This Russian-language blog post, completed by a member of the Lightning community, is a translation of the English original here.
Диффузионные модели в продакшене
tl;dr В этом туториале, вы научитесь масштабируемому деплою диффузионных (diffusion) моделей и создадите приложение, генерирующее изображения из текста
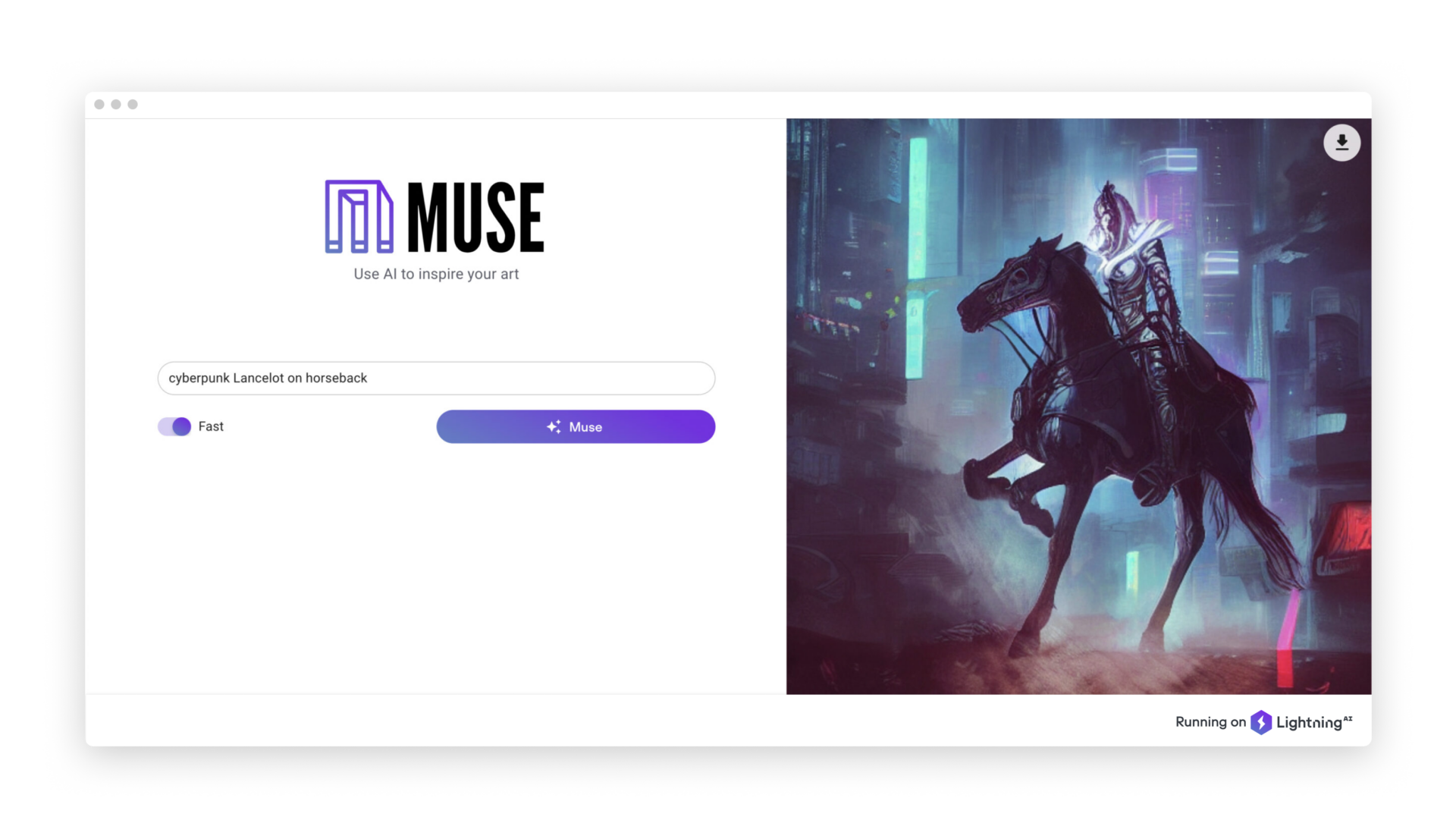
Сегодня мы выпустили Muse: генератор изображений на основе текстовых запросов с полностью открытым исходным кодом, построенный на базе Stable Diffusion, и, одновременно, — шаблон для разработки интеллектуальных облачных приложений на основе диффузионных моделей. Попробуй здесь!
Если вы часть ИИ комьюнити, то, скорее всего, вы заметили головокружительную скорость, с которой разрабатываются диффузионные модели (и приложения на их основе). Диффузионные модели — подкатегория глубоких генеративных моделей — состоят из этапов прямой и обратной диффузии, генерируют данные, аналогичные тем, на которых они обучаются. В Lightning мы предоставляем масштабируемый способ развертывания диффузионных моделей, который мы рассмотрим ниже.
