The Fragmented World of Machine Learning/MLOps
At June’s inaugural Lightning Developer Conference, Founder and CEO William Falcon’s keynote explored the state of artificial intelligence, and how it’s reached the growth stage that often leads to industry-wide fragmentation as companies struggle to standardize. You can watch a key excerpt from the keynote below, or continue reading to learn how Lightning AI is solving this problem.
As a researcher, there is often little incentive to move beyond building and training machine learning models for any given project. Either because that research is a purely academic exercise that ends with a publication, or because other factors impinge upon the production of a real-world application which incorporates that model.
Issues begin to arise when that model moves into production for industry-based applications. These can include, for instance, a need for tools and techniques unavailable in simple model-training workflows: feature stores, deployment strategies, caching at scale with Redis, database management, and on-prem or cloud-based infrastructure. Moving beyond model building and training forces researchers and industry professionals to juggle a wide number of third-party tools and services.
By leveraging a vast network of dedicated and committed AI researchers, building and training models for a variety of use cases has become increasingly streamlined. The same cannot be said for processes that exist beyond the remit of building and training models – in fact, given the surfeit of tools that spring up each year, those processes have only become more complex. This complexity is the primary reason that a recent KDNuggets poll estimated that over 80% of models never go into production or get deployed.
In other words, the model itself is no longer the hard thing: it’s everything else that’s hard. Why? Countless companies are currently trying to solve specific problems at this stage of machine learning development: data pipelining, deployments, retrainings, model management, collaboration, as well as new problems that continue to surface. This is a fragmentation problem.

Standardization as a Pathway to Overcoming Fragmentation
The problem of fragmentation is not unique to AI. As a given field expands, and as more companies jump into the mix to offer solutions to specific problems, it becomes increasingly difficult for solutions to integrate seamlessly with each other. Moreover, private companies often have vested interests in ensuring that their solutions don’t interact properly with others in an effort to establish the dominance of their tools, ecosystem, or platform.
Over the last few decades, artificial intelligence frameworks and platforms have appeared, failed, or otherwise consolidated to grab a larger market share. In recent years, as AI has moved rapidly into virtually every industry, applications that use machine learning have gained widespread adoption. The fragmentation problem that AI currently faces is the direct result of this swift growth in both the adoption of machine learning technology as well as the number of players entering the field.
To better understand this problem and how we might solve it, we can consider cars as analogous to this situation.
When the first automotive vehicles became available to consumers, we didn’t know that we needed seatbelts, or that we could have things like air conditioning, radios, or electric engines. As the technology matured, we discovered that there were many things needed to make cars better, more efficient, and more user-friendly. While there’s nothing technically wrong with having dozens of different kinds of tires for a car, a lack of standardization means that getting fifty cars on the same road – all with different kinds of tires, and spacing, and heights and widths – would pose a significant challenge.
 Without a standardized platform for developing wheels and tires, companies in the wheel and tire industry face significant challenges: how much of each size to manufacture? Which takes precedence? In the absence of resources, which sizes get deprioritized? Can cars with large differences in the sizing of their tires drive safely together? Once a standardized platform for cars was established, it unlocked the ability for the automobile industry to scale beyond where they were before, while also lowering costs and saving time.
Without a standardized platform for developing wheels and tires, companies in the wheel and tire industry face significant challenges: how much of each size to manufacture? Which takes precedence? In the absence of resources, which sizes get deprioritized? Can cars with large differences in the sizing of their tires drive safely together? Once a standardized platform for cars was established, it unlocked the ability for the automobile industry to scale beyond where they were before, while also lowering costs and saving time.
Another example a little closer to home is the computer industry. Early on, everyone had their own way of doing things and there weren’t really any standards: getting components to fit in computers from different companies was a nightmare. The development of standards that dictate how everything in a computer fits and works together was critically important to widespread adoption. For example, if you build your own machine today, you can choose from hundreds of different kinds of RAM! This flexibility is only possible because of the standardized platform that enables computer components to work together seamlessly.
 The automobile and computer industries both hit a fragmentation stage, and both were able to overcome this problem by pursuing standardization. The development of novel technologies almost always runs into the problem of fragmentation: what matters is both whether and how it can overcome it.
