Communication between distributed processes¶
With Fabric, you can easily access information about a process or send data between processes with a standardized API and agnostic to the distributed strategy.
Rank and world size¶
The rank assigned to a process is a zero-based index in the range of 0, …, world size - 1, where world size is the total number of distributed processes. If you are using multi-GPU, think of the rank as the GPU ID or GPU index, although rank generally extends to distributed processing.
The rank is unique across all processes, regardless of how they are distributed across machines, and it is therefore also called global rank. We can also identify processes by their local rank, which is unique among processes running on the same machine but is not unique globally across all machines. Finally, each process is associated with a node rank in the range 0, …, num nodes - 1, which identifies which machine (node) the process is running on.

Here is how you launch multiple processes in Fabric:
from lightning.fabric import Fabric
# Devices and num_nodes determine how many processes there are
fabric = Fabric(devices=2, num_nodes=3)
fabric.launch()
Learn more about launching distributed training. And here is how you access all rank and world size information:
# The total number of processes running across all devices and nodes
fabric.world_size # 2 * 3 = 6
# The global index of the current process across all devices and nodes
fabric.global_rank # -> {0, 1, 2, 3, 4, 5}
# The index of the current process among the processes running on the local node
fabric.local_rank # -> {0, 1}
# The index of the current node
fabric.node_rank # -> {0, 1, 2}
# Do something only on rank 0
if fabric.global_rank == 0:
...
Avoid race conditions¶
Access to the rank information helps you avoid race conditions which could crash your script or lead to corrupted data. Such conditions can occur when multiple processes try to write to the same file simultaneously, for example, writing a checkpoint file or downloading a dataset. Avoid this from happening by guarding your logic with a rank check:
# Only write files from one process (rank 0) ...
if fabric.global_rank == 0:
with open("output.txt", "w") as file:
file.write(...)
# ... or save from all processes but don't write to the same file
with open(f"output-{fabric.global_rank}.txt", "w") as file:
file.write(...)
# Multi-node: download a dataset, the filesystem between nodes is shared
if fabric.global_rank == 0:
download_dataset()
# Multi-node: download a dataset, the filesystem between nodes is NOT shared
if fabric.local_rank == 0:
download_dataset()
Barrier¶
The barrier forces every process to wait until all processes have reached it. In other words, it is a synchronization.

A barrier is needed when processes do different amounts of work and as a result fall out of sync.
fabric = Fabric(accelerator="cpu", devices=4)
fabric.launch()
# Simulate each process taking a different amount of time
sleep(2 * fabric.global_rank)
print(f"Process {fabric.global_rank} is done.")
# Wait for all processes to reach the barrier
fabric.barrier()
print("All processes reached the barrier!")
A more realistic scenario is when downloading data. Here, we need to ensure that processes only start to load the data once it has completed downloading. Since downloading should be done on rank 0 only to avoid race conditions, we need a barrier:
if fabric.global_rank == 0:
print("Downloading dataset. This can take a while ...")
download_dataset()
# All other processes wait here until rank 0 is done with downloading:
fabric.barrier()
# After everyone reached the barrier, they can access the downloaded files:
load_dataset()
Broadcast¶
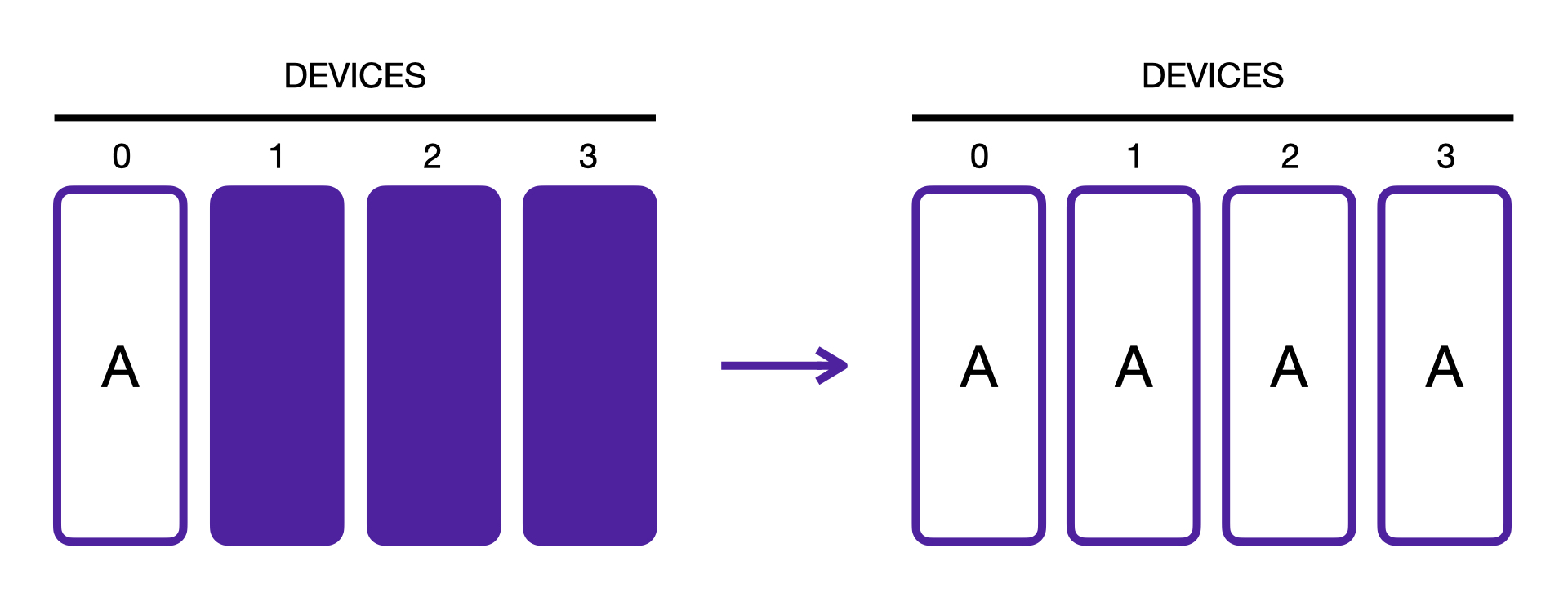
The broadcast operation sends a tensor of data from one process to all other processes so that all end up with the same data.
fabric = Fabric(...)
