Takeaways
Our community member Luca Medeiros shows how he leveraged the Segment Anything Model from Meta AI and built his lang-segment-anything library for object detection and image segmentation based on text prompts.Segment Anything Model (SAM)
In recent years, computer vision has witnessed remarkable advancements, particularly in image segmentation and object detection tasks. One of the most recent notable breakthroughs is the Segment Anything Model (SAM), a versatile deep-learning model designed to predict object masks from images and input prompts efficiently. By utilizing powerful encoders and decoders, SAM is capable of handling a wide range of segmentation tasks, making it a valuable tool for researchers and developers alike.
SAM employs an image encoder, typically a Vision Transformer (ViT), to extract image embeddings that serve as a foundation for mask prediction. The model also incorporates a prompt encoder, which encodes various types of input prompts, such as point coordinates, bounding boxes, and low-resolution mask inputs. These encoded prompts, along with image embeddings, are then fed into a mask decoder to generate the final object masks.
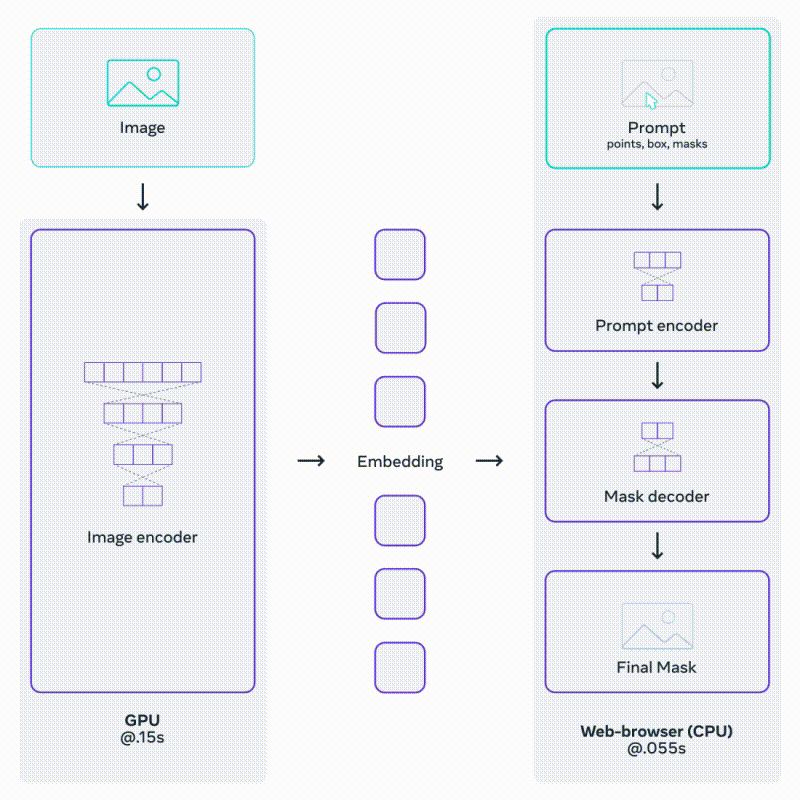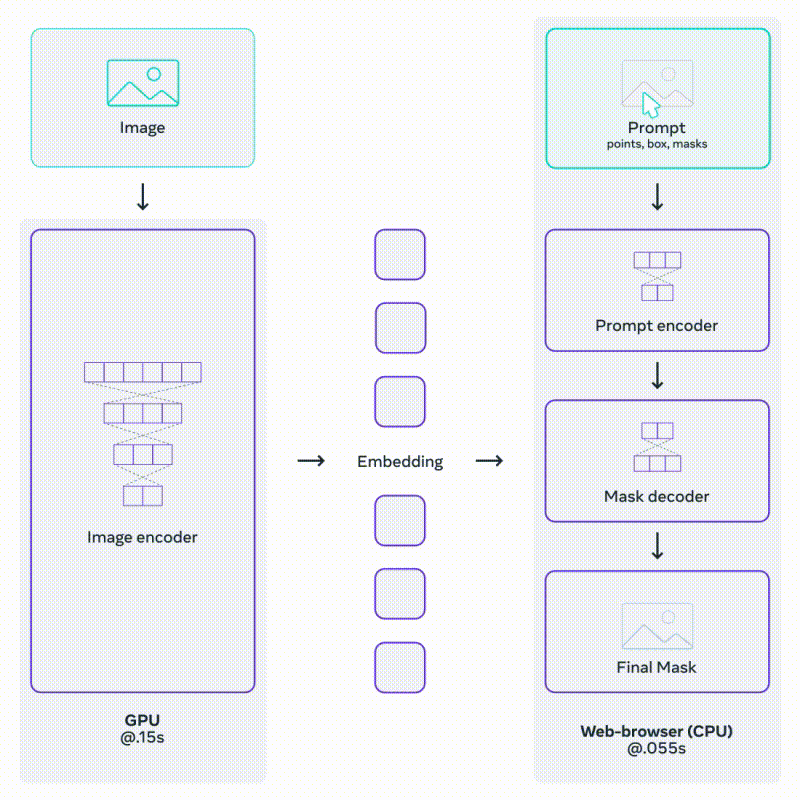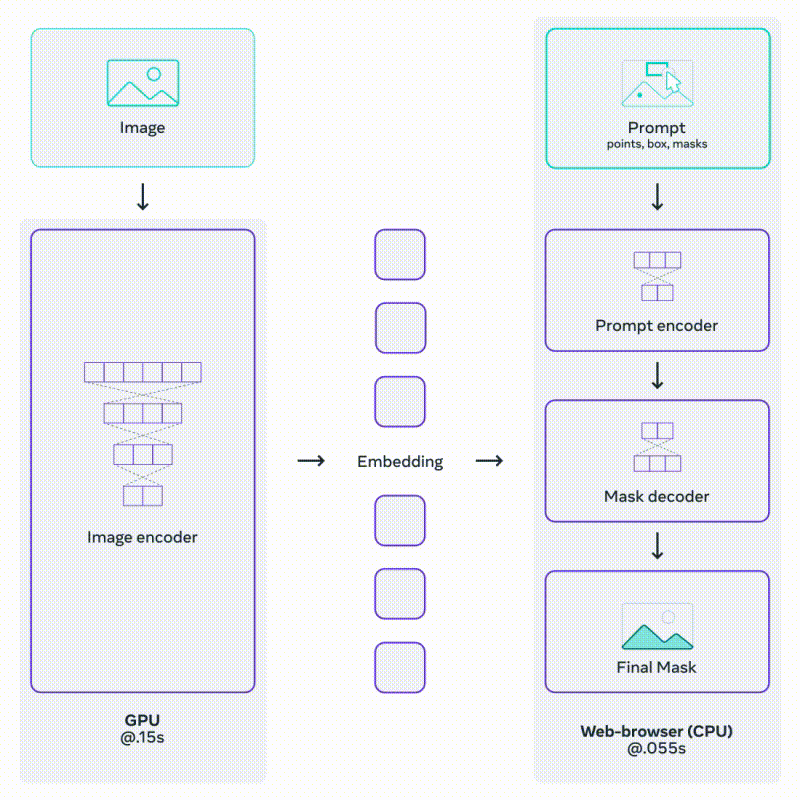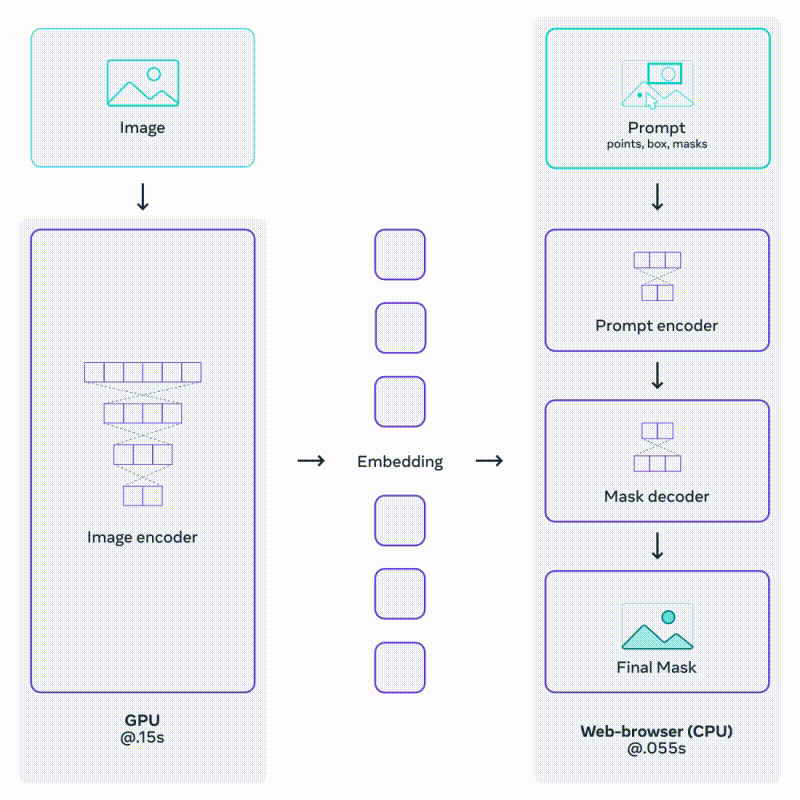
Source: Section 3.1c https://segment-anything.com/
The above architecture allows fast and light prompting on an already encoded image.
SAM is designed to work with a variety of prompts, including:
- Mask: A rough, low-resolution binary mask can be provided as an initial input to guide the model.
- Points: Users can input [x, y] coordinates along with their type (foreground or background) to help define object boundaries.
- Box: Bounding boxes can be specified using coordinates [x1, y1, x2, y2] to inform the model about the location and size of the object.
- Text: Textual prompts can also be used to provide additional context or to specify the object of interest.
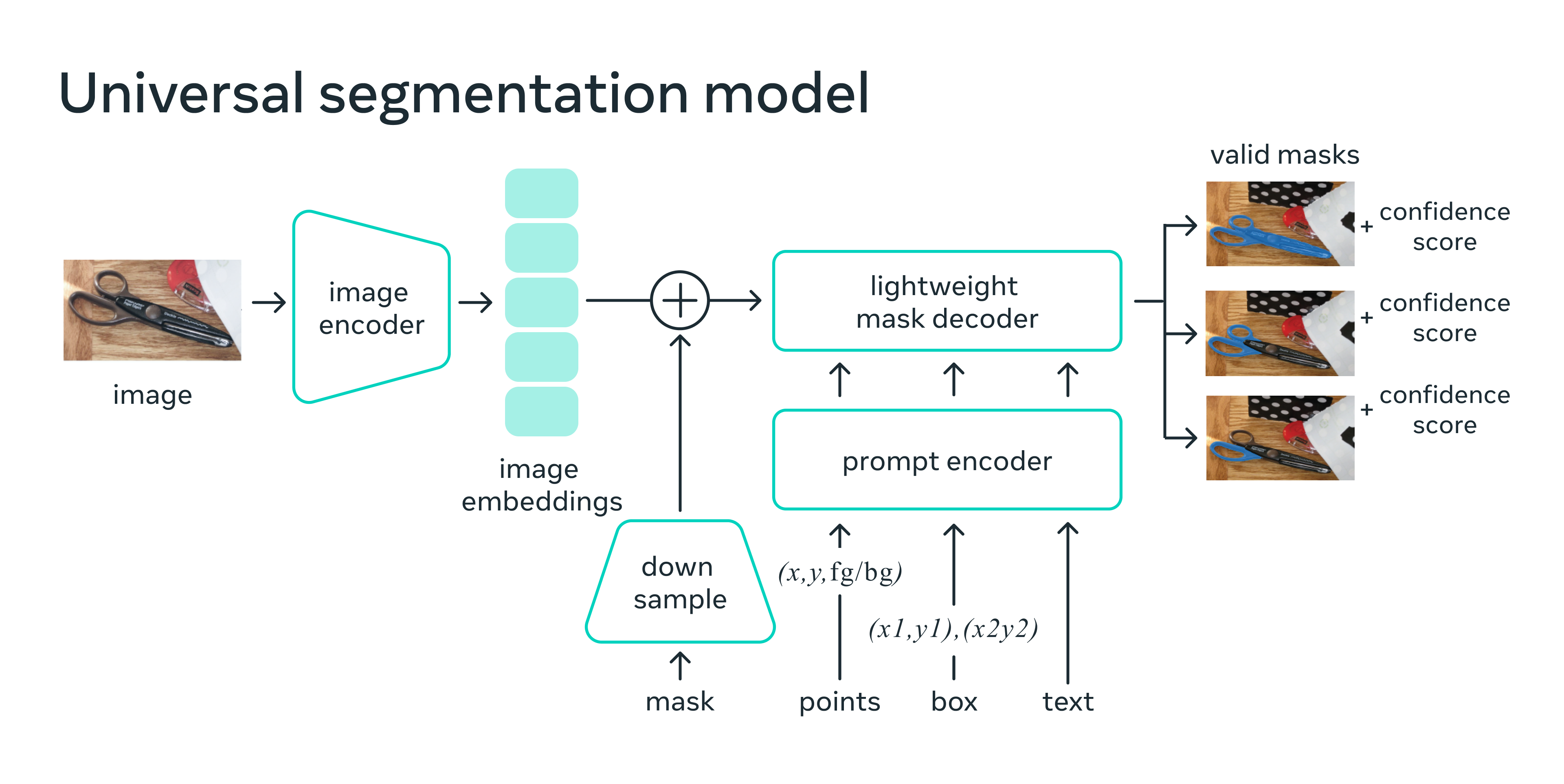
Diving deeper into SAM’s architecture, we can explore its key components:
- Image encoder: SAM’s default image encoder is ViT-H, but it can also utilize ViT-L or ViT-B depending on the specific requirements.
- Downsample: To reduce the resolution of the prompt binary mask, a series of convolutional layers are employed.
