Takeaways
In this tutorial, we will learn how to train and fine-tune LLaMA (Large Language Model Meta AI). Lit-LLaMA, a rewrite of LLaMA, can run inference on an 8 GB consumer GPU. We will also discover how it utilizes Lightning Fabric to accelerate the PyTorch code.What is LLaMA 🦙
LLaMA is a foundational large language model that has been released by Meta AI.
LLaMA comes in four size variants: 7B, 13B, 33B, and 65B parameters. The paper shows that training smaller foundation models on large enough tokens is desirable, as it requires less computing power and resources. The 65B parameter models have been trained on 1.4 trillion tokens, while the LLaMA 7B model has been trained on 1 trillion tokens.
Just a few weeks after the release of LLaMA, the open-source community embraced it by creating an optimized version and expanding its use cases. Now, you can fine-tune LLaMA using LoRA (reduces the number of trainable parameters for fine-tuning) and train a chatbot with Stanford Alpaca.
Lightning AI has also joined the trend by providing an open-source, from-scratch rewrite of LLaMA called Lit-LLaMA. The main highlight of Lit-LLaMA is that it is released under the Apache 2.0 license, which makes it easier to adopt for other deep learning projects that use similar permissive licenses and also enables commercial use. It has scripts for optimized training and fine-tuning with LoRA.
Lit-LLaMA: simple, optimized, and completely open-source 🔥

Lit-LLaMA is a scratch rewrite of LLaMA that uses Lightning Fabric for scaling PyTorch code. It focuses on code readability and optimizations to run on consumer GPUs. As of the time of writing this article, you can run Lit-LLaMA on GPUs with 8 GB of memory 🤯.
Note: Currently you need to download the official Meta AI LLaMA pre-trained model weights for fine-tuning or running inference.
Lit-LLaMA supports training, fine-tuning, and generating inference. Let’s discuss each functionality in detail.
Training LLaMA
Note: We won’t go into too many details about training LLaMA from scratch and instead focus more on fine-tuning and inference because the computational need for training is not available to everyone in the community.
The repo comes with a simple and readable LLaMA model implementation and a training script accelerated by Fabric.
Large language models may not fit into a single GPU. Fully Sharded Data Parallelism (FSDP) is a technique that shards model parameters, gradients, and optimizer states across data parallel workers. Fabric provides a unified API that makes it easy to use FSDP.
To use FSDP (Fully-Sharded Data Parallel) with Fabric, create an FSDPStrategy object by specifying the auto-wrap policy and passing it as an argument to the Fabric class.
Fabric helps to automatically place the model and tensors on the correct devices, enabling distributed training, mixed precision, and the ability to select the number of devices to train on.
import lightning as L
from lightning.fabric.strategies import FSDPStrategy
import torch
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from lit_llama.model import Block, LLaMA, LLaMAConfig
def main():
# ⚡️⚡️⚡️⚡️⚡️ Initialize FSDP strategy ⚡️⚡️⚡️⚡️⚡️
auto_wrap_policy = partial(transformer_auto_wrap_policy, transformer_layer_cls={Block})
strategy = FSDPStrategy(auto_wrap_policy=auto_wrap_policy, activation_checkpointing=Block)
# ⚡️⚡️⚡️⚡️⚡️ Initialize Fabric ⚡️⚡️⚡️⚡️⚡️
# setting for 4 GPUs with bf16 mixed precision and FSDP distributed training strategy
fabric = L.Fabric(accelerator="cuda", devices=4, precision="bf16-mixed", strategy=strategy)
fabric.launch()
# Load data
train_data, val_data = load_datasets()
# Load model configs
config = LLaMAConfig.from_name("7B")
config.block_size = block_size
config.vocab_size = 100 # from prepare_shakespeare.py
# ⚡️⚡️⚡️⚡️⚡️ initialize model ⚡️⚡️⚡️⚡️⚡️
with fabric.device:
model = LLaMA(config)
# ⚡️⚡️⚡️⚡️⚡️ Setup model and optimizer for distributed training ⚡️⚡️⚡️⚡️⚡️
model = fabric.setup_module(model)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay, betas=(beta1, beta2))
optimizer = fabric.setup_optimizers(optimizer)
train(fabric, model, optimizer, train_data, val_data)
You can also find the full training code here.
Fine-tuning LLaMA
Within just weeks of launching LLaMA, the community began optimizing and building upon it. Fine-tuning LLaMA on consumer GPUs is crucial to truly democratize LLMs. LLMs can be fine-tuned to build a chatbot and specialized for particular tasks or fields, such as an LLM specialized in summarizing legal or financial data.
