PyTorch’s native FSDP, now in Lightning
tl;dr this tutorial teaches you how to overcome hardware constraints when training large models using PyTorch’s new model sharding strategy
Model size has grown exponentially in recent years, producing significantly better results in many domains. However, this expansion has been hampered by hardware constraints, as not everyone has access to the necessary hardware to train large-scale models. To tackle this issue, engineers and researchers have been working on strategies for efficient distributed model training, including Fully Sharded Data Parallel (FSDP).
One way to reduce memory overhead is by sharding the optimizer states. Currently, each device handles all the weight updates and gradient computation, which consumes a large chunk of memory. Optimizer sharding comes in handy by reducing the memory footprint on each device. Sometimes, even optimizer sharding isn’t enough; in such cases, we would shard models as well.
Model Sharding is one technique in which model weights are sharded across devices to reduce memory overhead.
In the release of 1.11, PyTorch added native support for Fully Sharded Data Parallel (FSDP).
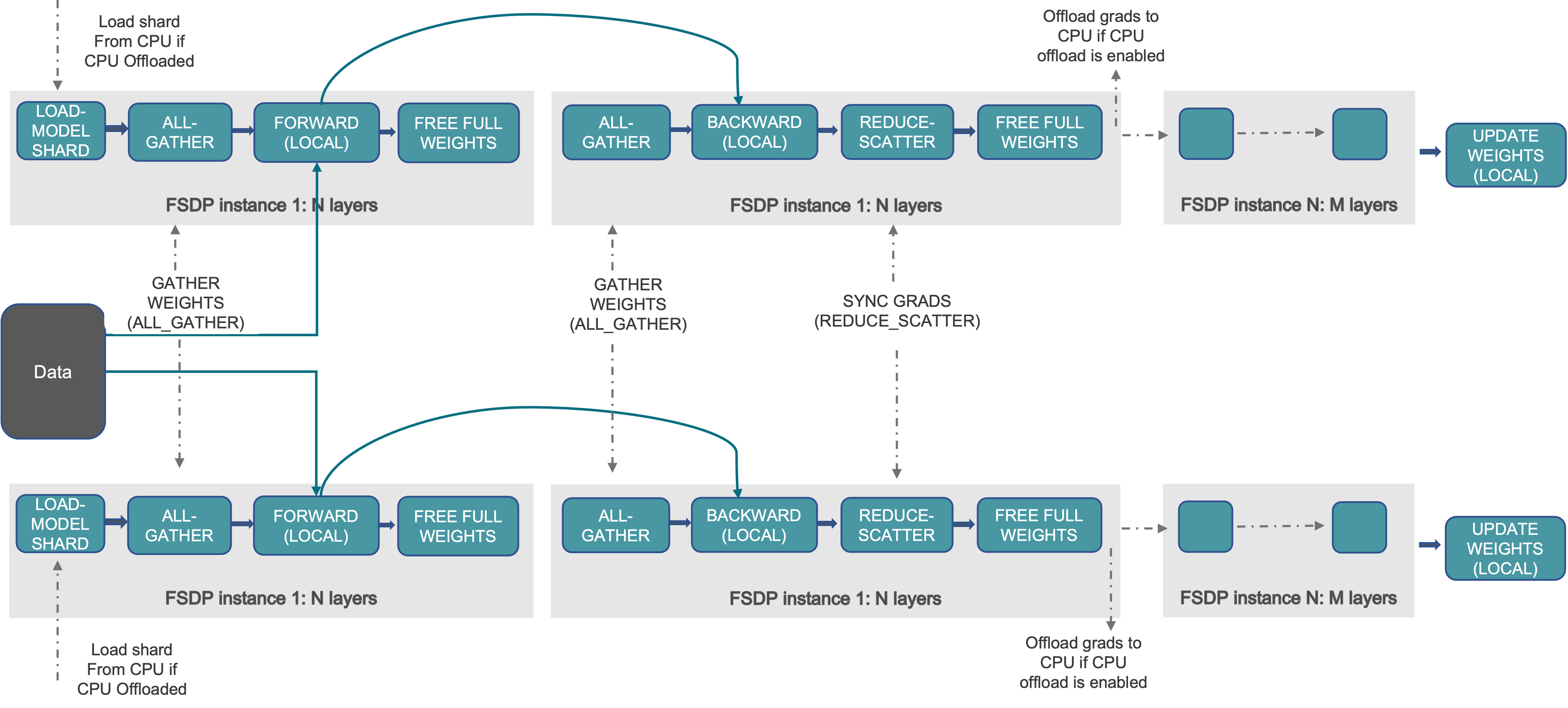
FSDP workflow (via PyTorch)
FSDP initially appeared in fairscale and later in the official PyTorch repository. Lightning Trainer now supports both of them.
Using FSDP with Lightning
In the Lightning v1.7.0 release, we’ve added support for this Fully Sharded Native Strategy, which can help you leverage native FSDP support by setting the strategy flag as "fsdp_native".
You can customize the strategy configuration by adjusting the arguments of DDPFullyShardedNativeStrategy and passing that to the strategy inside the Trainer.
Read more about its usage in the docs here.
How does FSDP work internally?
In regular DDP, every GPU holds an exact copy of the model. In contrast, Fully Sharded Training shards the entire model weights across all available GPUs, allowing you to scale model size while using efficient communication to reduce overhead. In practice, this means we can remain at parity with PyTorch DDP while dramatically scaling our model sizes. The technique is similar to ZeRO-Stage 3.
You can read more about this in PyTorch’s blog post here.
We also suggest looking at this tutorial.
Note: Since PyTorch has labeled native support for FSDP as beta, the new strategy is in beta as well and therefore subject to change. The interface can bring breaking changes and new features with the next release of PyTorch.
Key Points and Differences From the Native FSDP Release
- This implementation borrows from FairScale’s version while bringing streamlined APIs and additional performance improvements.
- When we enabled CPU offloading, native FSDP implementation significantly improved model initialization time when compared against FairScale’s original.
- Soon, FairScale FSDP will remain in the FairScale repository for research projects. At the same time, generic and widely adopted features will be incrementally upstreamed to PyTorch and hardened as needed.
Acknowledgment
We thank Sisil Mehta for spearheading the native FSDP integration with Lightning Trainer.