- Prompt encoder: Positional embeddings are used to encode various input prompts, which help inform the model about the location and context of objects within the image.
- Mask decoder: A modified transformer encoder serves as the mask decoder, translating the encoded prompts and image embeddings into the final object masks.
- Valid masks: For any given prompt, SAM generates the three most relevant masks, providing users with an array of options to choose from.
They’ve trained the model with a weighted combination of focal, dice, and IoU loss. With weights 20, 1, 1 respectively.
The strength of SAM lies in its adaptability and flexibility, as it can work with different prompt types to generate accurate segmentation masks. Much like foundational Language Models (LLMs), which serve as a strong base for various natural language processing applications, SAM also provides a solid foundation for computer vision tasks. The model’s architecture has been designed to facilitate easy fine-tuning for downstream tasks, enabling it to be tailored to specific use cases or domains. By fine-tuning SAM on task-specific data, developers can enhance its performance and ensure that it meets the unique requirements of their application.
This capacity for fine-tuning not only allows SAM to achieve impressive performance in a variety of scenarios but also promotes a more efficient development process. With pre-trained models serving as a starting point, developers can focus on optimizing the model for their specific task, rather than starting from scratch. This approach not only saves time and resources but also leverages the extensive knowledge encoded in the pre-trained model, resulting in a more robust and accurate system.
Natural Language prompts
The integration of text prompts with the SAM enables the model to perform highly specific and context-aware object segmentation. By leveraging natural language prompts, SAM can be guided to segment objects of interest based on their semantic properties, attributes, or relationships to other objects within the scene.
In the process of training SAM, the largest publicly available CLIP model (ViT-L/14@336px) is used to compute text and image embeddings. These embeddings are normalized before being utilized in the training process.
