←
Back
to glossary 
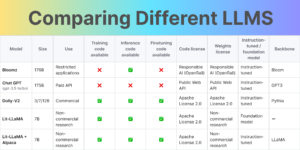
LLaMA
LLaMA is a foundational large language model that has been released by Meta AI. LLaMA comes in four size variants: 7B, 13B, 33B, and 65B parameters. The paper shows that training smaller foundation models on large enough tokens is desirable, as it requires less computing power and resources. The 65B parameter models have been trained on 1.4 trillion tokens, while the LLaMA 7B model has been trained on 1 trillion tokens.
Related content