Tutorial 8: Deep Autoencoders¶
Author: Phillip Lippe
License: CC BY-SA
Generated: 2023-03-14T16:01:45.301102
In this tutorial, we will take a closer look at autoencoders (AE). Autoencoders are trained on encoding input data such as images into a smaller feature vector, and afterward, reconstruct it by a second neural network, called a decoder. The feature vector is called the “bottleneck” of the network as we aim to compress the input data into a smaller amount of features. This property is useful in many applications, in particular in compressing data or comparing images on a metric beyond pixel-level comparisons. Besides learning about the autoencoder framework, we will also see the “deconvolution” (or transposed convolution) operator in action for scaling up feature maps in height and width. Such deconvolution networks are necessary wherever we start from a small feature vector and need to output an image of full size (e.g. in VAE, GANs, or super-resolution applications). This notebook is part of a lecture series on Deep Learning at the University of Amsterdam. The full list of tutorials can be found at https://uvadlc-notebooks.rtfd.io.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Slack
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "pytorch-lightning>=1.4, <2.0.0" "seaborn" "torch>=1.8.1, <1.14.0" "torchvision" "matplotlib" "lightning>=2.0.0rc0" "setuptools==67.4.0" "ipython[notebook]>=8.0.0, <8.12.0" "torchmetrics>=0.7, <0.12"
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[2]:
import os
import urllib.request
from urllib.error import HTTPError
import lightning as L
import matplotlib
import matplotlib.pyplot as plt
import matplotlib_inline.backend_inline
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import torchvision
from lightning.pytorch.callbacks import Callback, LearningRateMonitor, ModelCheckpoint
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torchvision.datasets import CIFAR10
from tqdm.notebook import tqdm
%matplotlib inline
matplotlib_inline.backend_inline.set_matplotlib_formats("svg", "pdf") # For export
matplotlib.rcParams["lines.linewidth"] = 2.0
sns.reset_orig()
sns.set()
# Tensorboard extension (for visualization purposes later)
%load_ext tensorboard
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = os.environ.get("PATH_DATASETS", "data")
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/tutorial9")
# Setting the seed
L.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print("Device:", device)
Global seed set to 42
Device: cuda:0
We have 4 pretrained models that we have to download. Remember the adjust the variables DATASET_PATH and CHECKPOINT_PATH if needed.
[3]:
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial9/"
# Files to download
pretrained_files = ["cifar10_64.ckpt", "cifar10_128.ckpt", "cifar10_256.ckpt", "cifar10_384.ckpt"]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print("Downloading %s..." % file_url)
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print(
"Something went wrong. Please try to download the files manually,"
" or contact the author with the full output including the following error:\n",
e,
)
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial9/cifar10_64.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial9/cifar10_128.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial9/cifar10_256.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial9/cifar10_384.ckpt...
In this tutorial, we work with the CIFAR10 dataset. In CIFAR10, each image has 3 color channels and is 32x32 pixels large. As autoencoders do not have the constrain of modeling images probabilistic, we can work on more complex image data (i.e. 3 color channels instead of black-and-white) much easier than for VAEs. In case you have downloaded CIFAR10 already in a different directory, make sure to set DATASET_PATH accordingly to prevent another download.
In contrast to previous tutorials on CIFAR10 like Tutorial 5 (CNN classification), we do not normalize the data explicitly with a mean of 0 and std of 1, but roughly estimate it scaling the data between -1 and 1. This is because limiting the range will make our task of predicting/reconstructing images easier.
[4]:
# Transformations applied on each image => only make them a tensor
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Loading the training dataset. We need to split it into a training and validation part
train_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=transform, download=True)
L.seed_everything(42)
train_set, val_set = torch.utils.data.random_split(train_dataset, [45000, 5000])
# Loading the test set
test_set = CIFAR10(root=DATASET_PATH, train=False, transform=transform, download=True)
# We define a set of data loaders that we can use for various purposes later.
train_loader = data.DataLoader(train_set, batch_size=256, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = data.DataLoader(val_set, batch_size=256, shuffle=False, drop_last=False, num_workers=4)
test_loader = data.DataLoader(test_set, batch_size=256, shuffle=False, drop_last=False, num_workers=4)
def get_train_images(num):
return torch.stack([train_dataset[i][0] for i in range(num)], dim=0)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to /__w/14/s/.datasets/cifar-10-python.tar.gz
Extracting /__w/14/s/.datasets/cifar-10-python.tar.gz to /__w/14/s/.datasets
Global seed set to 42
Files already downloaded and verified
Building the autoencoder¶
In general, an autoencoder consists of an encoder that maps the input 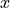 to a lower-dimensional feature vector
to a lower-dimensional feature vector  , and a decoder that reconstructs the input
, and a decoder that reconstructs the input 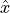 from . We train the model by comparing to and optimizing the parameters to increase the similarity between and . See below for a small illustration of the autoencoder framework.
from . We train the model by comparing to and optimizing the parameters to increase the similarity between and . See below for a small illustration of the autoencoder framework.