The automobile and computer industries both hit a fragmentation stage, and both were able to overcome this problem by pursuing standardization. The development of novel technologies almost always runs into the problem of fragmentation: what matters is both whether and how it can overcome it.
The Evolution of Lightning AI
Lightning started trying to solve the fragmentation problem a few years back. In 2021, we solved an important piece: training at scale with PyTorch Lightning. This open source framework has gained rapid adoption by researchers and developers, with over 4 million downloads per month as people are looking to build faster by abstracting away unnecessary engineering boilerplate.
We then introduced Grid, a platform where you can train thousands of machine learning models on the cloud from your laptop as you scale.
 This solved a host of concurrent problems: needing interactive notebooks, access to GPUs, the ability to run experiments, and other requirements like on-demand infrastructure. As people used Grid and PyTorch Lightning in concert, we noticed a number of frequent and recurring questions:
This solved a host of concurrent problems: needing interactive notebooks, access to GPUs, the ability to run experiments, and other requirements like on-demand infrastructure. As people used Grid and PyTorch Lightning in concert, we noticed a number of frequent and recurring questions:
- “where are my checkpoints?”
- “my training is done, where is my best checkpoint?”
- “what if I want to use an experiment manager?”
- “If I do, which one do I pick and how do I swap them out?”
Grid and PyTorch Lightning both offered solutions to individual problems. As we scaled, we asked ourselves: what other solutions would we develop, and how could we get them all to work together?
The Problem of Applying DevOps to Machine Learning
At least part of the fragmentation problem that machine learning faces is a result of the industry’s current status quo. That status quo involves a number of disparate tools and technologies: DAGs, YAMLs, Kubernetes, the list goes on. The issue is that as the adoption of AI continues to rapidly expand, people doing research, or building models, or working with industry applications like fraud detection just want their tools to work. They don’t care how it’s being done, as long as it works. In this respect, the status quo – which involves a wide set of expertise – is really difficult to change.
 If Lightning had followed the industry status quo, then what we built would have been broken (in other words, fragmented!) into many independent parts:
If Lightning had followed the industry status quo, then what we built would have been broken (in other words, fragmented!) into many independent parts:
- The introduction of a DAG framework
- Some sort of workflow scheduler
- Either infrastructure-as-code, or a YAML generator
- We would then need to add a framework to build ML-powered apps (but there isn’t even a standard, agreed-upon definition for that!)
- Next, a UI to connect all these pieces together
- Finally, a method of collaboration – without this, getting a project off the ground is next to impossible.
 How Lightning AI Addresses the AI Fragmentation Problem
How Lightning AI Addresses the AI Fragmentation Problem
In the end, we decided to do things the Lightning way. We didn’t want to do six things or build a laundry list of disparate tools. Instead, we built a single solution that unifies the entire lifecycle of machine learning development. (And no, this isn’t too good to be true!)
Lightning AI makes it possible to turn your models into scalable machine learning systems in days, not months.
 We developed Lightning Apps so that you don’t have to think about infrastructure or how things are happening. Instead, Lightning lets you focus on imagining your next AI project.
We developed Lightning Apps so that you don’t have to think about infrastructure or how things are happening. Instead, Lightning lets you focus on imagining your next AI project.
So, what can you build with Lightning? Here are a couple of examples:
- Model development project: string together a framework, grab some databases and an experiment manager.
- ETL (Extract Transform Load) app: you don’t even need a model with this, just build a straightforward data pipeline.
