Tutorial 5: Transformers and Multi-Head Attention¶
Author: Phillip Lippe
License: CC BY-SA
Generated: 2023-03-14T15:49:26.017592
In this tutorial, we will discuss one of the most impactful architectures of the last 2 years: the Transformer model. Since the paper Attention Is All You Need by Vaswani et al. had been published in 2017, the Transformer architecture has continued to beat benchmarks in many domains, most importantly in Natural Language Processing. Transformers with an incredible amount of parameters can generate long, convincing essays, and opened up new application fields of AI. As the hype of the Transformer architecture seems not to come to an end in the next years, it is important to understand how it works, and have implemented it yourself, which we will do in this notebook. This notebook is part of a lecture series on Deep Learning at the University of Amsterdam. The full list of tutorials can be found at https://uvadlc-notebooks.rtfd.io.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Slack
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "torch>=1.8.1, <1.14.0" "torchmetrics>=0.7, <0.12" "ipython[notebook]>=8.0.0, <8.12.0" "setuptools==67.4.0" "torchvision" "seaborn" "lightning>=2.0.0rc0" "matplotlib" "pytorch-lightning>=1.4, <2.0.0"
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
Despite the huge success of Transformers in NLP, we will not include the NLP domain in our notebook here. There are many courses at the University of Amsterdam that focus on Natural Language Processing and take a closer look at the application of the Transformer architecture in NLP (NLP2, Advanced Topics in Computational Semantics). Furthermore, and most importantly, there is so much more to the Transformer architecture. NLP is the domain the Transformer architecture has been originally proposed for and had the greatest impact on, but it also accelerated research in other domains, recently even Computer Vision. Thus, we focus here on what makes the Transformer and self-attention so powerful in general. In a second notebook, we will look at Vision Transformers, i.e. Transformers for image classification (link to notebook).
Below, we import our standard libraries.
[2]:
# Standard libraries
import math
import os
import urllib.request
from functools import partial
from urllib.error import HTTPError
# PyTorch Lightning
import lightning as L
# Plotting
import matplotlib
import matplotlib.pyplot as plt
import matplotlib_inline.backend_inline
import numpy as np
import seaborn as sns
# PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
# Torchvision
import torchvision
from lightning.pytorch.callbacks import ModelCheckpoint
from torchvision import transforms
from torchvision.datasets import CIFAR100
from tqdm.notebook import tqdm
plt.set_cmap("cividis")
%matplotlib inline
matplotlib_inline.backend_inline.set_matplotlib_formats("svg", "pdf") # For export
matplotlib.rcParams["lines.linewidth"] = 2.0
sns.reset_orig()
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = os.environ.get("PATH_DATASETS", "data/")
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/Transformers/")
# Setting the seed
L.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print("Device:", device)
Global seed set to 42
Device: cuda:0
<Figure size 640x480 with 0 Axes>
Two pre-trained models are downloaded below. Make sure to have adjusted your CHECKPOINT_PATH before running this code if not already done.
[3]:
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial6/"
# Files to download
pretrained_files = ["ReverseTask.ckpt", "SetAnomalyTask.ckpt"]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if "/" in file_name:
os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print("Downloading %s..." % file_url)
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print(
"Something went wrong. Please try to download the file manually,"
" or contact the author with the full output including the following error:\n",
e,
)
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial6/ReverseTask.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial6/SetAnomalyTask.ckpt...
The Transformer architecture¶
In the first part of this notebook, we will implement the Transformer architecture by hand. As the architecture is so popular, there already exists a Pytorch module nn.Transformer (documentation) and a tutorial on how to use it for next token prediction. However, we will implement it here ourselves, to get through to the smallest details.
There are of course many more tutorials out there about attention and Transformers. Below, we list a few that are worth exploring if you are interested in the topic and might want yet another perspective on the topic after this one:
Transformer: A Novel Neural Network Architecture for Language Understanding (Jakob Uszkoreit, 2017) - The original Google blog post about the Transformer paper, focusing on the application in machine translation.
The Illustrated Transformer (Jay Alammar, 2018) - A very popular and great blog post intuitively explaining the Transformer architecture with many nice visualizations. The focus is on NLP.
Attention? Attention! (Lilian Weng, 2018) - A nice blog post summarizing attention mechanisms in many domains including vision.
Illustrated: Self-Attention (Raimi Karim, 2019) - A nice visualization of the steps of self-attention. Recommended going through if the explanation below is too abstract for you.
The Transformer family (Lilian Weng, 2020) - A very detailed blog post reviewing more variants of Transformers besides the original one.
What is Attention?¶
The attention mechanism describes a recent new group of layers in neural networks that has attracted a lot of interest in the past few years, especially in sequence tasks. There are a lot of different possible definitions of “attention” in the literature, but the one we will use here is the following: the attention mechanism describes a weighted average of (sequence) elements with the weights dynamically computed based on an input query and elements’ keys. So what does this exactly mean? The goal is to take an average over the features of multiple elements. However, instead of weighting each element equally, we want to weight them depending on their actual values. In other words, we want to dynamically decide on which inputs we want to “attend” more than others. In particular, an attention mechanism has usually four parts we need to specify:
Query: The query is a feature vector that describes what we are looking for in the sequence, i.e. what would we maybe want to pay attention to.
Keys: For each input element, we have a key which is again a feature vector. This feature vector roughly describes what the element is “offering”, or when it might be important. The keys should be designed such that we can identify the elements we want to pay attention to based on the query.
Values: For each input element, we also have a value vector. This feature vector is the one we want to average over.
Score function: To rate which elements we want to pay attention to, we need to specify a score function
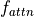 . The score function takes the query and a key as input, and output the score/attention weight of the query-key pair. It is usually implemented by simple similarity metrics like a dot product, or a small MLP.
. The score function takes the query and a key as input, and output the score/attention weight of the query-key pair. It is usually implemented by simple similarity metrics like a dot product, or a small MLP.
The weights of the average are calculated by a softmax over all score function outputs. Hence, we assign those value vectors a higher weight whose corresponding key is most similar to the query. If we try to describe it with pseudo-math, we can write:
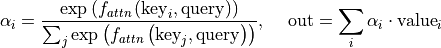
Visually, we can show the attention over a sequence of words as follows:

For every word, we have one key and one value vector. The query is compared to all keys with a score function (in this case the dot product) to determine the weights. The softmax is not visualized for simplicity. Finally, the value vectors of all words are averaged using the attention weights.
Most attention mechanisms differ in terms of what queries they use, how the key and value vectors are defined, and what score function is used. The attention applied inside the Transformer architecture is called self-attention. In self-attention, each sequence element provides a key, value, and query. For each element, we perform an attention layer where based on its query, we check the similarity of the all sequence elements’ keys, and returned a different, averaged value vector for each element. We will now go into a bit more detail by first looking at the specific implementation of the attention mechanism which is in the Transformer case the scaled dot product attention.
Scaled Dot Product Attention¶
The core concept behind self-attention is the scaled dot product attention. Our goal is to have an attention mechanism with which any element in a sequence can attend to any other while still being efficient to compute. The dot product attention takes as input a set of queries 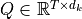 , keys
, keys 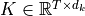 and values
and values 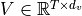 where
where 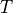 is the sequence length, and
is the sequence length, and 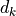 and
and 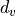 are the hidden
dimensionality for queries/keys and values respectively. For simplicity, we neglect the batch dimension for now. The attention value from element
are the hidden
dimensionality for queries/keys and values respectively. For simplicity, we neglect the batch dimension for now. The attention value from element 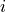 to
to 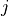 is based on its similarity of the query
is based on its similarity of the query 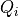 and key
and key 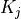 , using the dot product as the similarity metric. In math, we calculate the dot product attention as follows:
, using the dot product as the similarity metric. In math, we calculate the dot product attention as follows:
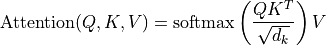
The matrix multiplication 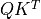 performs the dot product for every possible pair of queries and keys, resulting in a matrix of the shape
performs the dot product for every possible pair of queries and keys, resulting in a matrix of the shape 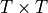 . Each row represents the attention logits for a specific element to all other elements in the sequence. On these, we apply a softmax and multiply with the value vector to obtain a weighted mean (the weights being determined by the attention). Another perspective on this attention mechanism offers the computation graph which is
visualized below (figure credit - Vaswani et al., 2017).
. Each row represents the attention logits for a specific element to all other elements in the sequence. On these, we apply a softmax and multiply with the value vector to obtain a weighted mean (the weights being determined by the attention). Another perspective on this attention mechanism offers the computation graph which is
visualized below (figure credit - Vaswani et al., 2017).