We first start by implementing the encoder. The encoder effectively consists of a deep convolutional network, where we scale down the image layer-by-layer using strided convolutions. After downscaling the image three times, we flatten the features and apply linear layers. The latent representation is therefore a vector of size d which can be flexibly selected.
[5]:
class Encoder(nn.Module):
def __init__(self, num_input_channels: int, base_channel_size: int, latent_dim: int, act_fn: object = nn.GELU):
"""
Args:
num_input_channels : Number of input channels of the image. For CIFAR, this parameter is 3
base_channel_size : Number of channels we use in the first convolutional layers. Deeper layers might use a duplicate of it.
latent_dim : Dimensionality of latent representation z
act_fn : Activation function used throughout the encoder network
"""
super().__init__()
c_hid = base_channel_size
self.net = nn.Sequential(
nn.Conv2d(num_input_channels, c_hid, kernel_size=3, padding=1, stride=2), # 32x32 => 16x16
act_fn(),
nn.Conv2d(c_hid, c_hid, kernel_size=3, padding=1),
act_fn(),
nn.Conv2d(c_hid, 2 * c_hid, kernel_size=3, padding=1, stride=2), # 16x16 => 8x8
act_fn(),
nn.Conv2d(2 * c_hid, 2 * c_hid, kernel_size=3, padding=1),
act_fn(),
nn.Conv2d(2 * c_hid, 2 * c_hid, kernel_size=3, padding=1, stride=2), # 8x8 => 4x4
act_fn(),
nn.Flatten(), # Image grid to single feature vector
nn.Linear(2 * 16 * c_hid, latent_dim),
)
def forward(self, x):
return self.net(x)
Note that we do not apply Batch Normalization here. This is because we want the encoding of each image to be independent of all the other images. Otherwise, we might introduce correlations into the encoding or decoding that we do not want to have. In some implementations, you still can see Batch Normalization being used, because it can also serve as a form of regularization. Nevertheless, the better practice is to go with other normalization techniques if necessary like Instance Normalization or Layer Normalization. Given the small size of the model, we can neglect normalization for now.
The decoder is a mirrored, flipped version of the encoder. The only difference is that we replace strided convolutions by transposed convolutions (i.e. deconvolutions) to upscale the features. Transposed convolutions can be imagined as adding the stride to the input instead of the output, and can thus upscale the input. For an illustration of a nn.ConvTranspose2d layer with kernel size 3, stride 2, and padding 1, see below (figure credit - Vincent Dumoulin and Francesco
Visin):

You see that for an input of size 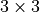 , we obtain an output of
, we obtain an output of 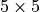 . However, to truly have a reverse operation of the convolution, we need to ensure that the layer scales the input shape by a factor of 2 (e.g.
. However, to truly have a reverse operation of the convolution, we need to ensure that the layer scales the input shape by a factor of 2 (e.g. 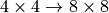 ). For this, we can specify the parameter
). For this, we can specify the parameter output_padding which adds additional values to the output shape. Note that we do not perform zero-padding with this, but rather increase the output shape for calculation.
Overall, the decoder can be implemented as follows:
[6]:
class Decoder(nn.Module):
def __init__(self, num_input_channels: int, base_channel_size: int, latent_dim: int, act_fn: object = nn.GELU):
"""
Args:
num_input_channels : Number of channels of the image to reconstruct. For CIFAR, this parameter is 3
base_channel_size : Number of channels we use in the last convolutional layers. Early layers might use a duplicate of it.
