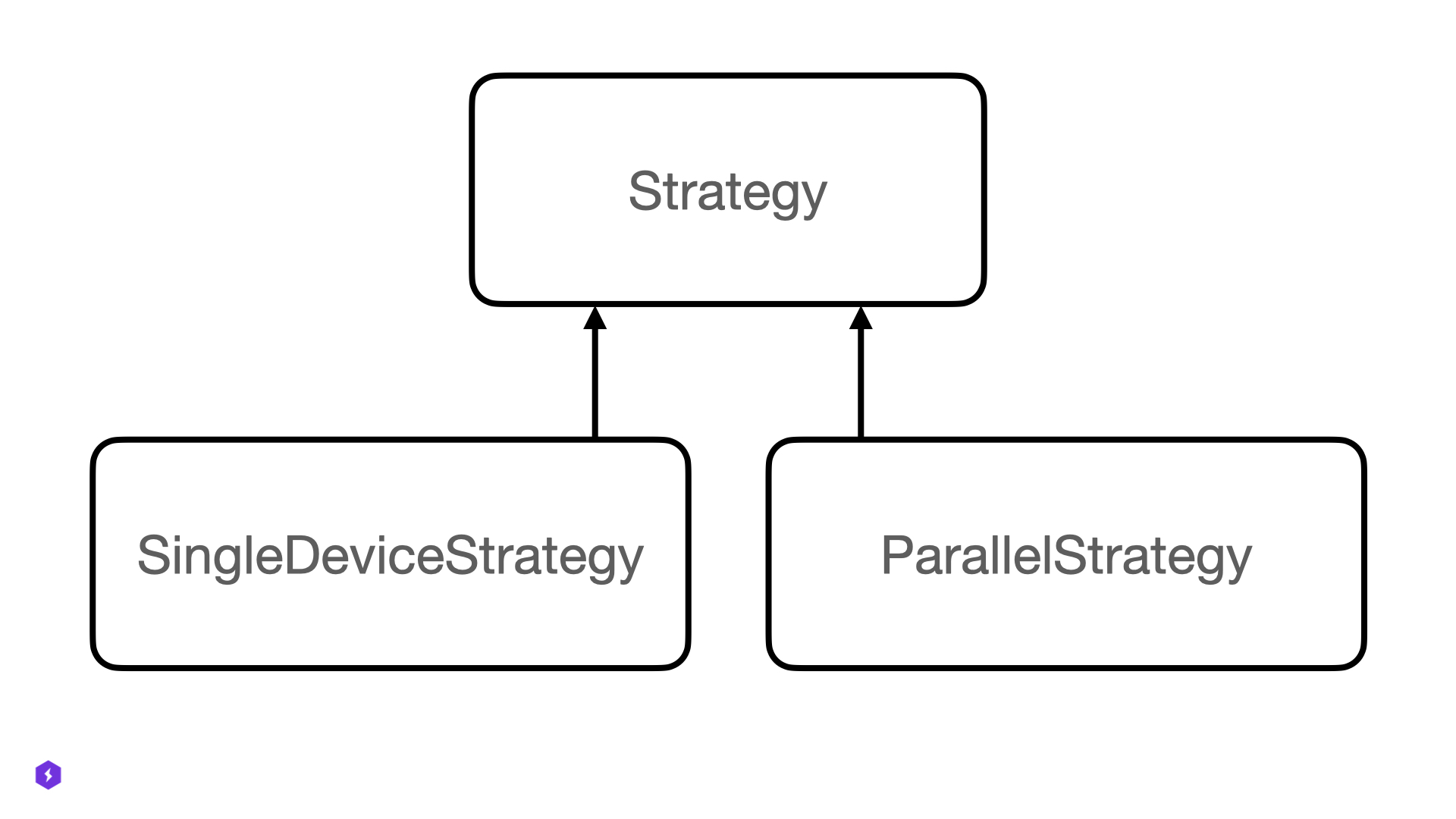
As an expert user, you may choose to extend either an existing built-in Strategy or create a completely new one by subclassing the base classes.
from lightning.pytorch.strategies import DDPStrategy
class CustomDDPStrategy(DDPStrategy):
def configure_ddp(self):
self.model = MyCustomDistributedDataParallel(
self.model,
device_ids=...,
)
def setup(self, trainer):
# you can access the accelerator and plugins directly
self.accelerator.setup()
self.precision_plugin.connect(...)
The custom strategy can then be passed into the Trainer directly via the strategy parameter.
# custom strategy
trainer = Trainer(strategy=CustomDDPStrategy())
Since the strategy also hosts the Accelerator and various plugins, you can customize all of them to work together as you like:
# custom strategy, with new accelerator and plugins
accelerator = MyAccelerator()
precision_plugin = MyPrecisionPlugin()
strategy = CustomDDPStrategy(accelerator=accelerator, precision_plugin=precision_plugin)
trainer = Trainer(strategy=strategy)
Strategy Registry¶
Lightning includes a registry that holds information about Training strategies and allows for the registration of new custom strategies.
The Strategies are assigned strings that identify them, such as “ddp”, “deepspeed_stage_2_offload”, and so on. It also returns the optional description and parameters for initialising the Strategy that were defined during registration.
# Training with the DDP Strategy
trainer = Trainer(strategy="ddp", accelerator="gpu", devices=4)
# Training with DeepSpeed ZeRO Stage 3 and CPU Offload
trainer = Trainer(strategy="deepspeed_stage_3_offload", accelerator="gpu", devices=3)
# Training with the TPU Spawn Strategy with `debug` as True
trainer = Trainer(strategy="xla_debug", accelerator="tpu", devices=8)
Additionally, you can pass your custom registered training strategies to the strategy argument.
from lightning.pytorch.strategies import DDPStrategy, StrategyRegistry, CheckpointIO
class CustomCheckpointIO(CheckpointIO):
def save_checkpoint(self, checkpoint: Dict[str, Any], path: Union[str, Path]) -> None:
...
def load_checkpoint(self, path: Union[str, Path]) -> Dict[str, Any]:
...
custom_checkpoint_io = CustomCheckpointIO()
# Register the DDP Strategy with your custom CheckpointIO plugin
StrategyRegistry.register(
"ddp_custom_checkpoint_io",
DDPStrategy,
description="DDP Strategy with custom checkpoint io plugin",
checkpoint_io=custom_checkpoint_io,
)
trainer = Trainer(strategy="ddp_custom_checkpoint_io", accelerator="gpu", devices=2)