One aspect we haven’t discussed yet is the scaling factor of 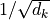 . This scaling factor is crucial to maintain an appropriate variance of attention values after initialization. Remember that we intialize our layers with the intention of having equal variance throughout the model, and hence,
. This scaling factor is crucial to maintain an appropriate variance of attention values after initialization. Remember that we intialize our layers with the intention of having equal variance throughout the model, and hence, 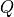 and
and 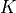 might also have a variance close to
might also have a variance close to 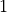 . However, performing a dot product over two vectors with a variance
. However, performing a dot product over two vectors with a variance 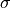 results in a scalar having
-times higher variance:
results in a scalar having
-times higher variance:
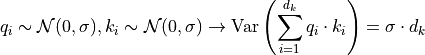
If we do not scale down the variance back to , the softmax over the logits will already saturate to for one random element and  for all others. The gradients through the softmax will be close to zero so that we can’t learn the parameters appropriately.
for all others. The gradients through the softmax will be close to zero so that we can’t learn the parameters appropriately.
The block Mask (opt. ) in the diagram above represents the optional masking of specific entries in the attention matrix. This is for instance used if we stack multiple sequences with different lengths into a batch. To still benefit from parallelization in PyTorch, we pad the sentences to the same length and mask out the padding tokens during the calculation of the attention values. This is usually done by setting the respective attention logits to a very low value.
After we have discussed the details of the scaled dot product attention block, we can write a function below which computes the output features given the triple of queries, keys, and values:
[4]:
def scaled_dot_product(q, k, v, mask=None):
d_k = q.size()[-1]
attn_logits = torch.matmul(q, k.transpose(-2, -1))
attn_logits = attn_logits / math.sqrt(d_k)
if mask is not None:
attn_logits = attn_logits.masked_fill(mask == 0, -9e15)
attention = F.softmax(attn_logits, dim=-1)
values = torch.matmul(attention, v)
return values, attention
Note that our code above supports any additional dimensionality in front of the sequence length so that we can also use it for batches. However, for a better understanding, let’s generate a few random queries, keys, and value vectors, and calculate the attention outputs:
[5]:
seq_len, d_k = 3, 2
L.seed_everything(42)
q = torch.randn(seq_len, d_k)
k = torch.randn(seq_len, d_k)
v = torch.randn(seq_len, d_k)
values, attention = scaled_dot_product(q, k, v)
print("Q\n", q)
print("K\n", k)
print("V\n", v)
print("Values\n", values)
print("Attention\n", attention)
Global seed set to 42
Q
tensor([[ 0.3367, 0.1288],
[ 0.2345, 0.2303],
[-1.1229, -0.1863]])
K
tensor([[ 2.2082, -0.6380],
[ 0.4617, 0.2674],
[ 0.5349, 0.8094]])
V
tensor([[ 1.1103, -1.6898],
[-0.9890, 0.9580],
[ 1.3221, 0.8172]])
Values
tensor([[ 0.5698, -0.1520],
[ 0.5379, -0.0265],
[ 0.2246, 0.5556]])
Attention
tensor([[0.4028, 0.2886, 0.3086],
[0.3538, 0.3069, 0.3393],
[0.1303, 0.4630, 0.4067]])
Before continuing, make sure you can follow the calculation of the specific values here, and also check it by hand. It is important to fully understand how the scaled dot product attention is calculated.
Multi-Head Attention¶
The scaled dot product attention allows a network to attend over a sequence. However, often there are multiple different aspects a sequence element wants to attend to, and a single weighted average is not a good option for it. This is why we extend the attention mechanisms to multiple heads, i.e. multiple different query-key-value triplets on the same features. Specifically, given a query, key, and value matrix, we transform those into 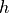 sub-queries, sub-keys, and sub-values, which we
pass through the scaled dot product attention independently. Afterward, we concatenate the heads and combine them with a final weight matrix. Mathematically, we can express this operation as:
sub-queries, sub-keys, and sub-values, which we
pass through the scaled dot product attention independently. Afterward, we concatenate the heads and combine them with a final weight matrix. Mathematically, we can express this operation as:

We refer to this as Multi-Head Attention layer with the learnable parameters 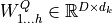 ,
, 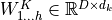 ,
, 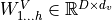 , and
, and 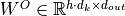 (
(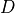 being the input dimensionality). Expressed in a computational graph, we can visualize it as below (figure credit - Vaswani et al., 2017).
being the input dimensionality). Expressed in a computational graph, we can visualize it as below (figure credit - Vaswani et al., 2017).

How are we applying a Multi-Head Attention layer in a neural network, where we don’t have an arbitrary query, key, and value vector as input? Looking at the computation graph above, a simple but effective implementation is to set the current feature map in a NN, 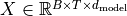 , as , and
, as , and 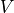 (
(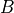 being the batch size, the sequence length,
being the batch size, the sequence length,  the hidden dimensionality of
the hidden dimensionality of 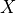 ). The
consecutive weight matrices
). The
consecutive weight matrices 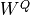 ,
, 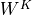 , and
, and 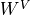 can transform to the corresponding feature vectors that represent the queries, keys, and values of the input. Using this approach, we can implement the Multi-Head Attention module below.
can transform to the corresponding feature vectors that represent the queries, keys, and values of the input. Using this approach, we can implement the Multi-Head Attention module below.
[6]:
class MultiheadAttention(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "Embedding dimension must be 0 modulo number of heads."
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# Stack all weight matrices 1...h together for efficiency
# Note that in many implementations you see "bias=False" which is optional
self.qkv_proj = nn.Linear(input_dim, 3 * embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
self._reset_parameters()
def _reset_parameters(self):
# Original Transformer initialization, see PyTorch documentation
nn.init.xavier_uniform_(self.qkv_proj.weight)
self.qkv_proj.bias.data.fill_(0)
nn.init.xavier_uniform_(self.o_proj.weight)
self.o_proj.bias.data.fill_(0)
def forward(self, x, mask=None, return_attention=False):
batch_size, seq_length, embed_dim = x.size()
qkv = self.qkv_proj(x)
# Separate Q, K, V from linear output
qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3 * self.head_dim)
qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, Dims]
q, k, v = qkv.chunk(3, dim=-1)
# Determine value outputs
values, attention = scaled_dot_product(q, k, v, mask=mask)
values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]
values = values.reshape(batch_size, seq_length, embed_dim)
o = self.o_proj(values)
if return_attention:
return o, attention
else:
return o
One crucial characteristic of the multi-head attention is that it is permutation-equivariant with respect to its inputs. This means that if we switch two input elements in the sequence, e.g. 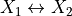 (neglecting the batch dimension for now), the output is exactly the same besides the elements 1 and 2 switched. Hence, the multi-head attention is actually looking at the input not as a sequence, but as a set of elements. This property makes the multi-head attention block and
the Transformer architecture so powerful and widely applicable! But what if the order of the input is actually important for solving the task, like language modeling? The answer is to encode the position in the input features, which we will take a closer look at later (topic Positional encodings below).
(neglecting the batch dimension for now), the output is exactly the same besides the elements 1 and 2 switched. Hence, the multi-head attention is actually looking at the input not as a sequence, but as a set of elements. This property makes the multi-head attention block and
the Transformer architecture so powerful and widely applicable! But what if the order of the input is actually important for solving the task, like language modeling? The answer is to encode the position in the input features, which we will take a closer look at later (topic Positional encodings below).
Before moving on to creating the Transformer architecture, we can compare the self-attention operation with our other common layer competitors for sequence data: convolutions and recurrent neural networks. Below you can find a table by Vaswani et al. (2017) on the complexity per layer, the number of sequential operations, and maximum path length. The complexity is measured by the upper bound of the number of operations to perform, while the maximum path length represents the maximum number of steps a forward or backward signal has to traverse to reach any other position. The lower this length, the better gradient signals can backpropagate for long-range dependencies. Let’s take a look at the table below:

