Style Guide¶
The main goal of PyTorch Lightning is to improve readability and reproducibility. Imagine looking into any GitHub repo or a research project,
finding a LightningModule, and knowing exactly where to look to find the things you care about.
The goal of this style guide is to encourage Lightning code to be structured similarly.
LightningModule¶
These are best practices for structuring your LightningModule class:
Systems vs Models¶
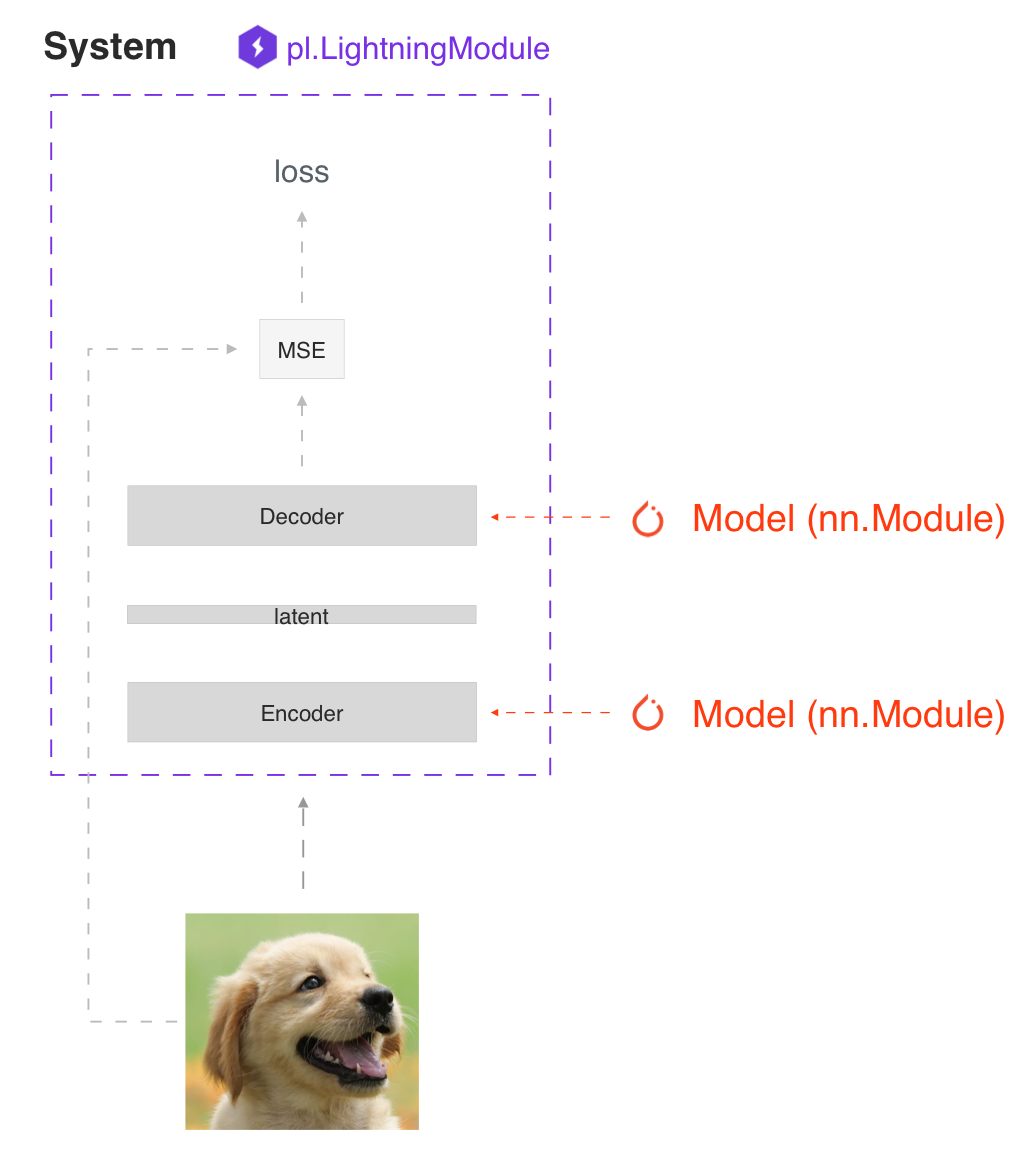
The main principle behind a LightningModule is that a full system should be self-contained. In Lightning, we differentiate between a system and a model.