# Transfer a tensor from one process to all the others
result = fabric.broadcast(tensor)
# By default, the source is the process rank 0 ...
result = fabric.broadcast(tensor, src=0)
# ... which can be change to a different rank
result = fabric.broadcast(tensor, src=3)
A concrete example:
fabric = Fabric(devices=4, accelerator="cpu")
fabric.launch()
# Data is different on each process
learning_rate = torch.rand(1)
print("Before broadcast:", learning_rate)
# Transfer the tensor from one process to all the others
learning_rate = fabric.broadcast(learning_rate)
print("After broadcast:", learning_rate)
Gather¶
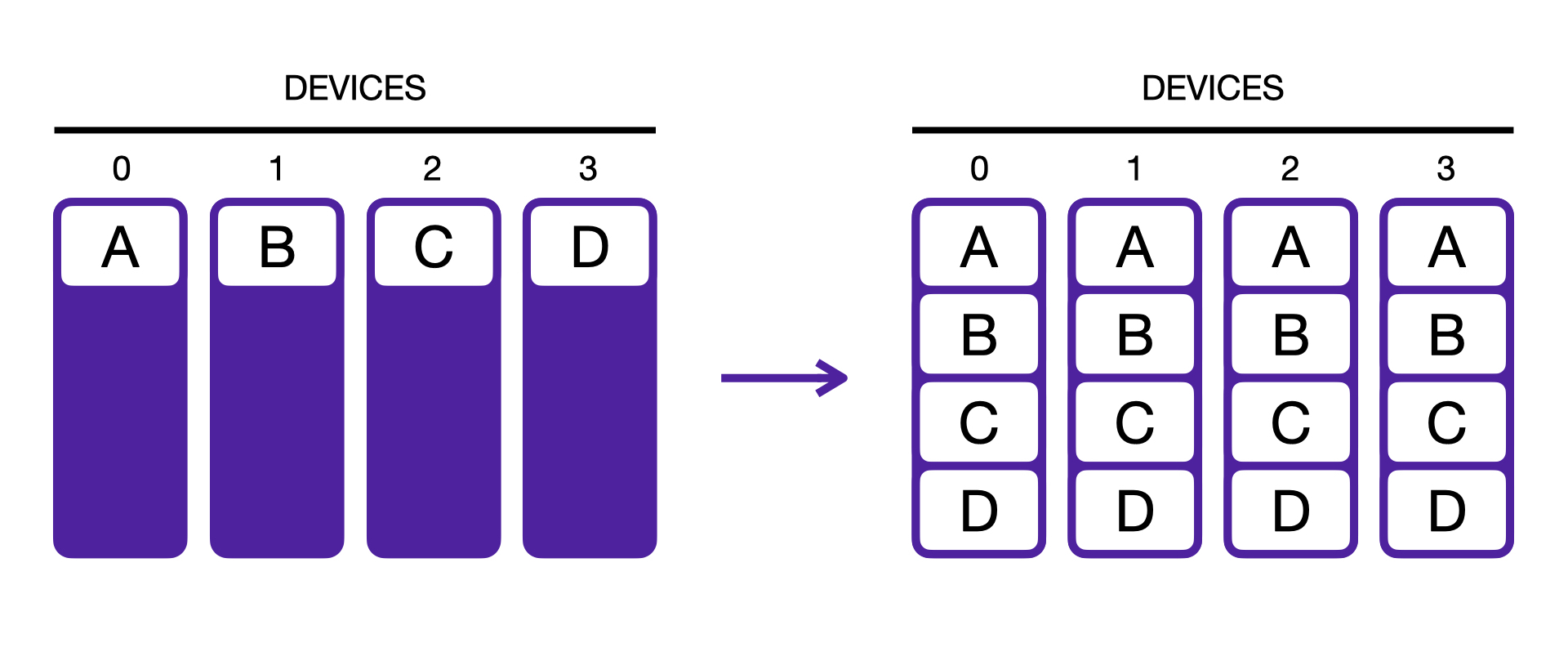
The gather operation transfers the tensors from each process to every other process and stacks the results. As opposed to the broadcast, every process gets the data from every other process, not just from a particular rank.
fabric = Fabric(...)
# Gather the data from
result = fabric.all_gather(tensor)
# Tip: Turn off gradient syncing if you don't need to back-propagate through it
with torch.no_grad():
result = fabric.all_gather(tensor)
A concrete example:
fabric = Fabric(devices=4, accelerator="cpu")
fabric.launch()
# Data is different in each process
result = torch.tensor(10 * fabric.global_rank)
# Every process gathers the tensors from all other processes
# and stacks the result:
result = fabric.all_gather(data)
print("Result of all-gather:", result) # tensor([ 0, 10, 20, 30])