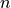 is the sequence length,
is the sequence length, 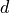 is the representation dimension and
is the representation dimension and 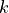 is the kernel size of convolutions. In contrast to recurrent networks, the self-attention layer can parallelize all its operations making it much faster to execute for smaller sequence lengths. However, when the sequence length exceeds the hidden dimensionality, self-attention becomes more expensive than RNNs. One way of reducing the computational cost for long sequences is by restricting the self-attention
to a neighborhood of inputs to attend over, denoted by
is the kernel size of convolutions. In contrast to recurrent networks, the self-attention layer can parallelize all its operations making it much faster to execute for smaller sequence lengths. However, when the sequence length exceeds the hidden dimensionality, self-attention becomes more expensive than RNNs. One way of reducing the computational cost for long sequences is by restricting the self-attention
to a neighborhood of inputs to attend over, denoted by  . Nevertheless, there has been recently a lot of work on more efficient Transformer architectures that still allow long dependencies, of which you can find an overview in the paper by Tay et al. (2020) if interested.
. Nevertheless, there has been recently a lot of work on more efficient Transformer architectures that still allow long dependencies, of which you can find an overview in the paper by Tay et al. (2020) if interested.
Transformer Encoder¶
Next, we will look at how to apply the multi-head attention blog inside the Transformer architecture. Originally, the Transformer model was designed for machine translation. Hence, it got an encoder-decoder structure where the encoder takes as input the sentence in the original language and generates an attention-based representation. On the other hand, the decoder attends over the encoded information and generates the translated sentence in an autoregressive manner, as in a standard RNN. While this structure is extremely useful for Sequence-to-Sequence tasks with the necessity of autoregressive decoding, we will focus here on the encoder part. Many advances in NLP have been made using pure encoder-based Transformer models (if interested, models include the BERT-family, the Vision Transformer, and more), and in our tutorial, we will also mainly focus on the encoder part. If you have understood the encoder architecture, the decoder is a very small step to implement as well. The full Transformer architecture looks as follows (figure credit - Vaswani et al., 2017). :

The encoder consists of 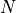 identical blocks that are applied in sequence. Taking as input
identical blocks that are applied in sequence. Taking as input 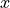 , it is first passed through a Multi-Head Attention block as we have implemented above. The output is added to the original input using a residual connection, and we apply a consecutive Layer Normalization on the sum. Overall, it calculates
, it is first passed through a Multi-Head Attention block as we have implemented above. The output is added to the original input using a residual connection, and we apply a consecutive Layer Normalization on the sum. Overall, it calculates 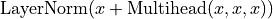 ( being , and input to the attention layer). The residual
connection is crucial in the Transformer architecture for two reasons:
( being , and input to the attention layer). The residual
connection is crucial in the Transformer architecture for two reasons:
Similar to ResNets, Transformers are designed to be very deep. Some models contain more than 24 blocks in the encoder. Hence, the residual connections are crucial for enabling a smooth gradient flow through the model.
Without the residual connection, the information about the original sequence is lost. Remember that the Multi-Head Attention layer ignores the position of elements in a sequence, and can only learn it based on the input features. Removing the residual connections would mean that this information is lost after the first attention layer (after initialization), and with a randomly initialized query and key vector, the output vectors for position
has no relation to its original input.
All outputs of the attention are likely to represent similar/same information, and there is no chance for the model to distinguish which information came from which input element. An alternative option to residual connection would be to fix at least one head to focus on its original input, but this is very inefficient and does not have the benefit of the improved gradient flow.
The Layer Normalization also plays an important role in the Transformer architecture as it enables faster training and provides small regularization. Additionally, it ensures that the features are in a similar magnitude among the elements in the sequence. We are not using Batch Normalization because it depends on the batch size which is often small with Transformers (they require a lot of GPU memory), and BatchNorm has shown to perform particularly bad in language as the features of words tend to have a much higher variance (there are many, very rare words which need to be considered for a good distribution estimate).
Additionally to the Multi-Head Attention, a small fully connected feed-forward network is added to the model, which is applied to each position separately and identically. Specifically, the model uses a Linear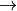 ReLULinear MLP. The full transformation including the residual connection can be expressed as:
ReLULinear MLP. The full transformation including the residual connection can be expressed as:
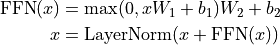
This MLP adds extra complexity to the model and allows transformations on each sequence element separately. You can imagine as this allows the model to “post-process” the new information added by the previous Multi-Head Attention, and prepare it for the next attention block. Usually, the inner dimensionality of the MLP is 2-8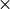 larger than , i.e. the dimensionality of the original input . The general advantage of a wider layer instead of a narrow,
multi-layer MLP is the faster, parallelizable execution.
larger than , i.e. the dimensionality of the original input . The general advantage of a wider layer instead of a narrow,
multi-layer MLP is the faster, parallelizable execution.
Finally, after looking at all parts of the encoder architecture, we can start implementing it below. We first start by implementing a single encoder block. Additionally to the layers described above, we will add dropout layers in the MLP and on the output of the MLP and Multi-Head Attention for regularization.
[7]:
class EncoderBlock(nn.Module):
def __init__(self, input_dim, num_heads, dim_feedforward, dropout=0.0):
"""
Args:
input_dim: Dimensionality of the input
num_heads: Number of heads to use in the attention block
dim_feedforward: Dimensionality of the hidden layer in the MLP
dropout: Dropout probability to use in the dropout layers
"""
super().__init__()
# Attention layer
self.self_attn = MultiheadAttention(input_dim, input_dim, num_heads)
# Two-layer MLP
self.linear_net = nn.Sequential(
nn.Linear(input_dim, dim_feedforward),
nn.Dropout(dropout),
nn.ReLU(inplace=True),
nn.Linear(dim_feedforward, input_dim),
)
# Layers to apply in between the main layers
self.norm1 = nn.LayerNorm(input_dim)
self.norm2 = nn.LayerNorm(input_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Attention part
attn_out = self.self_attn(x, mask=mask)
x = x + self.dropout(attn_out)
x = self.norm1(x)
# MLP part
linear_out = self.linear_net(x)
x = x + self.dropout(linear_out)
x = self.norm2(x)
return x
Based on this block, we can implement a module for the full Transformer encoder. Additionally to a forward function that iterates through the sequence of encoder blocks, we also provide a function called get_attention_maps. The idea of this function is to return the attention probabilities for all Multi-Head Attention blocks in the encoder. This helps us in understanding, and in a sense, explaining the model. However, the attention probabilities should be interpreted with a grain of salt as
it does not necessarily reflect the true interpretation of the model (there is a series of papers about this, including Attention is not Explanation and Attention is not not Explanation).
[8]:
class TransformerEncoder(nn.Module):
def __init__(self, num_layers, **block_args):
super().__init__()
self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ in range(num_layers)])
def forward(self, x, mask=None):
for layer in self.layers:
x = layer(x, mask=mask)
return x
def get_attention_maps(self, x, mask=None):
attention_maps = []
for layer in self.layers:
_, attn_map = layer.self_attn(x, mask=mask, return_attention=True)
attention_maps.append(attn_map)
x = layer(x)
return attention_maps
Positional encoding¶
We have discussed before that the Multi-Head Attention block is permutation-equivariant, and cannot distinguish whether an input comes before another one in the sequence or not. In tasks like language understanding, however, the position is important for interpreting the input words. The position information can therefore be added via the input features. We could learn a embedding for every possible position, but this would not generalize to a dynamical input sequence length. Hence, the better option is to use feature patterns that the network can identify from the features and potentially generalize to larger sequences. The specific pattern chosen by Vaswani et al. are sine and cosine functions of different frequencies, as follows:
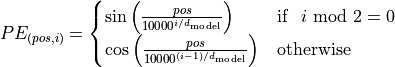
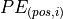 represents the position encoding at position
represents the position encoding at position 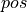 in the sequence, and hidden dimensionality . These values, concatenated for all hidden dimensions, are added to the original input features (in the Transformer visualization above, see “Positional encoding”), and constitute the position information. We distinguish between even (
in the sequence, and hidden dimensionality . These values, concatenated for all hidden dimensions, are added to the original input features (in the Transformer visualization above, see “Positional encoding”), and constitute the position information. We distinguish between even (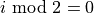 ) and uneven (
) and uneven (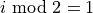 ) hidden dimensionalities where we apply a sine/cosine respectively.
The intuition behind this encoding is that you can represent
) hidden dimensionalities where we apply a sine/cosine respectively.
The intuition behind this encoding is that you can represent 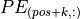 as a linear function of
as a linear function of 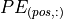 , which might allow the model to easily attend to relative positions. The wavelengths in different dimensions range from
, which might allow the model to easily attend to relative positions. The wavelengths in different dimensions range from 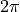 to
to 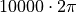 .
.
The positional encoding is implemented below. The code is taken from the PyTorch tutorial about Transformers on NLP and adjusted for our purposes.
[9]:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
"""
Args
d_model: Hidden dimensionality of the input.
max_len: Maximum length of a sequence to expect.
"""
super().__init__()
# Create matrix of [SeqLen, HiddenDim] representing the positional encoding for max_len inputs
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
# register_buffer => Tensor which is not a parameter, but should be part of the modules state.
# Used for tensors that need to be on the same device as the module.
# persistent=False tells PyTorch to not add the buffer to the state dict (e.g. when we save the model)
self.register_buffer("pe", pe, persistent=False)
def forward(self, x):
x = x + self.pe[:, : x.size(1)]
return x
To understand the positional encoding, we can visualize it below. We will generate an image of the positional encoding over hidden dimensionality and position in a sequence. Each pixel, therefore, represents the change of the input feature we perform to encode the specific position. Let’s do it below.
[10]:
encod_block = PositionalEncoding(d_model=48, max_len=96)
pe = encod_block.pe.squeeze().T.cpu().numpy()
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 3))
pos = ax.imshow(pe, cmap="RdGy", extent=(1, pe.shape[1] + 1, pe.shape[0] + 1, 1))
fig.colorbar(pos, ax=ax)
ax.set_xlabel("Position in sequence")
ax.set_ylabel("Hidden dimension")
ax.set_title("Positional encoding over hidden dimensions")
ax.set_xticks([1] + [i * 10 for i in range(1, 1 + pe.shape[1] // 10)])
ax.set_yticks([1] + [i * 10 for i in range(1, 1 + pe.shape[0] // 10)])
plt.show()