To generate training prompts, the bounding box around each mask is first expanded by a random factor ranging from 1x to 2x. The expanded box is then square-cropped to maintain its aspect ratio and resized to 336×336 pixels. Before feeding the crop to the CLIP image encoder, pixels outside the mask are zeroed out with a 50% probability. Masked attention is used in the last layer of the encoder to ensure the embedding focuses on the object, restricting attention from the output token to the image positions inside the mask. The output token embedding serves as the final prompt. During training, the CLIP-based prompt is provided first, followed by iterative point prompts to refine the prediction.
For inference, the unmodified CLIP text encoder is used to create a prompt for SAM. The model relies on the alignment of text and image embeddings achieved by CLIP, which enables training without explicit text supervision while still using text-based prompts for inference. This approach allows SAM to effectively leverage natural language prompts to achieve accurate and context-aware segmentation results.
Unfortunately, Meta hasn’t released the weights of SAM with a text encoder (yet?).
Luca’s Project: lang-segment-anything
The lang-segment-anything library presents an innovative approach to object detection and segmentation by combining the strengths of GroundingDino and SAM.
Initially, GroundingDino performs zero-shot text-to-bounding-box object detection, efficiently identifying objects of interest in images based on natural language descriptions. These bounding boxes are then used as input prompts for the SAM model, which generates precise segmentation masks for the identified objects.
from PIL import Image
from lang_sam import LangSAM
from lang_sam.utils import draw_image
model = LangSAM()
image_pil = Image.open('./assets/car.jpeg').convert("RGB")
text_prompt = 'car, wheel'
masks, boxes, labels, logits = model.predict(image_pil, text_prompt)
image = draw_image(image_pil, masks, boxes, labels)
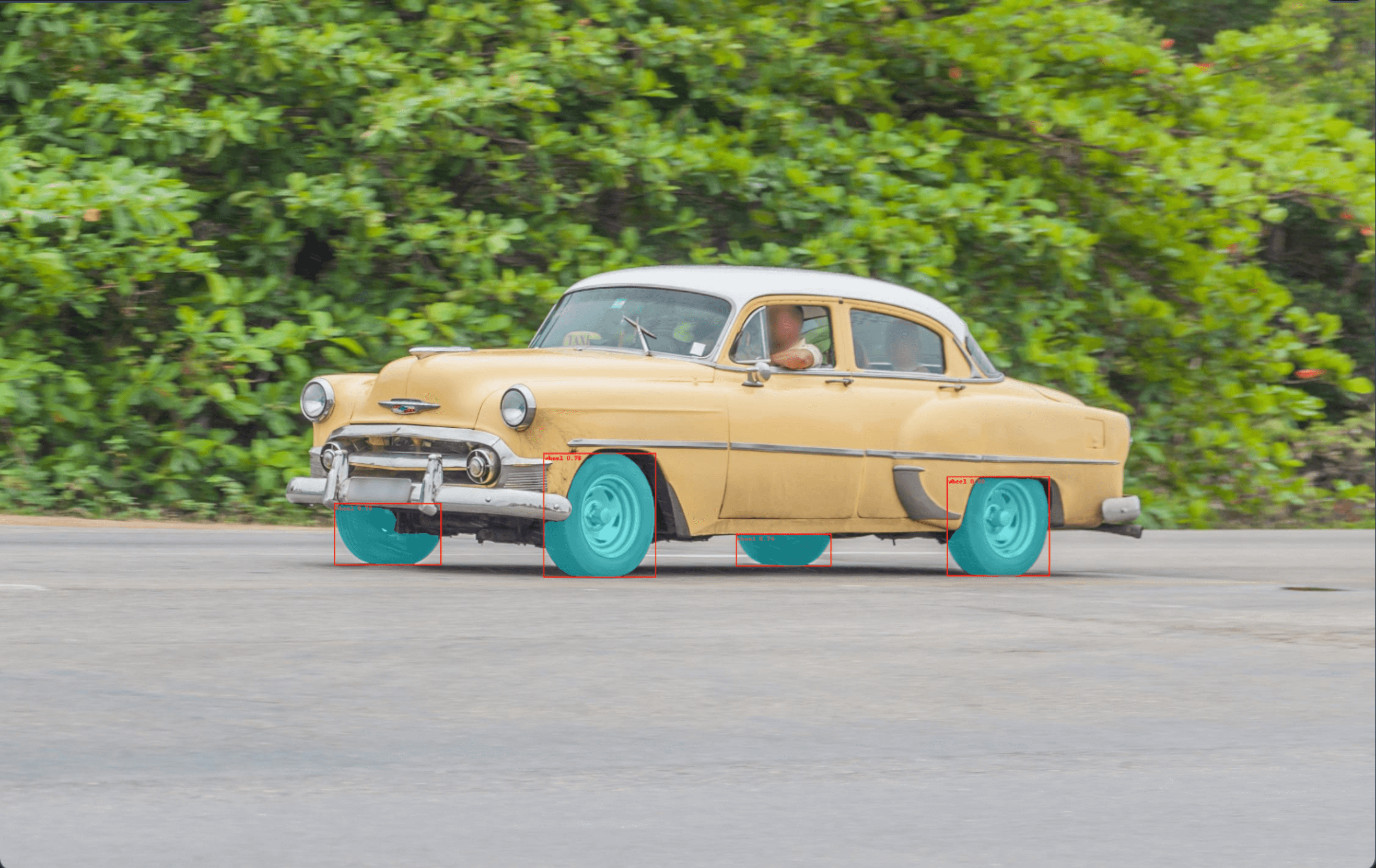
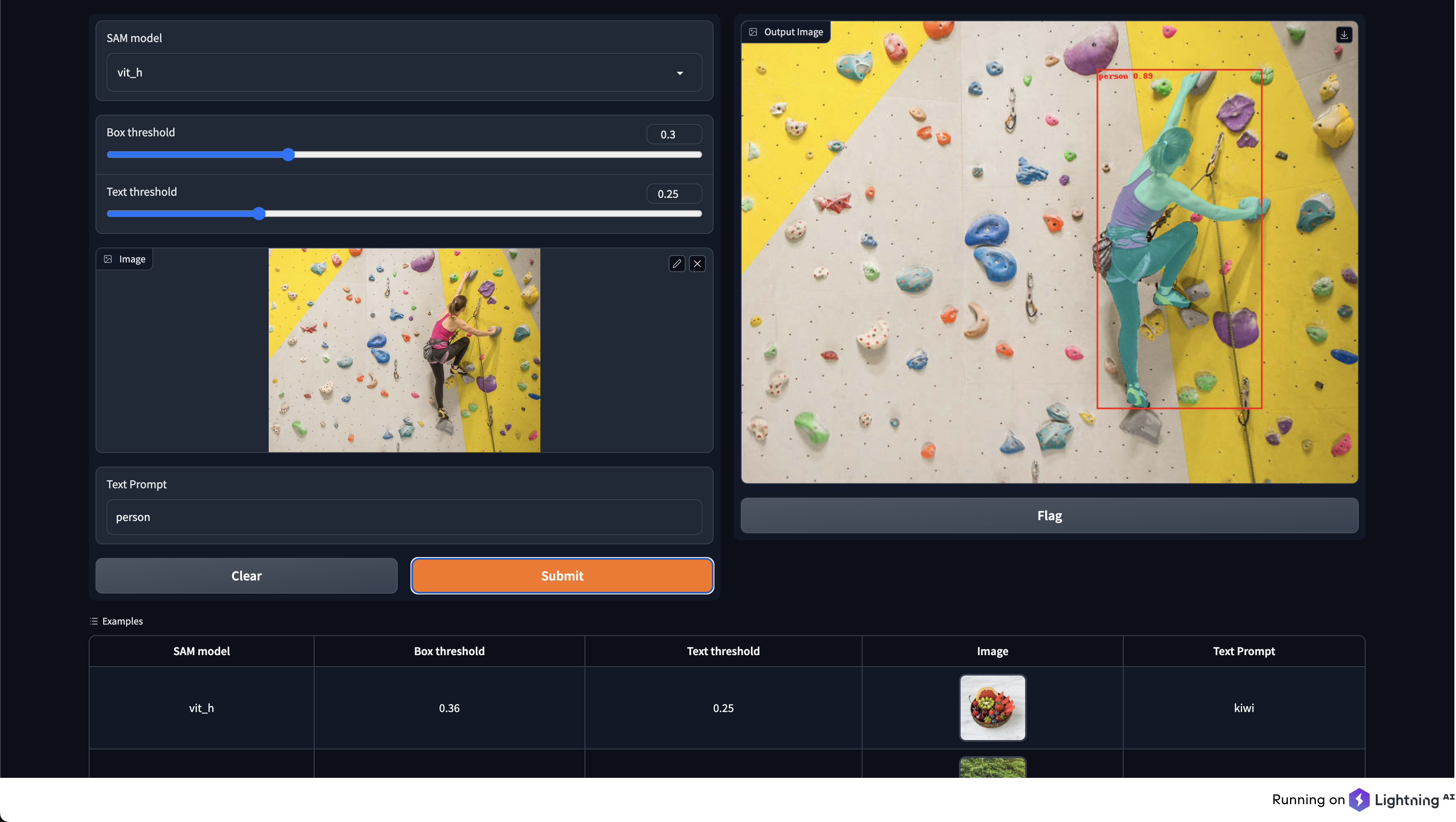
Lightning App
You can quickly deploy an application using the Lightning AI App framework. We will use ServeGradio component to deploy our model with UI. You can learn more about ServeGradio here.
import os
import gradio as gr
import lightning as L
import numpy as np
from lightning.app.components.serve import ServeGradio
from PIL import Image
from lang_sam import LangSAM
from lang_sam import SAM_MODELS
from lang_sam.utils import draw_image
from lang_sam.utils import load_image
class LitGradio(ServeGradio):
inputs = [
gr.Dropdown(choices=list(SAM_MODELS.keys()), label="SAM model", value="vit_h"),
gr.Slider(0, 1, value=0.3, label="Box threshold"),
gr.Slider(0, 1, value=0.25, label="Text threshold"),
gr.Image(type="filepath", label='Image'),
gr.Textbox(lines=1, label="Text Prompt"),
]
outputs = [gr.outputs.Image(type="pil", label="Output Image")]
def __init__(self, sam_type="vit_h"):
super().__init__()
self.ready = False
self.sam_type = sam_type