Недавним (и открытым) примером диффузионной модели является Stable Diffusion от Stability AI — модель, генерирующая изображения на основе текстовых запросов, которая создает высококачественные изображения размером 512×512 пикселей всего за несколько секунд, будучи запущенной на общедоступной видеокарте и используя 10 ГБ памяти.
Эти модели являются новаторскими, но их деплой по-прежнему остается узким местом. Ниже мы покажем вам, как мы создали пользовательский интерфейс с React, а также сервер моделей с FastAPI, чтобы легко и быстро развернуть эти модели с помощью Lightning приложения.
В следующих секциях мы обсудим процесс создания нашей первой версии Muse, сложности с которыми мы столкнулись и шаги, которые мы предприняли, чтобы справиться с ними.
Деплоим Stable Diffusion с FastAPI и LightningApp
Мы реализовали класс StableDiffusionServe, унаследовавшись от Lightning Work. Этот Work скачивает чекпоинт Stable Diffusion, загружает модель и определяет REST обработчик, который возвращает изображение, закодированное base64, на основе введенного запроса:
Первая версия Muse представляла собой простой веб-интерфейс для генератора изображений на основе текстового запроса, который мы реализовали с помощью React. Одной из функций, которую мы добавили в начале нашего итерационного процесса, был переключатель, который позволяет выбирать между быстрой и более медленной, но более качественной, генерацией изображений. Поскольку Stable Diffusion принимает num_inference_steps в качестве аргумента, мы используем 50 шагов для более качественного режима и 25 для более быстрого варианта.
После того, как мы закончили это простое демо деплоя Stable Diffusion, мы интегрировали его в наш Slack (ниже мы покажем вам, как это сделать), чтобы немного повеселиться.
Однако, по мере того как члены нашей команды начали генерировать все больше и больше изображений, мы заметили, что сервер модели достиг своего предела, имея всего 10 одновременных пользователей. Lightning приложения предназначены не только для простых демонстраций — они предлагают масштабируемый и переносимый способ деплоя больших моделей. Поэтому мы экспериментировали с несколькими методами масштабирования сервера модели таким образом, чтобы он мог обслуживать сотни одновременных пользователей.
Автомасштабирование серверов модели
Одним из способов масштабирования является параллельный запуск нескольких серверов модели. Мы реализовали балансировщик нагрузки, снова используя FastAPI, который отправляет запрос на сервера модели в циклическом (round-robin) режиме.
Цель здесь состояла в том, чтобы автоматически масштабировать сервера модели на основе количества запросов. Мы реализовали функцию autoscale, которая запускается с временным интервалом (30 секунд) и проверяет количество запросов на сервере. Затем, в соответствии с пороговым значением, она добавляет или удаляет workеr:
Динамическая пакетная обработка
После реализации автомасштабирования мы заметили, что наша модель не обрабатывает клиентские запросы параллельно, что приводит к пустой трате ресурсов графического процессора. Чтобы увеличить пропускную способность, агрегировать запросы и обрабатывать их на каждом из серверов модели, мы реализовали динамическую пакетную обработку в балансировщике нагрузки. Внедрение динамической пакетной обработки и большего количества серверов привело к увеличению количества запросов, которые Muse может обрабатывать одновременно, с менее чем 5 до более чем 300.
Мы провели тесты производительности на нашем сервере с пакетной обработкой и без нее с разным количеством серверов модели.
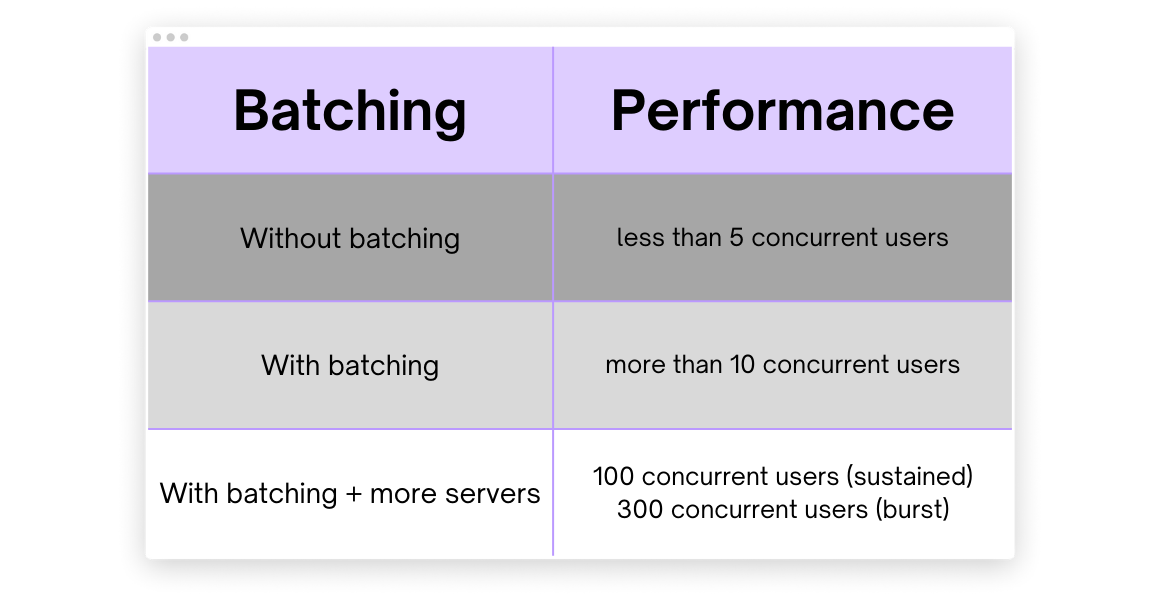
Производительность Muse при использовании пакетной обработки.