You can clearly see the sine and cosine waves with different wavelengths that encode the position in the hidden dimensions. Specifically, we can look at the sine/cosine wave for each hidden dimension separately, to get a better intuition of the pattern. Below we visualize the positional encoding for the hidden dimensions , 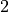 ,
, 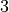 and
and 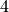 .
.
[11]:
sns.set_theme()
fig, ax = plt.subplots(2, 2, figsize=(12, 4))
ax = [a for a_list in ax for a in a_list]
for i in range(len(ax)):
ax[i].plot(np.arange(1, 17), pe[i, :16], color="C%i" % i, marker="o", markersize=6, markeredgecolor="black")
ax[i].set_title("Encoding in hidden dimension %i" % (i + 1))
ax[i].set_xlabel("Position in sequence", fontsize=10)
ax[i].set_ylabel("Positional encoding", fontsize=10)
ax[i].set_xticks(np.arange(1, 17))
ax[i].tick_params(axis="both", which="major", labelsize=10)
ax[i].tick_params(axis="both", which="minor", labelsize=8)
ax[i].set_ylim(-1.2, 1.2)
fig.subplots_adjust(hspace=0.8)
sns.reset_orig()
plt.show()

As we can see, the patterns between the hidden dimension and only differ in the starting angle. The wavelength is , hence the repetition after position 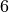 . The hidden dimensions and have about twice the wavelength.
. The hidden dimensions and have about twice the wavelength.
Learning rate warm-up¶
One commonly used technique for training a Transformer is learning rate warm-up. This means that we gradually increase the learning rate from 0 on to our originally specified learning rate in the first few iterations. Thus, we slowly start learning instead of taking very large steps from the beginning. In fact, training a deep Transformer without learning rate warm-up can make the model diverge and achieve a much worse performance on training and testing. Take for instance the following plot by Liu et al. (2019) comparing Adam-vanilla (i.e. Adam without warm-up) vs Adam with a warm-up:

Clearly, the warm-up is a crucial hyperparameter in the Transformer architecture. Why is it so important? There are currently two common explanations. Firstly, Adam uses the bias correction factors which however can lead to a higher variance in the adaptive learning rate during the first iterations. Improved optimizers like RAdam have been shown to overcome this issue, not requiring warm-up for training Transformers. Secondly, the iteratively applied Layer Normalization across layers can lead to very high gradients during the first iterations, which can be solved by using Pre-Layer Normalization (similar to Pre-Activation ResNet), or replacing Layer Normalization by other techniques (Adaptive Normalization, Power Normalization).
Nevertheless, many applications and papers still use the original Transformer architecture with Adam, because warm-up is a simple, yet effective way of solving the gradient problem in the first iterations. There are many different schedulers we could use. For instance, the original Transformer paper used an exponential decay scheduler with a warm-up. However, the currently most popular scheduler is the cosine warm-up scheduler, which combines warm-up with a cosine-shaped learning rate decay. We can implement it below, and visualize the learning rate factor over epochs.
[12]:
class CosineWarmupScheduler(optim.lr_scheduler._LRScheduler):
def __init__(self, optimizer, warmup, max_iters):
self.warmup = warmup
self.max_num_iters = max_iters
super().__init__(optimizer)
def get_lr(self):
lr_factor = self.get_lr_factor(epoch=self.last_epoch)
return [base_lr * lr_factor for base_lr in self.base_lrs]
def get_lr_factor(self, epoch):
lr_factor = 0.5 * (1 + np.cos(np.pi * epoch / self.max_num_iters))
if epoch <= self.warmup:
lr_factor *= epoch * 1.0 / self.warmup
return lr_factor
[13]:
# Needed for initializing the lr scheduler
p = nn.Parameter(torch.empty(4, 4))
optimizer = optim.Adam([p], lr=1e-3)
lr_scheduler = CosineWarmupScheduler(optimizer=optimizer, warmup=100, max_iters=2000)
# Plotting
epochs = list(range(2000))
sns.set()
plt.figure(figsize=(8, 3))
plt.plot(epochs, [lr_scheduler.get_lr_factor(e) for e in epochs])
plt.ylabel("Learning rate factor")
plt.xlabel("Iterations (in batches)")
plt.title("Cosine Warm-up Learning Rate Scheduler")
plt.show()
sns.reset_orig()