Lit-LLaMA includes a fine-tuning script that utilizes LoRA (Low-Rank Adaptation of Large Language Models). LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. This significantly reduces the number of trainable parameters for downstream tasks.
To initialize LLaMA with LoRA layers we need to use the context manager from lit_llama.lora:
from lit_llama.lora import lora
from lit_llama.model import LLaMA, LLaMAConfig
# initialize configs
lora_dropout = 0.05
config = LLaMAConfig.from_name("7B")
config.block_size = block_size
# initlize model with LoRA
with lora(r=lora_r, alpha=lora_alpha, dropout=lora_dropout, enabled=True):
model = LLaMA(config)
# mark only LoRA injected layers for training
mark_only_lora_as_trainable(model)
You can notice that the with lora is a Python context manager which implements the replacement of CausalSelfAttention with the LoRA-injected trainable parameters.
@contextmanager
def lora(r, alpha, dropout, enabled: bool = True):
"""A context manager under which you can instantiate the model with LoRA."""
if not enabled:
yield
return
LoRACausalSelfAttention.lora_config = LoRAConfig(r=r, alpha=alpha, dropout=dropout)
causal_self_attention = llama.CausalSelfAttention
llama.CausalSelfAttention = LoRACausalSelfAttention
yield
llama.CausalSelfAttention = causal_self_attention
LoRACausalSelfAttention.lora_config = None
We are now ready to fine-tune LLaMA. You can fine-tune Lit-LLaMA on the Alpaca dataset using LoRA and quantization on a consumer GPU. Lit-LLaMA comes with a simple script for downloading and preparing the Alpaca dataset, which you can find here.
