←
Back
to glossary
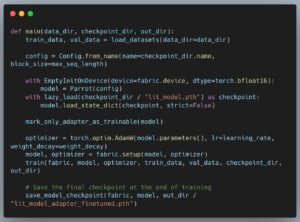
GPTQ
GPTQ is a one-shot weight quantization method based on approximate second-order information, enabling efficient compression of GPT models with 175 billion parameters while preserving accuracy, allowing for single-GPU execution and significant inference speedups over FP16.