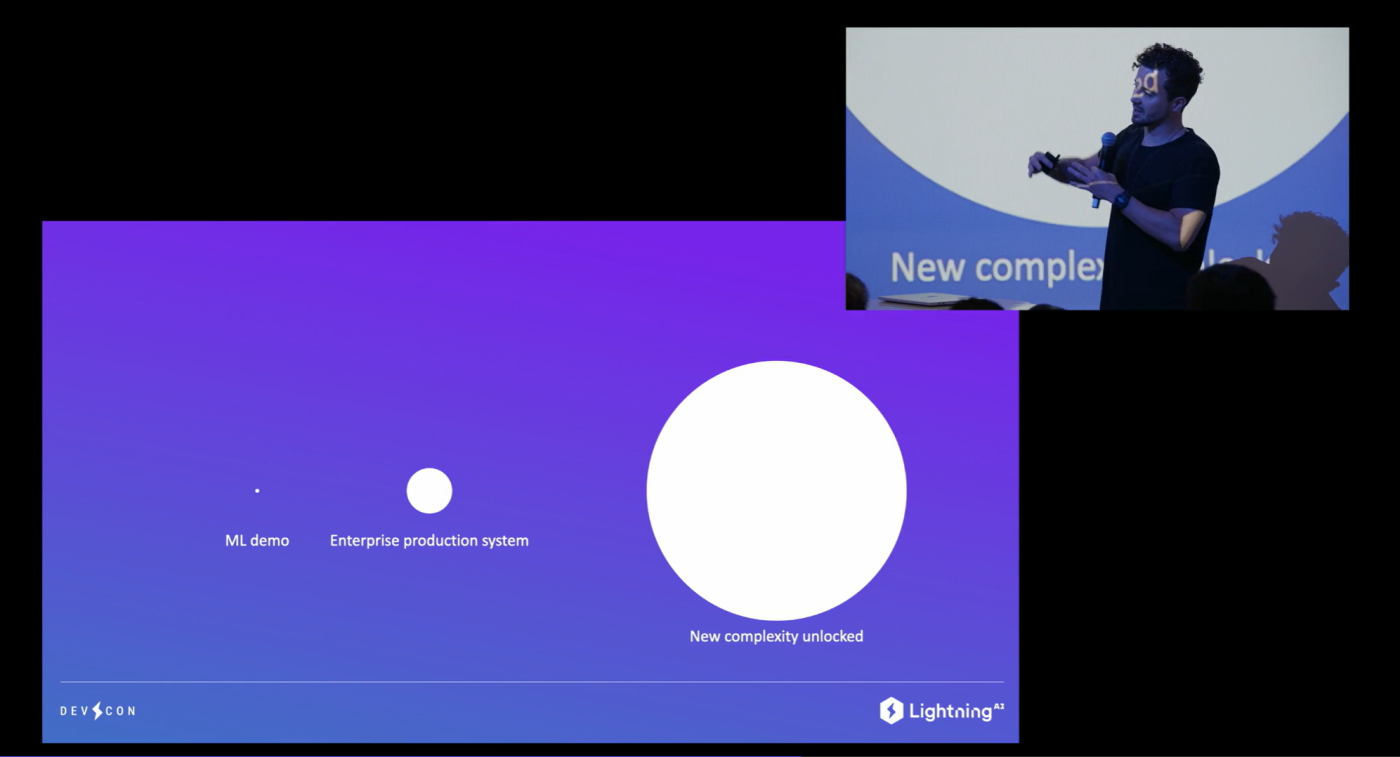
In other words, Lightning makes building machine learning systems simple. Today, that process is incredibly complex. Building an interactive UI for a simple machine learning demo might be attainable, but the moment that system enters large-scale production, fragmentation rears its ugly head and makes the process infinitely more complex. A host of moving parts like different environments, fault tolerances, local debugging, environment variables, systems of servability, and failure monitoring all add up to a process that is incredibly challenging for enterprises to overcome.
With Lightning AI, you can build complex systems that are currently a bottleneck for a number of industries without dealing with any of the difficult engineering. All of these various needs can be developed into a Lightning Component or Lightning App, and you can combine them together in a way that tackles your particular use case. This can be purely research focused, or a full ML pipeline that puts your research into production. It’s entirely up to you.
 Companies like NVIDIA, MARS, and JPMC are already building with Lightning. Leading educational institutions like Columbia University are also finding success with Lightning Apps. The only limit is your imagination.
Companies like NVIDIA, MARS, and JPMC are already building with Lightning. Leading educational institutions like Columbia University are also finding success with Lightning Apps. The only limit is your imagination.
Find out more at https://lightning.ai/