def predict(self, sam_type, box_threshold, text_threshold, image_path, text_prompt):
print("Predicting... ", sam_type, box_threshold, text_threshold, image_path, text_prompt)
if sam_type != self.model.sam_type:
self.model.build_sam(sam_type)
image_pil = load_image(image_path)
masks, boxes, phrases, logits = self.model.predict(image_pil, text_prompt, box_threshold, text_threshold)
labels = [f"{phrase} {logit:.2f}" for phrase, logit in zip(phrases, logits)]
image_array = np.asarray(image_pil)
image = draw_image(image_array, masks, boxes, labels)
image = Image.fromarray(np.uint8(image)).convert("RGB")
return image
def build_model(self, sam_type="vit_h"):
model = LangSAM(sam_type)
self.ready = True
return model
app = L.LightningApp(LitGradio())
And just like that, the app is launched in the browser!
Conclusion
And that’s a wrap on our introduction to the Segment Anything Model. It’s clear that SAM is a valuable tool for computer vision researchers and developers alike, with its ability to handle a wide range of segmentation tasks and adapt to different prompt types. Its architecture allows for easy implementation, making it versatile enough to be tailored to specific use cases and domains. Overall, SAM has quickly become an important asset for the machine learning community and is sure to continue making waves in the field.
About the Author
I’m Luca Medeiros, computer vision engineer and champion ambassador of Lightning League. I am interested in multimodal models and am an OSS enthusiast.