Note: You can convert the official Meta AI LLaMA weights to Lit-LLaMA format using the instructions here.
Follow these two simple steps to instruction-tune LLaMA:
- Download data and generate instruction tuning dataset:
python scripts/prepare_alpaca.py - Run the fine-tuning script:
python finetune_lora.py
Find the full fine-tuning code here.
Generating text from a trained model
To generate text predictions, you will need trained model weights. You can use either the official Meta AI weights or the model that you have fine-tuned. Lit-LLaMA includes a text-generation script that can run on a GPU with 8 GB of memory and quantization. To generate text, run the following command in the terminal:
python generate.py --quantize true --prompt "Here's what people think about pineapple pizza: "
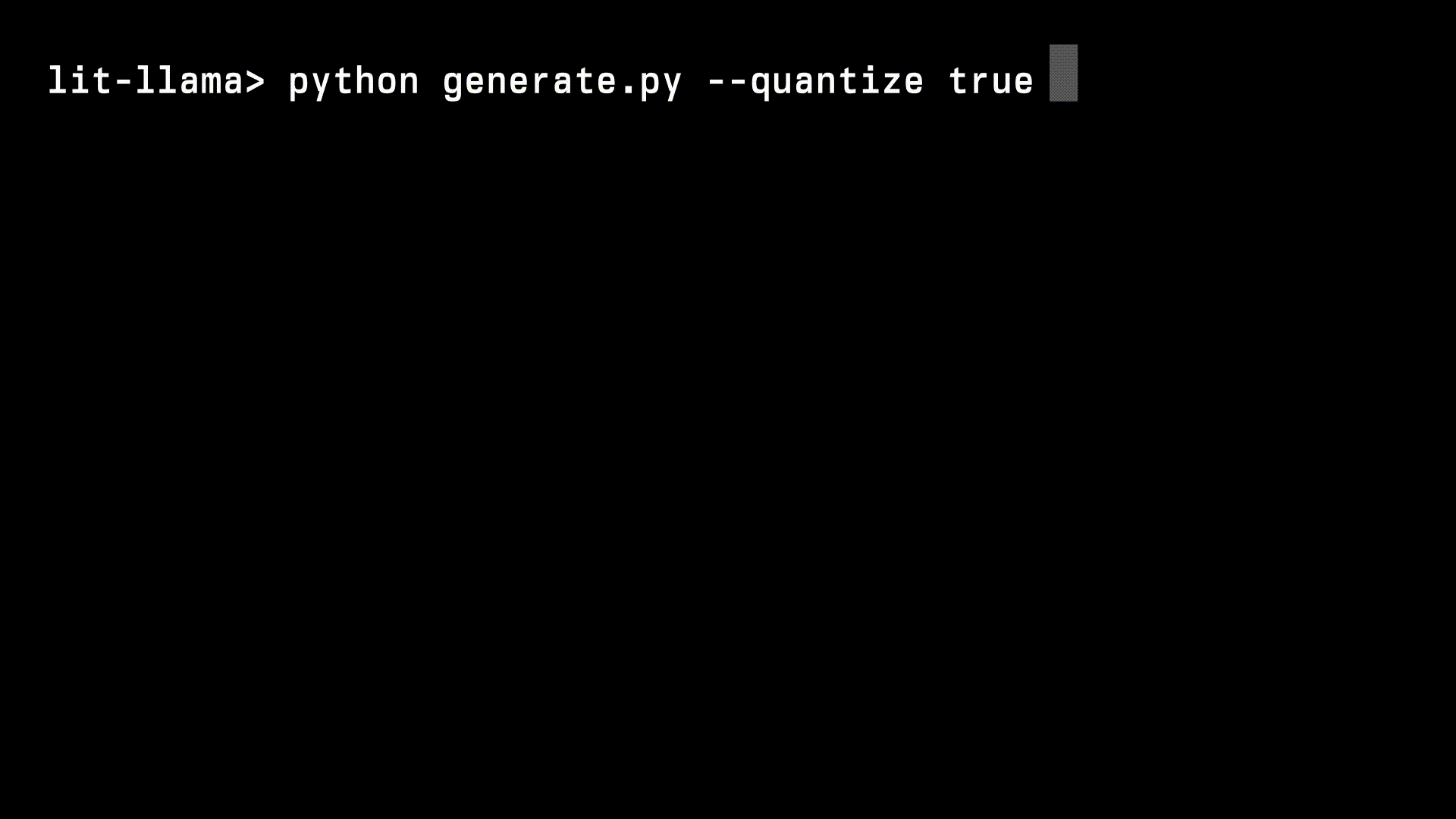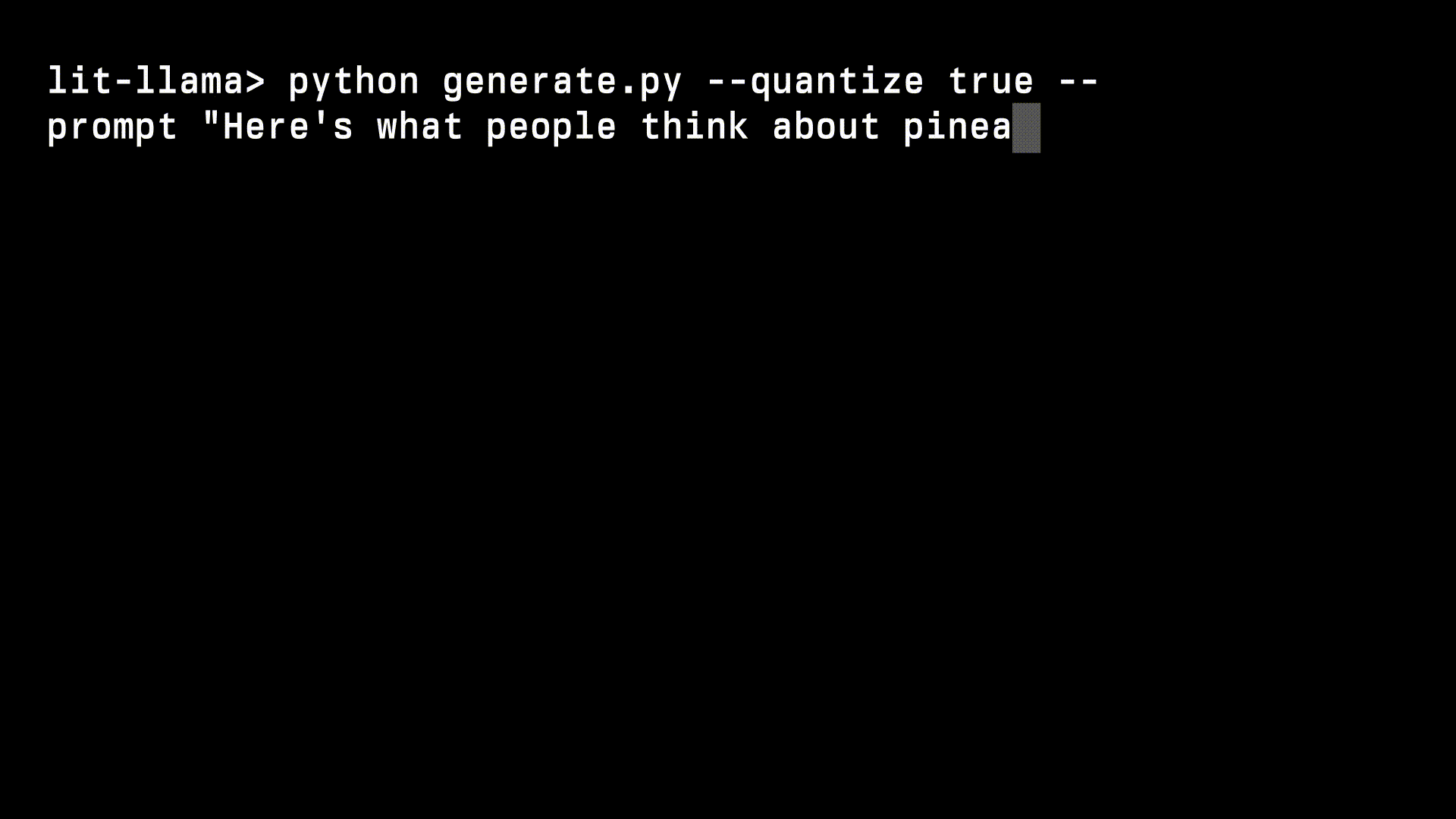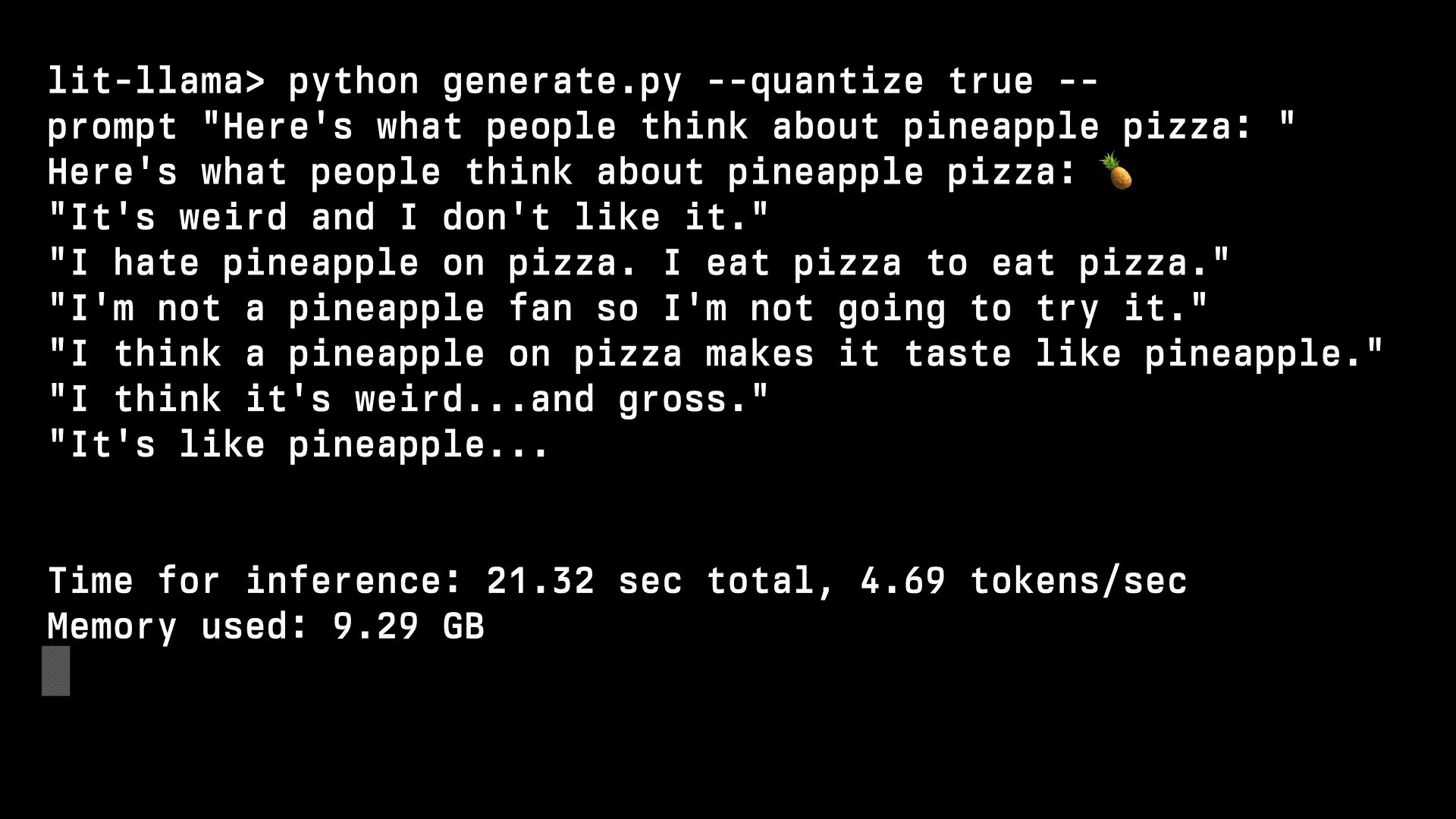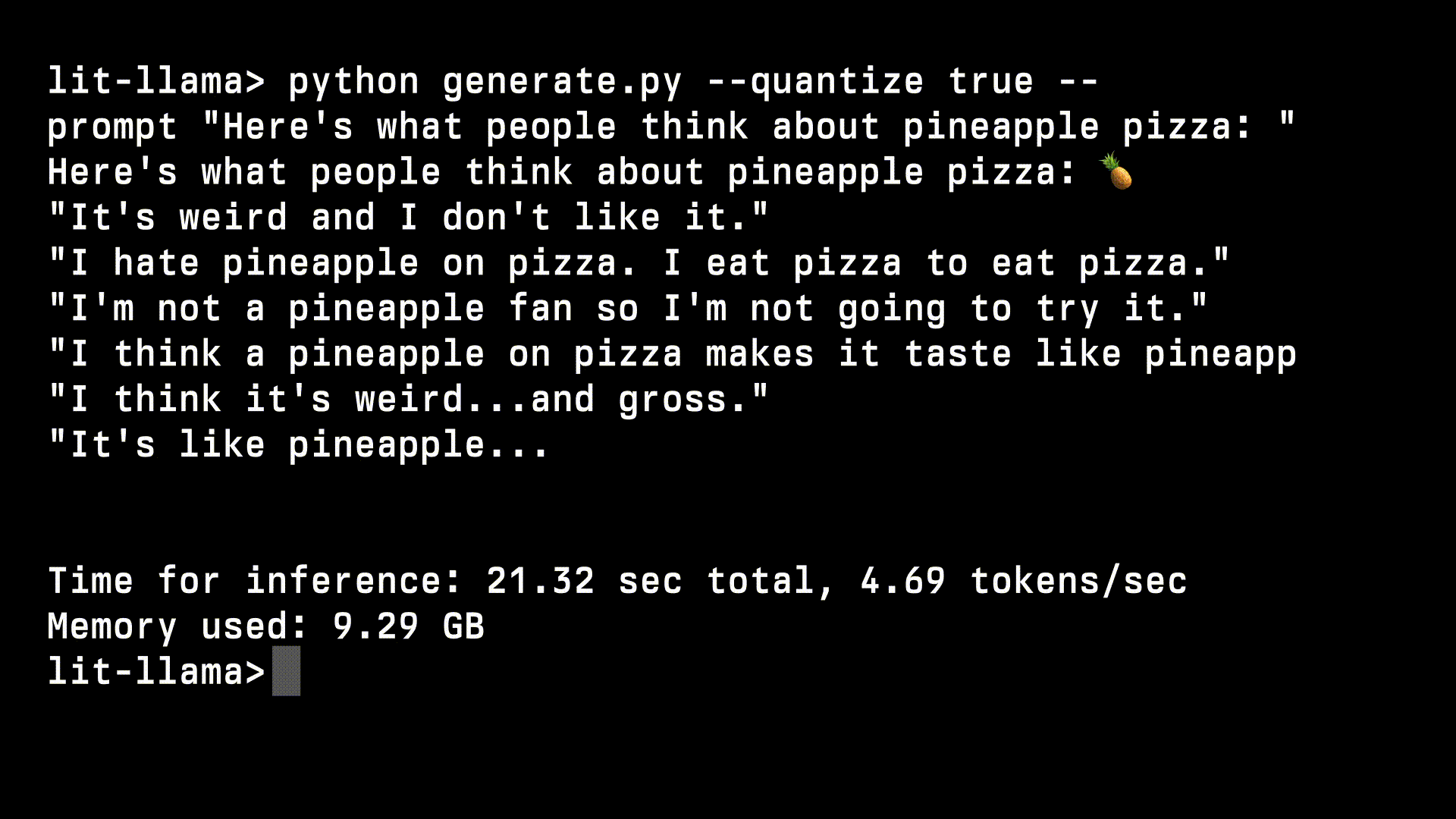
Conclusion
Lit-LLaMA promotes open and collective science by releasing its source code under the Apache 2.0 license. It extends the original Meta AI code by adding training, an optimized fine-tuning script, and the ability to run inference on a consumer GPU (using up to 8GB of memory with quantization). Lit-LLaMA has already crossed 2K GitHub stars 💫, and it will be interesting to see what the community builds on top of it.
Go to Repo