latent_dim : Dimensionality of latent representation z
act_fn : Activation function used throughout the decoder network
"""
super().__init__()
c_hid = base_channel_size
self.linear = nn.Sequential(nn.Linear(latent_dim, 2 * 16 * c_hid), act_fn())
self.net = nn.Sequential(
nn.ConvTranspose2d(
2 * c_hid, 2 * c_hid, kernel_size=3, output_padding=1, padding=1, stride=2
), # 4x4 => 8x8
act_fn(),
nn.Conv2d(2 * c_hid, 2 * c_hid, kernel_size=3, padding=1),
act_fn(),
nn.ConvTranspose2d(2 * c_hid, c_hid, kernel_size=3, output_padding=1, padding=1, stride=2), # 8x8 => 16x16
act_fn(),
nn.Conv2d(c_hid, c_hid, kernel_size=3, padding=1),
act_fn(),
nn.ConvTranspose2d(
c_hid, num_input_channels, kernel_size=3, output_padding=1, padding=1, stride=2
), # 16x16 => 32x32
nn.Tanh(), # The input images is scaled between -1 and 1, hence the output has to be bounded as well
)
def forward(self, x):
x = self.linear(x)
x = x.reshape(x.shape[0], -1, 4, 4)
x = self.net(x)
return x
The encoder and decoder networks we chose here are relatively simple. Usually, more complex networks are applied, especially when using a ResNet-based architecture. For example, see VQ-VAE and NVAE (although the papers discuss architectures for VAEs, they can equally be applied to standard autoencoders).
In a final step, we add the encoder and decoder together into the autoencoder architecture. We define the autoencoder as PyTorch Lightning Module to simplify the needed training code:
[7]:
class Autoencoder(L.LightningModule):
def __init__(
self,
base_channel_size: int,
latent_dim: int,
encoder_class: object = Encoder,
decoder_class: object = Decoder,
num_input_channels: int = 3,
width: int = 32,
height: int = 32,
):
super().__init__()
# Saving hyperparameters of autoencoder
self.save_hyperparameters()
# Creating encoder and decoder
self.encoder = encoder_class(num_input_channels, base_channel_size, latent_dim)
self.decoder = decoder_class(num_input_channels, base_channel_size, latent_dim)
# Example input array needed for visualizing the graph of the network
self.example_input_array = torch.zeros(2, num_input_channels, width, height)
def forward(self, x):
"""The forward function takes in an image and returns the reconstructed image."""
z = self.encoder(x)
x_hat = self.decoder(z)
return x_hat
def _get_reconstruction_loss(self, batch):
"""Given a batch of images, this function returns the reconstruction loss (MSE in our case)"""
x, _ = batch # We do not need the labels
x_hat = self.forward(x)
loss = F.mse_loss(x, x_hat, reduction="none")
loss = loss.sum(dim=[1, 2, 3]).mean(dim=[0])
return loss
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
# Using a scheduler is optional but can be helpful.
# The scheduler reduces the LR if the validation performance hasn't improved for the last N epochs
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", factor=0.2, patience=20, min_lr=5e-5)
return {"optimizer": optimizer, "lr_scheduler": scheduler, "monitor": "val_loss"}
def training_step(self, batch, batch_idx):
loss = self._get_reconstruction_loss(batch)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
loss = self._get_reconstruction_loss(batch)
self.log("val_loss", loss)
def test_step(self, batch, batch_idx):
loss = self._get_reconstruction_loss(batch)
self.log("test_loss", loss)
For the loss function, we use the mean squared error (MSE). The mean squared error pushes the network to pay special attention to those pixel values its estimate is far away. Predicting 127 instead of 128 is not important when reconstructing, but confusing 0 with 128 is much worse. Note that in contrast to VAEs, we do not predict the probability per pixel value, but instead use a distance measure. This saves a lot of parameters and simplifies training. To get a better intuition per pixel, we report the summed squared error averaged over the batch dimension (any other mean/sum leads to the same result/parameters).
However, MSE has also some considerable disadvantages. Usually, MSE leads to blurry images where small noise/high-frequent patterns are removed as those cause a very low error. To ensure realistic images to be reconstructed, one could combine Generative Adversarial Networks (lecture 10) with autoencoders as done in several works (e.g. see here, here or these slides). Additionally, comparing two images using MSE does not necessarily reflect their visual similarity. For instance, suppose the autoencoder reconstructs an image shifted by one pixel to the right and bottom. Although the images are almost identical, we can get a higher loss than predicting a constant pixel value for half of the image (see code below). An example solution for this issue includes using a separate, pre-trained CNN, and use a distance of visual features in lower layers as a distance measure instead of the original pixel-level comparison.
