Takeaways
Discover how to use PyTorch Lightning or Lightning Fabric to pretrain your custom model checkpoints or finetune LLMs like CodeLLaMA and LLama 2.Introduction
PyTorch Lightning and Lightning Fabric enable researchers and machine learning engineers to train PyTorch models at scale. Both frameworks do the heavy lifting for you and orchestrate training across multi-GPU and multi-Node environments. All you need to bring is a PyTorch module! And maybe a GPU 😆. So, why are there two frameworks?
Short answer: varying levels of abstraction and control provide the versatility you need for a great development experience.
In other words – we’ve built some really useful features for you so that you don’t have to. Depending on your need, you can choose either framework based on the amount of abstraction and control that you need or want. This is all about placing the power in your hands to get the job done in the way that works best for you.
Similarities of PyTorch Lightning and Lightning Fabric
Becoming familiar with the shared features is a good starting point for understanding why we have two frameworks that focus on model training. Why do they share features? Because they are both built with the same tasks in mind, and we want to make the development experience as seamless as possible for you.
A common benefit of PyTorch Lightning and Lightning Fabric is that both frameworks enable researchers and machine learning engineers to train in multi-device and multi-node environments with common flags such as devices, num_nodes, and strategy. Where devices is either the number of devices (CPUs, GPUs, TPUs or others) to train on, or the specific devices to train on given a multi-device environment. The num_nodes flag is used to set the number of clusters in a multi-node environment. And strategy is used to select the distributed training strategy i.e. DDP, FSDP, or DeepSpeed.
use the accelerator flag along with devices to properly set the device type i.e. CPU, GPU, or TPU.
Why is this a good thing? The ecosystem has a standard naming convention so that we can easily port concepts from one framework to the other. Meaning, we won’t have to learn new argument names to do the same task.
import pytorch_lightning as pl trainer = pl.Trainer( accelerator="gpu", devices=2, num_nodes=1, strategy="ddp", )
from lightning_fabric import Fabric fabric = Fabric( accelerator="gpu", devices=2, num_nodes=1, strategy="ddp", )
When to Use PyTorch Lightning or Lightning Fabric
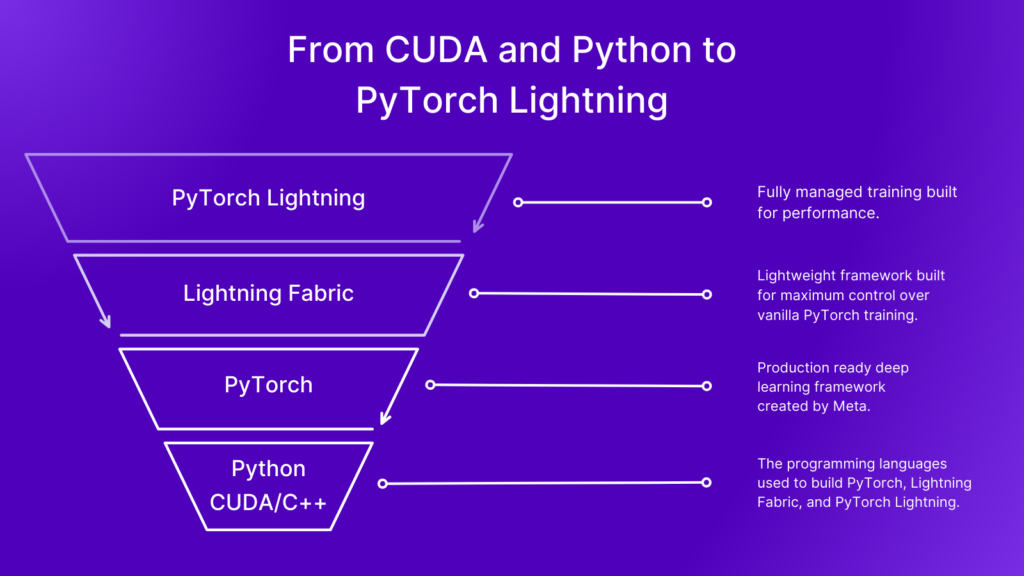
So, what makes the two frameworks different? Lightning Fabric offers more control by integrating directly into the PyTorch training loop and PyTorch Lightning offers a fully managed training solution with Trainer, LightningModule, and LightningDataModule. The image shown below represents this relationship to the PyTorch training loop, and the amount of features that we’ve built for you in either framework.

Now, let’s discuss some of the trade offs that are implied by this abstraction and control spectrum shown in the image – and how these trade offs may affect which framework we are going to choose.