In the first 100 iterations, we increase the learning rate factor from 0 to 1, whereas for all later iterations, we decay it using the cosine wave. Pre-implementations of this scheduler can be found in the popular NLP Transformer library huggingface.
PyTorch Lightning Module¶
Finally, we can embed the Transformer architecture into a PyTorch lightning module. From Tutorial 5, you know that PyTorch Lightning simplifies our training and test code, as well as structures the code nicely in separate functions. We will implement a template for a classifier based on the Transformer encoder. Thereby, we have a prediction output per sequence element. If we would need a classifier over the whole sequence, the common approach is to add an additional [CLS] token to the
sequence, representing the classifier token. However, here we focus on tasks where we have an output per element.
Additionally to the Transformer architecture, we add a small input network (maps input dimensions to model dimensions), the positional encoding, and an output network (transforms output encodings to predictions). We also add the learning rate scheduler, which takes a step each iteration instead of once per epoch. This is needed for the warmup and the smooth cosine decay. The training, validation, and test step is left empty for now and will be filled for our task-specific models.
[14]:
class TransformerPredictor(L.LightningModule):
def __init__(
self,
input_dim,
model_dim,
num_classes,
num_heads,
num_layers,
lr,
warmup,
max_iters,
dropout=0.0,
input_dropout=0.0,
):
"""
Args:
input_dim: Hidden dimensionality of the input
model_dim: Hidden dimensionality to use inside the Transformer
num_classes: Number of classes to predict per sequence element
num_heads: Number of heads to use in the Multi-Head Attention blocks
num_layers: Number of encoder blocks to use.
lr: Learning rate in the optimizer
warmup: Number of warmup steps. Usually between 50 and 500
max_iters: Number of maximum iterations the model is trained for. This is needed for the CosineWarmup scheduler
dropout: Dropout to apply inside the model
input_dropout: Dropout to apply on the input features
"""
super().__init__()
self.save_hyperparameters()
self._create_model()
def _create_model(self):
# Input dim -> Model dim
self.input_net = nn.Sequential(
nn.Dropout(self.hparams.input_dropout), nn.Linear(self.hparams.input_dim, self.hparams.model_dim)
)
# Positional encoding for sequences
self.positional_encoding = PositionalEncoding(d_model=self.hparams.model_dim)
# Transformer
self.transformer = TransformerEncoder(
num_layers=self.hparams.num_layers,
input_dim=self.hparams.model_dim,
dim_feedforward=2 * self.hparams.model_dim,
num_heads=self.hparams.num_heads,
dropout=self.hparams.dropout,
)
# Output classifier per sequence lement
self.output_net = nn.Sequential(
nn.Linear(self.hparams.model_dim, self.hparams.model_dim),
nn.LayerNorm(self.hparams.model_dim),
nn.ReLU(inplace=True),
nn.Dropout(self.hparams.dropout),
nn.Linear(self.hparams.model_dim, self.hparams.num_classes),
)
def forward(self, x, mask=None, add_positional_encoding=True):
"""
Args:
x: Input features of shape [Batch, SeqLen, input_dim]
mask: Mask to apply on the attention outputs (optional)
add_positional_encoding: If True, we add the positional encoding to the input.
Might not be desired for some tasks.
"""
x = self.input_net(x)
if add_positional_encoding:
x = self.positional_encoding(x)
x = self.transformer(x, mask=mask)
x = self.output_net(x)
return x
@torch.no_grad()
def get_attention_maps(self, x, mask=None, add_positional_encoding=True):
"""Function for extracting the attention matrices of the whole Transformer for a single batch.
Input arguments same as the forward pass.
"""
x = self.input_net(x)
if add_positional_encoding:
x = self.positional_encoding(x)
attention_maps = self.transformer.get_attention_maps(x, mask=mask)
return attention_maps
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.hparams.lr)
# We don't return the lr scheduler because we need to apply it per iteration, not per epoch
self.lr_scheduler = CosineWarmupScheduler(
optimizer, warmup=self.hparams.warmup, max_iters=self.hparams.max_iters
)
return optimizer
def optimizer_step(self, *args, **kwargs):
super().optimizer_step(*args, **kwargs)
self.lr_scheduler.step() # Step per iteration
def training_step(self, batch, batch_idx):
raise NotImplementedError
def validation_step(self, batch, batch_idx):
raise NotImplementedError
def test_step(self, batch, batch_idx):
raise NotImplementedError
Experiments¶
After having finished the implementation of the Transformer architecture, we can start experimenting and apply it to various tasks. In this notebook, we will focus on two tasks: parallel Sequence-to-Sequence, and set anomaly detection. The two tasks focus on different properties of the Transformer architecture, and we go through them below.
Sequence to Sequence¶
A Sequence-to-Sequence task represents a task where the input and the output is a sequence, not necessarily of the same length. Popular tasks in this domain include machine translation and summarization. For this, we usually have a Transformer encoder for interpreting the input sequence, and a decoder for generating the output in an autoregressive manner. Here, however, we will go back to a much simpler example task and use only the encoder. Given a sequence of numbers between
and 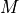 , the task is to reverse the input sequence. In Numpy notation, if our input is , the output should be [::-1]. Although this task sounds very simple, RNNs can have issues with such because the task requires long-term dependencies. Transformers are built to support such, and hence, we expect it to perform very well.
, the task is to reverse the input sequence. In Numpy notation, if our input is , the output should be [::-1]. Although this task sounds very simple, RNNs can have issues with such because the task requires long-term dependencies. Transformers are built to support such, and hence, we expect it to perform very well.
First, let’s create a dataset class below.
[15]:
class ReverseDataset(data.Dataset):
def __init__(self, num_categories, seq_len, size):
super().__init__()
self.num_categories = num_categories
self.seq_len = seq_len
self.size = size
self.data = torch.randint(self.num_categories, size=(self.size, self.seq_len))
def __len__(self):
return self.size
def __getitem__(self, idx):
inp_data = self.data[idx]
labels = torch.flip(inp_data, dims=(0,))
return inp_data, labels
We create an arbitrary number of random sequences of numbers between 0 and num_categories-1. The label is simply the tensor flipped over the sequence dimension. We can create the corresponding data loaders below.
[16]:
dataset = partial(ReverseDataset, 10, 16)
train_loader = data.DataLoader(dataset(50000), batch_size=128, shuffle=True, drop_last=True, pin_memory=True)
val_loader = data.DataLoader(dataset(1000), batch_size=128)
test_loader = data.DataLoader(dataset(10000), batch_size=128)
Let’s look at an arbitrary sample of the dataset:
[17]:
inp_data, labels = train_loader.dataset[0]
print("Input data:", inp_data)
print("Labels: ", labels)
Input data: tensor([9, 6, 2, 0, 6, 2, 7, 9, 7, 3, 3, 4, 3, 7, 0, 9])
Labels: tensor([9, 0, 7, 3, 4, 3, 3, 7, 9, 7, 2, 6, 0, 2, 6, 9])
During training, we pass the input sequence through the Transformer encoder and predict the output for each input token. We use the standard Cross-Entropy loss to perform this. Every number is represented as a one-hot vector. Remember that representing the categories as single scalars decreases the expressiveness of the model extremely as and are not closer related than and 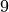 in our example. An alternative to a one-hot vector is using a learned embedding
vector as it is provided by the PyTorch module
in our example. An alternative to a one-hot vector is using a learned embedding
vector as it is provided by the PyTorch module nn.Embedding. However, using a one-hot vector with an additional linear layer as in our case has the same effect as an embedding layer (self.input_net maps one-hot vector to a dense vector, where each row of the weight matrix represents the embedding for a specific category).
To implement the training dynamic, we create a new class inheriting from TransformerPredictor and overwriting the training, validation and test step functions.
[18]:
class ReversePredictor(TransformerPredictor):
def _calculate_loss(self, batch, mode="train"):
# Fetch data and transform categories to one-hot vectors
inp_data, labels = batch
inp_data = F.one_hot(inp_data, num_classes=self.hparams.num_classes).float()
# Perform prediction and calculate loss and accuracy
preds = self.forward(inp_data, add_positional_encoding=True)
loss = F.cross_entropy(preds.view(-1, preds.size(-1)), labels.view(-1))
acc = (preds.argmax(dim=-1) == labels).float().mean()
# Logging
self.log("%s_loss" % mode, loss)
self.log("%s_acc" % mode, acc)
return loss, acc
def training_step(self, batch, batch_idx):
loss, _ = self._calculate_loss(batch, mode="train")
return loss
def validation_step(self, batch, batch_idx):
_ = self._calculate_loss(batch, mode="val")
def test_step(self, batch, batch_idx):
_ = self._calculate_loss(batch, mode="test")
Finally, we can create a training function similar to the one we have seen in Tutorial 5 for PyTorch Lightning. We create a L.Trainer object, running for epochs, logging in TensorBoard, and saving our best model based on the validation. Afterward, we test our models on the test set. An additional parameter we pass to the trainer here is gradient_clip_val. This clips the norm of the gradients for all parameters before taking an optimizer step and prevents the model from
diverging if we obtain very high gradients at, for instance, sharp loss surfaces (see many good blog posts on gradient clipping, like DeepAI glossary). For Transformers, gradient clipping can help to further stabilize the training during the first few iterations, and also afterward. In plain PyTorch, you can apply gradient clipping via torch.nn.utils.clip_grad_norm_(...) (see
documentation). The clip value is usually between 0.5 and 10, depending on how harsh you want to clip large gradients. After having explained this, let’s implement the training function:
[19]:
def train_reverse(**kwargs):
# Create a PyTorch Lightning trainer with the generation callback
root_dir = os.path.join(CHECKPOINT_PATH, "ReverseTask")
os.makedirs(root_dir, exist_ok=True)
trainer = L.Trainer(
default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="auto",
devices=1,
max_epochs=10,
gradient_clip_val=5,
)
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ReverseTask.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = ReversePredictor.load_from_checkpoint(pretrained_filename)
else:
model = ReversePredictor(max_iters=trainer.max_epochs * len(train_loader), **kwargs)
trainer.fit(model, train_loader, val_loader)
# Test best model on validation and test set
val_result = trainer.test(model, dataloaders=val_loader, verbose=False)
test_result = trainer.test(model, dataloaders=test_loader, verbose=False)
result = {"test_acc": test_result[0]["test_acc"], "val_acc": val_result[0]["test_acc"]}
model = model.to(device)
return model, result
Finally, we can train the model. In this setup, we will use a single encoder block and a single head in the Multi-Head Attention. This is chosen because of the simplicity of the task, and in this case, the attention can actually be interpreted as an “explanation” of the predictions (compared to the other papers above dealing with deep Transformers).
[20]:
reverse_model, reverse_result = train_reverse(
input_dim=train_loader.dataset.num_categories,
model_dim=32,
num_heads=1,
num_classes=train_loader.dataset.num_categories,
num_layers=1,
dropout=0.0,
lr=5e-4,
warmup=50,
)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Lightning automatically upgraded your loaded checkpoint from v1.0.2 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/Transformers/ReverseTask.ckpt`
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/Transformers/ReverseTask/lightning_logs
Found pretrained model, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
/usr/local/lib/python3.9/dist-packages/lightning/pytorch/trainer/connectors/data_connector.py:208: PossibleUserWarning: The dataloader, test_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 64 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
The warning of PyTorch Lightning regarding the number of workers can be ignored for now. As the data set is so simple and the __getitem__ finishes a neglectable time, we don’t need subprocesses to provide us the data (in fact, more workers can slow down the training as we have communication overhead among processes/threads). First, let’s print the results:
[21]:
print("Val accuracy: %4.2f%%" % (100.0 * reverse_result["val_acc"]))
print("Test accuracy: %4.2f%%" % (100.0 * reverse_result["test_acc"]))
Val accuracy: 100.00%
Test accuracy: 100.00%
As we would have expected, the Transformer can correctly solve the task. However, how does the attention in the Multi-Head Attention block looks like for an arbitrary input? Let’s try to visualize it below.
[22]:
data_input, labels = next(iter(val_loader))
inp_data = F.one_hot(data_input, num_classes=reverse_model.hparams.num_classes).float()
inp_data = inp_data.to(device)
attention_maps = reverse_model.get_attention_maps(inp_data)
The object attention_maps is a list of length where is the number of layers. Each element is a tensor of shape [Batch, Heads, SeqLen, SeqLen], which we can verify below.
[23]:
attention_maps[0].shape
[23]:
torch.Size([128, 1, 16, 16])
Next, we will write a plotting function that takes as input the sequences, attention maps, and an index indicating for which batch element we want to visualize the attention map. We will create a plot where over rows, we have different layers, while over columns, we show the different heads. Remember that the softmax has been applied for each row separately.
[24]:
def plot_attention_maps(input_data, attn_maps, idx=0):
if input_data is not None:
input_data = input_data[idx].detach().cpu().numpy()
else:
input_data = np.arange(attn_maps[0][idx].shape[-1])
attn_maps = [m[idx].detach().cpu().numpy() for m in attn_maps]
num_heads = attn_maps[0].shape[0]
num_layers = len(attn_maps)
seq_len = input_data.shape[0]
fig_size = 4 if num_heads == 1 else 3
fig, ax = plt.subplots(num_layers, num_heads, figsize=(num_heads * fig_size, num_layers * fig_size))
if num_layers == 1:
ax = [ax]
if num_heads == 1:
ax = [[a] for a in ax]
for row in range(num_layers):
for column in range(num_heads):
ax[row][column].imshow(attn_maps[row][column], origin="lower", vmin=0)
ax[row][column].set_xticks(list(range(seq_len)))
ax[row][column].set_xticklabels(input_data.tolist())
ax[row][column].set_yticks(list(range(seq_len)))
ax[row][column].set_yticklabels(input_data.tolist())
ax[row][column].set_title("Layer %i, Head %i" % (row + 1, column + 1))
fig.subplots_adjust(hspace=0.5)
plt.show()
Finally, we can plot the attention map of our trained Transformer on the reverse task:
[25]:
plot_attention_maps(data_input, attention_maps, idx=0)