Балансировщик нагрузки ожидает несколько секунд, чтобы агрегировать клиентские запросы, и отправляет их в виде пакета на сервер модели, таким образом обрабатывая несколько запросов параллельно.
Для реализации динамической пакетной обработки мы присваиваем запросам уникальный идентификатор и ставим их в очередь. Элементы из этой очереди получает Python coroutine, которая объединяет запросы. Как только пакет будет заполнен или истечет таймаут, она отправит агрегированные запросы на сервер модели, и ответ придёт в словаре с уникальным идентификатором запроса в качестве ключа.
После реализации автоматического масштабирования и динамической пакетной обработки мы смогли обрабатывать значительно большее количество запросов параллельно и масштабироваться в зависимости от трафика.
Преврати свое приложение в Slackbot
В этом разделе мы покажем вам, как поделиться развернутой диффузионной моделью в виде Slackbot’а. Одним из наших Lightning компонентов является Slack Command Bot, который вы можете установить в своем рабочем пространстве, чтобы отправлять изображения, созданные ИИ, в выбранный вами канал. Наш Slack Command Bot компонент предоставляет простой способ добавить интерактивность в Slack с помощью слеш-команды.
После установки слэкбота’а просто введите /muse <PROMPT> и отправьте сообщение в канал, где был добавлен Muse Bot. Бот опубликует изображение, созданное на основе вашего запроса.

Попробуйте Muse в своем Slack’е!
Этот компонент требует, чтобы вы унаследовали класс SlackCommandBot и реализовали метод handle_command(…). Для наших целей мы реализуем команду handle_command для публикации изображения, созданного на основе запроса.
Мы отправляем запрос балансировщику нагрузки с помощью REST API и используем ответное изображение, закодированное base64, для отправки сообщения в Slack:
Подведем итоги
Мы масштабировали развертывание этой диффузионной модели с менее чем 5 одновременных пользователей до 300 одновременных пользователей с помощью автоматического масштабирования и динамической пакетной обработки. Мы реализовали это на чистом Python и быстро и легко развернули с помощью Lightning приложения. Оно управляет выделением ресурсов в облаке, выбором GPU машин, распределением дисков и решает другие инфраструктурные проблемы, которые мешают масштабному развертыванию диффузионных моделей.
Зачем мы это сделали?
В Интернете полно генераторов изображений на основе текстового запроса (а теперь еще и генераторов видео из текста!). Вы можете спросить себя, почему мы потратили время на разработку собственного?
Muse — это не просто еще один генератор изображений — мы думаем о нем как о чертеже. Не только для других генераторов изображений, но и для всех видов облачных приложений на базе ИИ. Мы создали Muse, чтобы показать вам, на что способен Lightning и, что еще более важно, что вы можете сделать с Lightning. Поскольку Muse имеет открытый исходный код, вы можете использовать код для вдохновения в будущих проектах, подобных этому. Все, что вам нужно сделать, это нажать «Clone & Run», чтобы запустить копию Muse в вашей собственной учетной записи Lightning (думайте об этом, как о клонировании репозитория!). Затем, вы можете модифицировать код по своему усмотрению.
Обычно создание распределенных приложений (приложений, которые могут выполняться и хранить информацию на нескольких компьютерах) сложно. Lightning делает всю тяжелую работу за вас, поэтому вам остается только сосредоточиться на том, что вы пытаетесь создать. Lightning приложения (например, Muse!) определяют ML workflow, который может выполняться на вашем компьютере или в облаке по вашему усмотрению. Это так же просто, как добавить один флаг к команде запуска вашего приложения.
Они ещё и мощны — вы можете запустить несколько Lightning Works (один из строительных блоков Lightning приложения) параллельно, так что даже длительные рабочие нагрузки, такие как обучение модели или развертывание, могут запускать Work, даже когда остальная часть Lightning приложения продолжает выполняться.
На этом все! Muse — это источник вдохновения, будь то искусство или распределенные облачные приложения. В наших глазах это одно и то же.