Lightning Fabric
Lightning Fabric is a lightweight framework that has just one core API class – Fabric. That core class handles tasks such as autocasting, broadcasting, gathering, and checkpoint loading and saving. Fabric has what you need to run training at scale without a tedious refactoring process. The image below shows how easy it is to implement Lightning Fabric into PyTorch training logic.

The code snippet above with highlighted diff, illustrates how few changes are needed to migrate from simple vanilla PyTorch code to Fabric. Beyond this minor code change (nothing more is needed except setting some arguments/parameters) you gained all the power of Fabric – mixed precision, scaling to multiple devices/nodes, checkpointing and much more!
When should you use Lightning Fabric?
- When you have an existing PyTorch training loop, and need to scale the training.
- When you are an experienced PyTorch and PyTorch Lightning user who requires keeping close touch with your training flow.
import torch
from lightning_fabric import Fabric
from pytorch_lightning.demos import WikiText2, Transformer
fabric = Fabric(
accelerator="gpu",
devices=2,
num_nodes=1,
strategy="ddp",
)
fabric.launch()
dataset = WikiText2()
dataloader = torch.utils.data.DataLoader(dataset)
model = Transformer(vocab_size=dataset.vocab_size)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
model, optimizer = fabric.setup(model, optimizer)
dataloader = fabric.setup_dataloaders(dataloader)
model.train()
for epoch in range(20):
for batch in dataloader:
inputs, target = batch
optimizer.zero_grad()
output = model(inputs, target)
loss = torch.nn.functional.nll_loss(output, target.view(-1))
fabric.backward(loss)
optimizer.step()
PyTorch Lightning
PyTorch Lightning’s core API consists of three classes – LightningModule, Trainer, and LightningDataModule. Trainer offers a robust managed training experience, LightningModule wraps PyTorch’s nn.Module with several methods to clearly define the training process , and LightningDataModule encapsulates all the data processing. These three core classes pack a lot of functionality into PyTorch Lightning and enable research such as Stability AI’s Generative Models.
Why would you choose PyTorch Lightning over raw PyTorch or Lightning Fabric?
- When you use mainstream models and/or for training you use standard training loops.
- If your goal is simple code without any boilerplate which is easier to share.
See Lightly, Asteroid, PyTorch Forecasting, scvi-tools, and Hyena-DNA for additional PyTorch Lightning use cases.
import torch
from torch.utils.data import random_split, DataLoader
import pytorch_lightning as pl
from pytorch_lightning import Trainer
from pytorch_lightning.demos import Transformer, WikiText2
class LightningTransformer(pl.LightningModule):
def __init__(self, vocab_size):
super().__init__()
self.model = Transformer(vocab_size=vocab_size)
def forward(self, batch):
inputs, target = batch
return self.model(inputs.view(1, -1), target.view(1, -1))
def training_step(self, batch, batch_idx):
inputs, target = batch
output = self.model(inputs.view(1, -1), target.view(1, -1))
loss = torch.nn.functional.nll_loss(output, target.view(-1))
return loss
def configure_optimizers(self):
return torch.optim.SGD(self.model.parameters(), lr=0.1)
if __name__ == "__main__":
dataset = WikiText2()
train, val = random_split(dataset, [0.8, 0.2])
train_dataloader = DataLoader(train)
val_dataloader = DataLoader(val)
model = LightningTransformer(vocab_size=dataset.vocab_size)
trainer = Trainer(
max_epochs=1,
accelerator = "gpu",
devices = 2,
num_nodes = 1,
strategy = "ddp",
)
trainer.fit(
model,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader,
)
Powered by Lightning AI
Together with TorchMetrics, PyTorch Lightning and Lightning Fabric exist as part of an ecosystem that drives the latest research and brings it to production. The following industry and community projects are powered by Lightning AI’s open source frameworks under the hood:
- Lit-GPT is a hackable implementation of state-of-the-art open-source LLMs built by Lightning AI.
- Tiny LLama, by Lance Zhang, is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.
- SDXL is v2 of Stability AI’s Stable Diffusion text-to-image generation model.
- NVIDIA’s NeMo is a cloud native framework to build and deploy generative AI.
- HyenaDNA, by Stanford’s Hazy Research, is the first recurrent model that is competitive with large scale transformers.
Still Have Questions?
We have an amazing community and team of core engineers ready to answer questions you might have about PyTorch Lightning and Lightning Fabric. So, join us on Discourse, GitHub Discussions, or Discord. See you there!

