주요 시사점
Lightning을 이용하여 어떻게 모델 훈련 및 배포 파이프라인을 만들 수 있는지 배웁니다. 해당 파이프라인은 커스터마이징 할 수 있고, monitoring, data warehouse, feature store 등 여러 기능과 통합되어 있으며, production에 배포되어 있습니다.
MLOps는 AI 기반 제품 및 서비스를 생산하는 크고 작은 기업들에게 필수입니다. 다양한 종류의 툴과 플랫폼들이 머신러닝 생명주기의 각기 다른 부분을 해결하고자 한다는 것을 고려하면, 때로는 이들 중 하나를 선택하는 것이 어렵습니다. 머신러닝 훈련 및 배포 파이프라인을 만드는 것이란 처음부터 단편적인 경험입니다.
production에서 머신러닝 모델들을 훈련하고 배포하기 위한 Lightning 의 통일된 플랫폼을 다음에서 살펴보겠습니다.
Lightning 이란?
Lightning (PyTorch Lightning을 만든 이들이 Lightning도 만들었습니다.) 은 PyTorch Lightning의 능력을 training을 넘어서 serving, 배포, 모니터링, 데이터 엔지니어링으로 증강시킨 플랫폼입니다. 사용자 중심의 Lightning Trainer는 이미 분산학습을 단순화하고 사용자들이 하드웨어를 마음대로 선택할 수 있게 했습니다. Lightning 도 이와 동일한 원칙을 가지고 만들어졌고, 연구자들과 현장 근무자들의 업무에 있어 완전한 유연성을 허락함과 동시에 복잡한 클라우드 인프라를 생략해줍니다.
Lightning 은 오픈소스 라이브러리인 Lightning App Framework를 중심으로 디자인되었습니다. Lightning App Framework는 분산된 Pythonic 앱들을 만들고 실행하는 것을 가능케 합니다. CLI에 몇 개의 flag 만 추가하면 해당 Python 코드는 당신의 로컬 시스템, Lightning Cloud (AWS 기반), 심지어는 당신만의 private cluster 에서도 최소한의friction으로 실행할 수 있습니다. 우리의 완벽히 관리된 클라우드 서비스에서 사랑받은 PyTorch Lightning과 동일하게 막강한 단순함이 Lightning에도 있습니다.
이것이 ML 파이프라인을 만들기에 가장 안전한 방법입니까?
그렇다고 생각합니다! 예를 들어, 당신이 infrastructure provisioning을 Lightning CloudCompute Python API로 했다고 합시다. 그 다음에 당신 팀의 누구나 클라우드 컴퓨팅에 대한 전문지식 없이 인프라를 원하는 대로 바꾸고 관리할 수 있습니다. 이는 아까 언급한대로 friction과 클라우드 엔지니어들의 dependency delay를 없애는데, 대부분의 조직에서는 이 단계에서 많은 시간이 소요됩니다.
Lightning API들
다음 부분에서, 핵심 Lightning API들을 사용 예제와 함께 살펴보겠습니다.
LightningWork
LightningWork는 모델 훈련, serving, ETL 등 장기 작업의 기본 구성요소입니다.
LightningWork는 사용자들이 RAM, CPU/GPU, disk allocation 등의 machine configuration을 유연히 할 수 있게 합니다.
여기 예제에서는 어떻게 50GB disk짜리 Nvidia T4 GPU 머신을 만들고 PyTorch 와 FastAPI를 dependency requirement로 추가하는지 보여줍니다.
“`
Python Script
“`
Lightning 은 자동으로 명시된 크기의 disk를 가진 GPU 머신을 생성하고 필요한 requirements를 설치할 것입니다. LightningWork 는 클라우드에서는 별개의 머신에서, 로컬 시스템에서는 별개의 프로세스에서 실행됩니다.
모든 종류의 프로세스를 LightningWork에서 실행할 수 있습니다. 몇몇 사용 예시로는:
- 모델 훈련
- 모델 배포
- Gradio또는 Streamlit을 사용한 모델 Demo
- ETL 파이프라인
등이 있습니다.
여기 좀더 복잡한 예제에서는 PythonServer component를 이용하여 이미지 분류 모델을 배포합니다.
LightningFlow
LightningFlow는 다수의 LightningWorks – 앞에 언급된 장기 작업들입니다 – 를 관리합니다. Flow의 자식은 다른 Flow들이거나 Work 일 수 있습니다.
Flow의 실행은 run(…) 메소드로 시작하는데, 루프형식으로 끝없이 돌아갑니다.