A model is something like a resnet18, RNN, and so on.
A system defines how a collection of models interact with each other with user-defined training/evaluation logic. Examples of this are:
GANs
Seq2Seq
BERT
etc.
A LightningModule can define both a system and a model:
Here’s a LightningModule that defines a system. This structure is what we recommend as a best practice. Keeping the model separate from the system improves modularity, which eventually helps in better testing, reduces dependencies on the system and makes it easier to refactor.
class Encoder(nn.Module):
...
class Decoder(nn.Module):
...
class AutoEncoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
return self.encoder(x)
class AutoEncoderSystem(LightningModule):
def __init__(self):
super().__init__()
self.auto_encoder = AutoEncoder()
For fast prototyping, it’s often useful to define all the computations in a LightningModule. For reusability and scalability, it might be better to pass in the relevant backbones.
Here’s a LightningModule that defines a model. Although, we do not recommend to define a model like in the example.
class LitModel(LightningModule):
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear()
self.layer_2 = nn.Linear()
self.layer_3 = nn.Linear()
Self-contained¶
A Lightning module should be self-contained. To see how self-contained your model is, a good test is to ask yourself this question:
“Can someone drop this file into a Trainer without knowing anything about the internals?”
For example, we couple the optimizer with a model because the majority of models require a specific optimizer with a specific learning rate scheduler to work well.
Init¶
The first place where LightningModules tend to stop being self-contained is in the init. Try to define all the relevant sensible defaults in the init so that the user doesn’t have to guess.
Here’s an example where a user will have to go hunt through files to figure out how to init this LightningModule.
class LitModel(LightningModule):
def __init__(self, params):
self.lr = params.lr
self.coef_x = params.coef_x
Models defined as such leave you with many questions, such as what is coef_x? Is it a string? A float? What is the range?
Instead, be explicit in your init
class LitModel(LightningModule):
def __init__(self, encoder: nn.Module, coef_x: float = 0.2, lr: float = 1e-3):
...
Now the user doesn’t have to guess. Instead, they know the value type, and the model has a sensible default where the user can see the value immediately.
Method Order¶
The only required methods in the LightningModule are:
init
training_step
configure_optimizers
However, if you decide to implement the rest of the optional methods, the recommended order is:
model/system definition (init)
if doing inference, define forward
training hooks
validation hooks
test hooks
predict hooks
configure_optimizers
any other hooks
In practice, the code looks like this:
class LitModel(pl.LightningModule):
def __init__(...):
def forward(...):
def training_step(...):
def on_train_epoch_end(...):
def validation_step(...):
def on_validation_epoch_end(...):
def test_step(...):
def on_test_epoch_end(...):
def configure_optimizers(...):
def any_extra_hook(...):
Forward vs training_step¶
We recommend using forward() for inference/predictions and keeping
training_step() independent.
def forward(self, x):
embeddings = self.encoder(x)
return embeddings
def training_step(self, batch, batch_idx):
x, _ = batch
z = self.encoder(x)
pred = self.decoder(z)
...
Data¶
These are best practices for handling data.
DataLoaders¶
Lightning uses DataLoader to handle all the data flow through the system. Whenever you structure dataloaders,
make sure to tune the number of workers for maximum efficiency.
DataModules¶
The LightningDataModule is designed as a way of decoupling data-related
hooks from the LightningModule so you can develop dataset agnostic models. It makes it easy to hot swap different
datasets with your model, so you can test it and benchmark it across domains. It also makes sharing and reusing the exact data splits and transforms across projects possible.
Check out Complex data uses document to understand data management within Lightning and its best practices.
What dataset splits were used?
How many samples does this dataset have overall and within each split?
Which transforms were used?
It’s for this reason that we recommend you use datamodules. This is especially important when collaborating because it will save your team a lot of time as well.
All they need to do is drop a datamodule into the Trainer and not worry about what was done to the data.
This is true for both academic and corporate settings where data cleaning and ad-hoc instructions slow down the progress of iterating through ideas.
Checkout the live examples to get your hands dirty:
