Learn how to:
Use Lightning Fabric to train and accelerate a PyTorch model using mixed precision and distributed training.Lightning Fabric provides a unified and simple API to easily switch devices, as well as training strategies that can handle training large SOTA models. We’ll also show you how to convert your raw PyTorch code so that you can accelerate PyTorch code with Fabric in just a few lines of code.
Fabric allows you to easily leverage underlying hardware like CUDA, GPU, TPU, or Apple Silicon and train your model on multiple GPUs or nodes.

Fabric and Pytorch
PyTorch is by far the most commonly used framework for implementing papers. As part of these implementations, especially as models and datasets grow in size, training and inference optimizations become increasingly important.
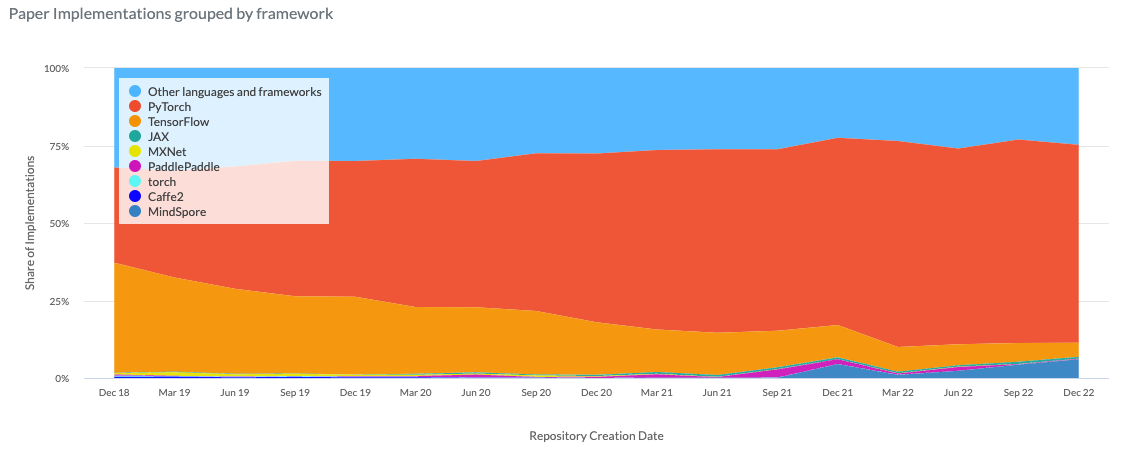
Paper implementations by framework. Source: Paperswithcode
Fabric allows you to accelerate raw PyTorch with just a few lines of code.
How to use Fabric and Pytorch
Using Fabric with PyTorch is straightforward.
1. Install
First, you need to install the Fabric library using pip.
pip install lightning
2. Initialize
Once you have installed Fabric, to accelerate your PyTorch code you need to create a Fabric object and set up your model, optimizer, and dataloaders.
from lightning.fabric import Fabric
fabric = Fabric(accelerator="auto", devices="auto", strategy="auto")
fabric.launch()
3. Set up your code
To set up the model, optimizer, and dataloaders, we’ll use the fabric.setup() and fabric.setup_dataloaders() API.
model, optimizer = fabric.setup(model, optimizer)
dataloader = fabric.setup_dataloaders(dataloader)
4. Remove manual .(device) calls
Once you’ve set up your code with Fabric, you don’t need to manually move your tensors from the CPU to the accelerator (CUDA/MPS/TPU), so you should remove model.to(device) and batch.to(device) call from your code.
5. Backward with Fabric
To do back-propagation from the loss, replaceloss.backward() with fabric.backward(loss).
# pip install lightning timm
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from lightning.fabric import Fabric
from timm import create_model
from tqdm import tqdm
# ⚡️⚡️⚡️⚡️⚡️ Init Fabric ⚡️⚡️⚡️⚡️⚡️
fabric = Fabric(accelerator="auto", devices=2, strategy="auto")
fabric.launch() # call launch() for distributed training
def load_data():
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
batch_size = 32
train_set = torchvision.datasets.CIFAR10(
root="~/data", train=True, download=True, transform=transform
)
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True, num_workers=4
)
return train_loader
train_loader = load_data()
model = model = create_model("resnet50", num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# ⚡️⚡️⚡️⚡️⚡️ Setup model and optimizer with Fabric ⚡️⚡️⚡️⚡️⚡️
model, optimizer = fabric.setup(model, optimizer)
# setup dataloader with Fabric
train_loader = fabric.setup_dataloaders(train_loader)
# ⚡️⚡️⚡️⚡️⚡️ Access the Device and strategy ⚡️⚡️⚡️⚡️⚡️
print(f"training on {fabric.device} with {fabric.strategy} strategy")
for i in range(2):
for x, y in tqdm(train_loader):
# no need to move x, y to devices
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits, y)
# ⚡️⚡️⚡️⚡️⚡️ fabric.backward(...) instead of loss.backward() ⚡️⚡️⚡️⚡️⚡️
fabric.backward(loss)
optimizer.step()
With these minimal changes, you’re all set to leverage distributed training strategies, multiple devices, and easily switch hardware.
Mixed precision training with PyTorch and Fabric
You can save memory by training your model at a lower precision. In a mixed precision setting, we use half-precision (FP16) which gives significant computational speedup while keeping minimal information in single precision (FP32) to maintain model stability and accuracy. Fabric makes it simple to enable mixed precision training with its unified API.
The precision types that are supported include 64, 32, 16-mixed, and bf16-mixed. To choose your precision type, simply specify any of these types as an argument in the Fabric class. You can read more about mixed precision training with Fabric here.
fabric = Fabric(precision="16-mixed")
Training on multiple GPUs
You can run distributed training on multiple GPUs and even multiple nodes. PyTorch implements DistributedDataParallel (DDP) class for distributed model training. To use DDP in raw PyTorch you will have to initialize the process group and make some code changes to accommodate the correct GPU device transfer of data and model. With Fabric, it is very convenient to enable distributed training by updating the flags in Fabric class. Apart from DDP, Fabric also supports DeepSpeed and fsdp out of the box.
# train on 4 GPUs
fabric = Fabric(devices=4, strategy="ddp")
# train on 100 GPUs using DeepSpeed
fabric = Fabric(devices=100, strategy="deepspeed")
Conclusion
With Fabric, you can accelerate any PyTorch code to be lightning fast ⚡. It was designed for Large Language Models (LLMs) and complex training pipelines such as reinforcement learning. With the unified API, you can control the number of devices, distributed strategy, and precision settings, making your code less redundant and more easily reproducible.
Join the Lightning AI Discord!