The model has learned to attend to the token that is on the flipped index of itself. Hence, it actually does what we intended it to do. We see that it however also pays some attention to values close to the flipped index. This is because the model doesn’t need the perfect, hard attention to solve this problem, but is fine with this approximate, noisy attention map. The close-by indices are caused by the similarity of the positional encoding, which we also intended with the positional encoding.
Set Anomaly Detection¶
Besides sequences, sets are another data structure that is relevant for many applications. In contrast to sequences, elements are unordered in a set. RNNs can only be applied on sets by assuming an order in the data, which however biases the model towards a non-existing order in the data. Vinyals et al. (2015) and other papers have shown that the assumed order can have a significant impact on the model’s performance, and hence, we should try to not use RNNs on sets. Ideally, our model should be permutation-equivariant/invariant such that the output is the same no matter how we sort the elements in a set.
Transformers offer the perfect architecture for this as the Multi-Head Attention is permutation-equivariant, and thus, outputs the same values no matter in what order we enter the inputs (inputs and outputs are permuted equally). The task we are looking at for sets is Set Anomaly Detection which means that we try to find the element(s) in a set that does not fit the others. In the research community, the common application of anomaly detection is performed on a set of images, where 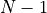 images belong to the same category/have the same high-level features while one belongs to another category. Note that category does not necessarily have to relate to a class in a standard classification problem, but could be the combination of multiple features. For instance, on a face dataset, this could be people with glasses, male, beard, etc. An example of distinguishing different animals can be seen below. The first four images show foxes, while the last represents a different animal. We
want to recognize that the last image shows a different animal, but it is not relevant which class of animal it is.
images belong to the same category/have the same high-level features while one belongs to another category. Note that category does not necessarily have to relate to a class in a standard classification problem, but could be the combination of multiple features. For instance, on a face dataset, this could be people with glasses, male, beard, etc. An example of distinguishing different animals can be seen below. The first four images show foxes, while the last represents a different animal. We
want to recognize that the last image shows a different animal, but it is not relevant which class of animal it is.