따라서 본격적인 머신러닝 어플리케이션은 Flow들과 Work들로 구성되어 있습니다. Work들은 계산적으로 무거운 script를 시행하고 이 script는 Flow들에 의해 관리됩니다.
예를 들어, 머신러닝 모델을 훈련하고 배포하는 훈련 및 배포 어플리케이션은 다음과 같이 생겼을 것입니다:
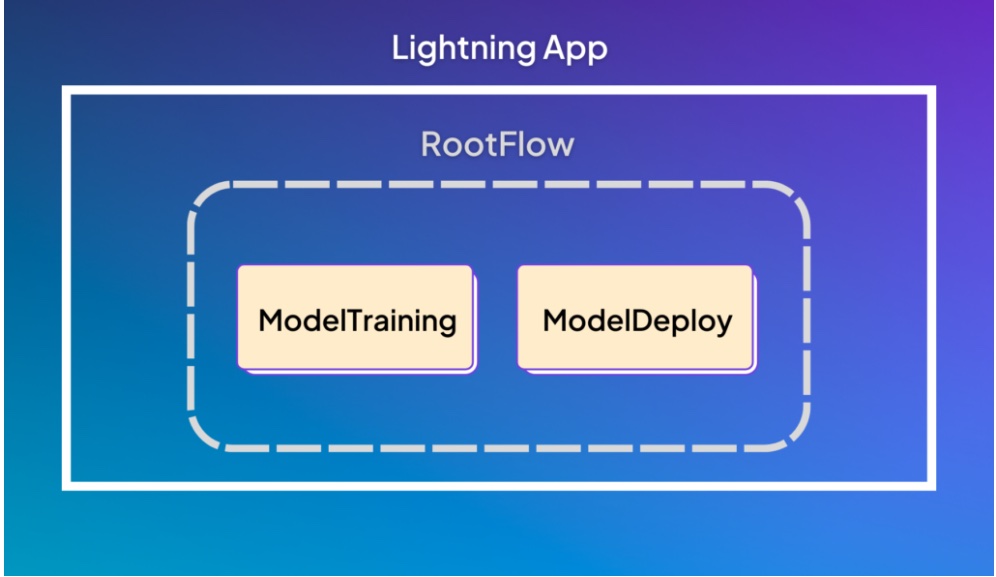
훈련과 배포 단계로 구성된 RootFlow예시 앱입니다.
앞의 Lightning App은 ModelTraining과 ModelDeploy의 두 작업을 포함하는 RootFlow로 구성되어 있습니다. 당신의 머신러닝 시스템의 범위가 확장되면서, Drift detection과 model 모니터링 같은 추가 구성요소들을 RootFlow에 더할 수 있습니다.
예시의 RootFlow는 두 개의 LightningWork 자식들을 가진 LightningFlow입니다. run(…) 메소드는 이 앱이 어떻게 실행될 지를 정의합니다. 이 예시에서는 먼저 모델을 훈련하고 그 다음에 배포할 것입니다:
“`
Python Script
“`
ModelTraining 클래스가 LightningWork 이기 때문에, run 메소드에서 훈련을 시행합니다:
“`
Python Script
“`
비슷하게, ModelDeploy 클래스도 LightningWork입니다:
“`
Python Script
“`
이 앱에서 만약 자신의 모델을 GPU에서 훈련하지만 배포는 CPU 머신에서 하고 싶다고 합시다. Lightning은 이 과정을 단순하게 만듭니다:
“`
Python Script
“`
이 Lightning App을 실행하기 위해, RootFlow를 L.LightninApp으로 감싸고 터미널에서 lightning run app app.py 를 실행해야 합니다. 이를 클라우드에서 배포하려면, –cloud flag를 더하고 명령문 lightning run app app.py –cloud를 시행하기만 하면 됩니다.
정리
이 단계들을 따라왔다면, 당신은 이제 production에 머신러닝 모델들을 훈련하고 배포할 준비가 된 것입니다. 다음단계로, 파이프라인에 autoscaling, dynamic batching, hyperparameter optimization, drift detection 등 더 많은 기능들을 추가할 수 있습니다. Lightning은 어떠한 Python 코드를 어디서든지 실행할 수 있는 유연성을 제공합니다 – 그게 바로 이 글에서 다룬 Lightning App입니다.
클라우드 머신러닝 모델 훈련이나 production 머신러닝 시스템 제작에 대해 더 알고 싶다면, 문서를 참고하세요!