In this tutorial, we will use the CIFAR100 dataset. CIFAR100 has 600 images for 100 classes each with a resolution of 32x32, similar to CIFAR10. The larger amount of classes requires the model to attend to specific features in the images instead of coarse features as in CIFAR10, therefore making the task harder. We will show the model a set of 9 images of one class, and 1 image from another class. The task is to find the image that is from a different class than the other images. Using the raw images directly as input to the Transformer is not a good idea, because it is not translation invariant as a CNN, and would need to learn to detect image features from high-dimensional input first of all. Instead, we will use a pre-trained ResNet34 model from the torchvision package to obtain high-level, low-dimensional features of the images. The ResNet model has been pre-trained on the ImageNet dataset which contains 1 million images of 1k classes and varying resolutions. However, during training and testing, the images are usually scaled to a resolution of 224x224, and hence we rescale our CIFAR images to this resolution as well. Below, we will load the dataset, and prepare the data for being processed by the ResNet model.
[26]:
# ImageNet statistics
DATA_MEANS = np.array([0.485, 0.456, 0.406])
DATA_STD = np.array([0.229, 0.224, 0.225])
# As torch tensors for later preprocessing
TORCH_DATA_MEANS = torch.from_numpy(DATA_MEANS).view(1, 3, 1, 1)
TORCH_DATA_STD = torch.from_numpy(DATA_STD).view(1, 3, 1, 1)
# Resize to 224x224, and normalize to ImageNet statistic
transform = transforms.Compose(
[transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(DATA_MEANS, DATA_STD)]
)
# Loading the training dataset.
train_set = CIFAR100(root=DATASET_PATH, train=True, transform=transform, download=True)
# Loading the test set
test_set = CIFAR100(root=DATASET_PATH, train=False, transform=transform, download=True)
Downloading https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz to /__w/14/s/.datasets/cifar-100-python.tar.gz
Extracting /__w/14/s/.datasets/cifar-100-python.tar.gz to /__w/14/s/.datasets
Files already downloaded and verified
Next, we want to run the pre-trained ResNet model on the images, and extract the features before the classification layer. These are the most high-level features, and should sufficiently describe the images. CIFAR100 has some similarity to ImageNet, and thus we are not retraining the ResNet model in any form. However, if you would want to get the best performance and have a very large dataset, it would be better to add the ResNet to the computation graph during training and finetune its parameters as well. As we don’t have a large enough dataset and want to train our model efficiently, we will extract the features beforehand. Let’s load and prepare the model below.
[27]:
os.environ["TORCH_HOME"] = CHECKPOINT_PATH
pretrained_model = torchvision.models.resnet34(pretrained=True)
# Remove classification layer
# In some models, it is called "fc", others have "classifier"
# Setting both to an empty sequential represents an identity map of the final features.
pretrained_model.fc = nn.Sequential()
pretrained_model.classifier = nn.Sequential()
# To GPU
pretrained_model = pretrained_model.to(device)
# Only eval, no gradient required
pretrained_model.eval()
for p in pretrained_model.parameters():
p.requires_grad = False
/usr/local/lib/python3.9/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.9/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=ResNet34_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet34_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/resnet34-b627a593.pth" to saved_models/Transformers/hub/checkpoints/resnet34-b627a593.pth
We will now write a extraction function for the features below. This cell requires access to a GPU, as the model is rather deep and the images relatively large. The GPUs on GoogleColab are sufficient, but running this cell can take 2-3 minutes. Once it is run, the features are exported on disk so they don’t have to be recalculated every time you run the notebook. However, this requires >150MB free disk space. So it is recommended to run this only on a local computer if you have enough free disk and a GPU (GoogleColab is fine for this). If you do not have a GPU, you can download the features from the GoogleDrive folder.
[28]:
@torch.no_grad()
def extract_features(dataset, save_file):
if not os.path.isfile(save_file):
data_loader = data.DataLoader(dataset, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
extracted_features = []
for imgs, _ in tqdm(data_loader):
imgs = imgs.to(device)
feats = pretrained_model(imgs)
extracted_features.append(feats)
extracted_features = torch.cat(extracted_features, dim=0)
extracted_features = extracted_features.detach().cpu()
torch.save(extracted_features, save_file)
else:
extracted_features = torch.load(save_file)
return extracted_features
train_feat_file = os.path.join(CHECKPOINT_PATH, "train_set_features.tar")
train_set_feats = extract_features(train_set, train_feat_file)
test_feat_file = os.path.join(CHECKPOINT_PATH, "test_set_features.tar")
test_feats = extract_features(test_set, test_feat_file)
Let’s verify the feature shapes below. The training should have 50k elements, and the test 10k images. The feature dimension is 512 for the ResNet34. If you experiment with other models, you likely see a different feature dimension.
[29]:
print("Train:", train_set_feats.shape)
print("Test: ", test_feats.shape)
Train: torch.Size([50000, 512])
Test: torch.Size([10000, 512])
As usual, we want to create a validation set to detect when we should stop training. In this case, we will split the training set into 90% training, 10% validation. However, the difficulty is here that we need to ensure that the validation set has the same number of images for all 100 labels. Otherwise, we have a class imbalance which is not good for creating the image sets. Hence, we take 10% of the images for each class, and move them into the validation set. The code below does exactly this.
[30]:
# Split train into train+val
# Get labels from train set
labels = train_set.targets
# Get indices of images per class
labels = torch.LongTensor(labels)
num_labels = labels.max() + 1
sorted_indices = torch.argsort(labels).reshape(num_labels, -1) # [classes, num_imgs per class]
# Determine number of validation images per class
num_val_exmps = sorted_indices.shape[1] // 10
# Get image indices for validation and training
val_indices = sorted_indices[:, :num_val_exmps].reshape(-1)
train_indices = sorted_indices[:, num_val_exmps:].reshape(-1)
# Group corresponding image features and labels
train_feats, train_labels = train_set_feats[train_indices], labels[train_indices]
val_feats, val_labels = train_set_feats[val_indices], labels[val_indices]
Now we can prepare a dataset class for the set anomaly task. We define an epoch to be the sequence in which each image has been exactly once as an “anomaly”. Hence, the length of the dataset is the number of images in it. For the training set, each time we access an item with __getitem__, we sample a random, different class than the image at the corresponding index idx has. In a second step, we sample images of this sampled class. The set of 10 images is finally returned. The
randomness in the __getitem__ allows us to see a slightly different set during each iteration. However, we can’t use the same strategy for the test set as we want the test dataset to be the same every time we iterate over it. Hence, we sample the sets in the __init__ method, and return those in __getitem__. The code below implements exactly this dynamic.
[31]:
class SetAnomalyDataset(data.Dataset):
def __init__(self, img_feats, labels, set_size=10, train=True):
"""
Args:
img_feats: Tensor of shape [num_imgs, img_dim]. Represents the high-level features.
labels: Tensor of shape [num_imgs], containing the class labels for the images
set_size: Number of elements in a set. N-1 are sampled from one class, and one from another one.
train: If True, a new set will be sampled every time __getitem__ is called.
"""
super().__init__()
self.img_feats = img_feats
self.labels = labels
self.set_size = set_size - 1 # The set size is here the size of correct images
self.train = train
# Tensors with indices of the images per class
self.num_labels = labels.max() + 1
self.img_idx_by_label = torch.argsort(self.labels).reshape(self.num_labels, -1)
if not train:
self.test_sets = self._create_test_sets()
def _create_test_sets(self):
# Pre-generates the sets for each image for the test set
test_sets = []
num_imgs = self.img_feats.shape[0]
np.random.seed(42)
test_sets = [self.sample_img_set(self.labels[idx]) for idx in range(num_imgs)]
test_sets = torch.stack(test_sets, dim=0)
return test_sets
def sample_img_set(self, anomaly_label):
"""Samples a new set of images, given the label of the anomaly.
The sampled images come from a different class than anomaly_label
"""
# Sample class from 0,...,num_classes-1 while skipping anomaly_label as class
set_label = np.random.randint(self.num_labels - 1)
if set_label >= anomaly_label:
set_label += 1
# Sample images from the class determined above
img_indices = np.random.choice(self.img_idx_by_label.shape[1], size=self.set_size, replace=False)
img_indices = self.img_idx_by_label[set_label, img_indices]
return img_indices
def __len__(self):
return self.img_feats.shape[0]
def __getitem__(self, idx):
anomaly = self.img_feats[idx]
if self.train: # If train => sample
img_indices = self.sample_img_set(self.labels[idx])
else: # If test => use pre-generated ones
img_indices = self.test_sets[idx]
# Concatenate images. The anomaly is always the last image for simplicity
img_set = torch.cat([self.img_feats[img_indices], anomaly[None]], dim=0)
indices = torch.cat([img_indices, torch.LongTensor([idx])], dim=0)
label = img_set.shape[0] - 1
# We return the indices of the images for visualization purpose. "Label" is the index of the anomaly
return img_set, indices, label
Next, we can setup our datasets and data loaders below. Here, we will use a set size of 10, i.e. 9 images from one category + 1 anomaly. Feel free to change it if you want to experiment with the sizes.
[32]:
SET_SIZE = 10
test_labels = torch.LongTensor(test_set.targets)
train_anom_dataset = SetAnomalyDataset(train_feats, train_labels, set_size=SET_SIZE, train=True)
val_anom_dataset = SetAnomalyDataset(val_feats, val_labels, set_size=SET_SIZE, train=False)
test_anom_dataset = SetAnomalyDataset(test_feats, test_labels, set_size=SET_SIZE, train=False)
train_anom_loader = data.DataLoader(
train_anom_dataset, batch_size=64, shuffle=True, drop_last=True, num_workers=4, pin_memory=True
)
val_anom_loader = data.DataLoader(val_anom_dataset, batch_size=64, shuffle=False, drop_last=False, num_workers=4)
test_anom_loader = data.DataLoader(test_anom_dataset, batch_size=64, shuffle=False, drop_last=False, num_workers=4)
To understand the dataset a little better, we can plot below a few sets from the test dataset. Each row shows a different input set, where the first 9 are from the same class.
[33]:
def visualize_exmp(indices, orig_dataset):
images = [orig_dataset[idx][0] for idx in indices.reshape(-1)]
images = torch.stack(images, dim=0)
images = images * TORCH_DATA_STD + TORCH_DATA_MEANS
img_grid = torchvision.utils.make_grid(images, nrow=SET_SIZE, normalize=True, pad_value=0.5, padding=16)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(12, 8))
plt.title("Anomaly examples on CIFAR100")
plt.imshow(img_grid)
plt.axis("off")
plt.show()
plt.close()
_, indices, _ = next(iter(test_anom_loader))
visualize_exmp(indices[:4], test_set)

We can already see that for some sets the task might be easier than for others. Difficulties can especially arise if the anomaly is in a different, but yet visually similar class (e.g. train vs bus, flour vs worm, etc. ).
After having prepared the data, we can look closer at the model. Here, we have a classification of the whole set. For the prediction to be permutation-equivariant, we will output one logit for each image. Over these logits, we apply a softmax and train the anomaly image to have the highest score/probability. This is a bit different than a standard classification layer as the softmax is applied over images, not over output classes in the classical sense. However, if we swap two images in their position, we effectively swap their position in the output softmax. Hence, the prediction is equivariant with respect to the input. We implement this idea below in the subclass of the Transformer Lightning module.
[34]:
class AnomalyPredictor(TransformerPredictor):
def _calculate_loss(self, batch, mode="train"):
img_sets, _, labels = batch
# No positional encodings as it is a set, not a sequence!
preds = self.forward(img_sets, add_positional_encoding=False)
preds = preds.squeeze(dim=-1) # Shape: [Batch_size, set_size]
loss = F.cross_entropy(preds, labels) # Softmax/CE over set dimension
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log("%s_loss" % mode, loss)
self.log("%s_acc" % mode, acc, on_step=False, on_epoch=True)
return loss, acc
def training_step(self, batch, batch_idx):
loss, _ = self._calculate_loss(batch, mode="train")
return loss
def validation_step(self, batch, batch_idx):
_ = self._calculate_loss(batch, mode="val")
def test_step(self, batch, batch_idx):
_ = self._calculate_loss(batch, mode="test")
Finally, we write our train function below. It has the exact same structure as the reverse task one, hence not much of an explanation is needed here.
[35]:
def train_anomaly(**kwargs):
# Create a PyTorch Lightning trainer with the generation callback
root_dir = os.path.join(CHECKPOINT_PATH, "SetAnomalyTask")
os.makedirs(root_dir, exist_ok=True)
trainer = L.Trainer(
default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="auto",
devices=1,
max_epochs=100,
gradient_clip_val=2,
)
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "SetAnomalyTask.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = AnomalyPredictor.load_from_checkpoint(pretrained_filename)
else:
model = AnomalyPredictor(max_iters=trainer.max_epochs * len(train_anom_loader), **kwargs)
trainer.fit(model, train_anom_loader, val_anom_loader)
model = AnomalyPredictor.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on validation and test set
train_result = trainer.test(model, dataloaders=train_anom_loader, verbose=False)
val_result = trainer.test(model, dataloaders=val_anom_loader, verbose=False)
test_result = trainer.test(model, dataloaders=test_anom_loader, verbose=False)
result = {
"test_acc": test_result[0]["test_acc"],
"val_acc": val_result[0]["test_acc"],
"train_acc": train_result[0]["test_acc"],
}
model = model.to(device)
return model, result
Let’s finally train our model. We will use 4 layers with 4 attention heads each. The hidden dimensionality of the model is 256, and we use a dropout of 0.1 throughout the model for good regularization. Note that we also apply the dropout on the input features, as this makes the model more robust against image noise and generalizes better. Again, we use warmup to slowly start our model training.
[36]:
anomaly_model, anomaly_result = train_anomaly(
input_dim=train_anom_dataset.img_feats.shape[-1],
model_dim=256,
num_heads=4,
num_classes=1,
num_layers=4,
dropout=0.1,
input_dropout=0.1,
lr=5e-4,
warmup=100,
)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Lightning automatically upgraded your loaded checkpoint from v1.0.2 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/Transformers/SetAnomalyTask.ckpt`
Found pretrained model, loading...
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/Transformers/SetAnomalyTask/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
/usr/local/lib/python3.9/dist-packages/lightning/pytorch/trainer/connectors/data_connector.py:326: PossibleUserWarning: Your `test_dataloader`'s sampler has shuffling enabled, it is strongly recommended that you turn shuffling off for val/test/predict dataloaders.
rank_zero_warn(
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
We can print the achieved accuracy below.
[37]:
print("Train accuracy: %4.2f%%" % (100.0 * anomaly_result["train_acc"]))
print("Val accuracy: %4.2f%%" % (100.0 * anomaly_result["val_acc"]))
print("Test accuracy: %4.2f%%" % (100.0 * anomaly_result["test_acc"]))
Train accuracy: 96.45%
Val accuracy: 95.94%
Test accuracy: 94.42%
With ~94% validation and test accuracy, the model generalizes quite well. It should be noted that you might see slightly different scores depending on what computer/device you are running this notebook. This is because despite setting the seed before generating the test dataset, it is not the same across platforms and numpy versions. Nevertheless, we can conclude that the model performs quite well and can solve the task for most sets. Before trying to interpret the model, let’s verify that our model is permutation-equivariant, and assigns the same predictions for different permutations of the input set. For this, we sample a batch from the test set and run it through the model to obtain the probabilities.
[38]:
inp_data, indices, labels = next(iter(test_anom_loader))
inp_data = inp_data.to(device)
anomaly_model.eval()
with torch.no_grad():
preds = anomaly_model.forward(inp_data, add_positional_encoding=False)
preds = F.softmax(preds.squeeze(dim=-1), dim=-1)
# Permut input data
permut = np.random.permutation(inp_data.shape[1])
perm_inp_data = inp_data[:, permut]
perm_preds = anomaly_model.forward(perm_inp_data, add_positional_encoding=False)
perm_preds = F.softmax(perm_preds.squeeze(dim=-1), dim=-1)
assert (preds[:, permut] - perm_preds).abs().max() < 1e-5, "Predictions are not permutation equivariant"
print("Preds\n", preds[0, permut].cpu().numpy())
print("Permuted preds\n", perm_preds[0].cpu().numpy())
Preds
[2.7652273e-05 1.8945755e-05 1.7359460e-05 2.7821090e-05 1.6118418e-05
1.6986007e-05 5.7171139e-05 9.9977809e-01 2.1328320e-05 1.8650126e-05]
Permuted preds
[2.7652244e-05 1.8945753e-05 1.7359458e-05 2.7821086e-05 1.6118402e-05
1.6985972e-05 5.7171132e-05 9.9977797e-01 2.1328318e-05 1.8650106e-05]
You can see that the predictions are almost exactly the same, and only differ because of slight numerical differences inside the network operation.
To interpret the model a little more, we can plot the attention maps inside the model. This will give us an idea of what information the model is sharing/communicating between images, and what each head might represent. First, we need to extract the attention maps for the test batch above, and determine the discrete predictions for simplicity.
[39]:
attention_maps = anomaly_model.get_attention_maps(inp_data, add_positional_encoding=False)
predictions = preds.argmax(dim=-1)
Below we write a plot function which plots the images in the input set, the prediction of the model, and the attention maps of the different heads on layers of the transformer. Feel free to explore the attention maps for different input examples as well.
[40]:
def visualize_prediction(idx):
visualize_exmp(indices[idx : idx + 1], test_set)
print("Prediction:", predictions[idx].item())
plot_attention_maps(input_data=None, attn_maps=attention_maps, idx=idx)
visualize_prediction(0)

Prediction: 9

Depending on the random seed, you might see a slightly different input set. For the version on the website, we compare 9 tree images with a volcano. We see that multiple heads, for instance, Layer 2 Head 1, Layer 2 Head 3, and Layer 3 Head 1 focus on the last image. Additionally, the heads in Layer 4 all seem to ignore the last image and assign a very low attention probability to it. This shows that the model has indeed recognized that the image doesn’t fit the setting, and hence predicted it to be the anomaly. Layer 3 Head 2-4 seems to take a slightly weighted average of all images. That might indicate that the model extracts the “average” information of all images, to compare it to the image features itself.
Let’s try to find where the model actually makes a mistake. We can do this by identifying the sets where the model predicts something else than 9, as in the dataset, we ensured that the anomaly is always at the last position in the set.
[41]:
mistakes = torch.where(predictions != 9)[0].cpu().numpy()
print("Indices with mistake:", mistakes)
Indices with mistake: [49]
As our model achieves ~94% accuracy, we only have very little number of mistakes in a batch of 64 sets. Still, let’s visualize one of them, for example the last one:
[42]:
visualize_prediction(mistakes[-1])
print("Probabilities:")
for i, p in enumerate(preds[mistakes[-1]].cpu().numpy()):
print("Image %i: %4.2f%%" % (i, 100.0 * p))

Prediction: 7

Probabilities:
Image 0: 0.07%
Image 1: 0.11%
Image 2: 0.07%
Image 3: 0.11%
Image 4: 0.17%
Image 5: 23.19%
Image 6: 0.16%
Image 7: 48.87%
Image 8: 0.10%
Image 9: 27.16%
In this example, the model confuses a palm tree with a building, giving a probability of ~90% to image 2, and 8% to the actual anomaly. However, the difficulty here is that the picture of the building has been taken at a similar angle as the palms. Meanwhile, image 2 shows a rather unusual palm with a different color palette, which is why the model fails here. Nevertheless, in general, the model performs quite well.
Conclusion¶
In this tutorial, we took a closer look at the Multi-Head Attention layer which uses a scaled dot product between queries and keys to find correlations and similarities between input elements. The Transformer architecture is based on the Multi-Head Attention layer and applies multiple of them in a ResNet-like block. The Transformer is a very important, recent architecture that can be applied to many tasks and datasets. Although it is best known for its success in NLP, there is so much more to it. We have seen its application on sequence-to-sequence tasks and set anomaly detection. Its property of being permutation-equivariant if we do not provide any positional encodings, allows it to generalize to many settings. Hence, it is important to know the architecture, but also its possible issues such as the gradient problem during the first iterations solved by learning rate warm-up. If you are interested in continuing with the study of the Transformer architecture, please have a look at the blog posts listed at the beginning of the tutorial notebook.
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Slack!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