[8]:
def compare_imgs(img1, img2, title_prefix=""):
# Calculate MSE loss between both images
loss = F.mse_loss(img1, img2, reduction="sum")
# Plot images for visual comparison
grid = torchvision.utils.make_grid(torch.stack([img1, img2], dim=0), nrow=2, normalize=True, range=(-1, 1))
grid = grid.permute(1, 2, 0)
plt.figure(figsize=(4, 2))
plt.title(f"{title_prefix} Loss: {loss.item():4.2f}")
plt.imshow(grid)
plt.axis("off")
plt.show()
for i in range(2):
# Load example image
img, _ = train_dataset[i]
img_mean = img.mean(dim=[1, 2], keepdims=True)
# Shift image by one pixel
SHIFT = 1
img_shifted = torch.roll(img, shifts=SHIFT, dims=1)
img_shifted = torch.roll(img_shifted, shifts=SHIFT, dims=2)
img_shifted[:, :1, :] = img_mean
img_shifted[:, :, :1] = img_mean
compare_imgs(img, img_shifted, "Shifted -")
# Set half of the image to zero
img_masked = img.clone()
img_masked[:, : img_masked.shape[1] // 2, :] = img_mean
compare_imgs(img, img_masked, "Masked -")




Training the model¶
During the training, we want to keep track of the learning progress by seeing reconstructions made by our model. For this, we implement a callback object in PyTorch Lightning which will add reconstructions every 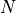 epochs to our tensorboard:
epochs to our tensorboard:
[9]:
class GenerateCallback(Callback):
def __init__(self, input_imgs, every_n_epochs=1):
super().__init__()
self.input_imgs = input_imgs # Images to reconstruct during training
# Only save those images every N epochs (otherwise tensorboard gets quite large)
self.every_n_epochs = every_n_epochs
def on_train_epoch_end(self, trainer, pl_module):
if trainer.current_epoch % self.every_n_epochs == 0:
# Reconstruct images
input_imgs = self.input_imgs.to(pl_module.device)
with torch.no_grad():
pl_module.eval()
reconst_imgs = pl_module(input_imgs)
pl_module.train()
# Plot and add to tensorboard
imgs = torch.stack([input_imgs, reconst_imgs], dim=1).flatten(0, 1)
grid = torchvision.utils.make_grid(imgs, nrow=2, normalize=True, range=(-1, 1))
trainer.logger.experiment.add_image("Reconstructions", grid, global_step=trainer.global_step)
We will now write a training function that allows us to train the autoencoder with different latent dimensionality and returns both the test and validation score. We provide pre-trained models and recommend you using those, especially when you work on a computer without GPU. Of course, feel free to train your own models on Lisa.
[10]:
def train_cifar(latent_dim):
# Create a PyTorch Lightning trainer with the generation callback
trainer = L.Trainer(
default_root_dir=os.path.join(CHECKPOINT_PATH, "cifar10_%i" % latent_dim),
accelerator="auto",
devices=1,
max_epochs=500,
callbacks=[
ModelCheckpoint(save_weights_only=True),
GenerateCallback(get_train_images(8), every_n_epochs=10),
LearningRateMonitor("epoch"),
],
)
trainer.logger._log_graph = True # If True, we plot the computation graph in tensorboard
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "cifar10_%i.ckpt" % latent_dim)
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = Autoencoder.load_from_checkpoint(pretrained_filename)
else:
model = Autoencoder(base_channel_size=32, latent_dim=latent_dim)
trainer.fit(model, train_loader, val_loader)
# Test best model on validation and test set
val_result = trainer.test(model, dataloaders=val_loader, verbose=False)
test_result = trainer.test(model, dataloaders=test_loader, verbose=False)
result = {"test": test_result, "val": val_result}
return model, result
Comparing latent dimensionality¶
When training an autoencoder, we need to choose a dimensionality for the latent representation . The higher the latent dimensionality, the better we expect the reconstruction to be. However, the idea of autoencoders is to compress data. Hence, we are also interested in keeping the dimensionality low. To find the best tradeoff, we can train multiple models with different latent dimensionalities. The original input has 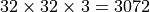 pixels. Keeping this in mind, a
reasonable choice for the latent dimensionality might be between 64 and 384:
pixels. Keeping this in mind, a
reasonable choice for the latent dimensionality might be between 64 and 384:
[11]:
model_dict = {}
for latent_dim in [64, 128, 256, 384]:
model_ld, result_ld = train_cifar(latent_dim)
model_dict[latent_dim] = {"model": model_ld, "result": result_ld}
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/usr/local/lib/python3.9/dist-packages/lightning/pytorch/_graveyard/legacy_import_unpickler.py:23: UserWarning: Redirecting import of pytorch_lightning.utilities.parsing.AttributeDict to lightning.pytorch.utilities.parsing.AttributeDict
warnings.warn(f"Redirecting import of {module}.{name} to {new_module}.{name}")
Lightning automatically upgraded your loaded checkpoint from v0.9.0 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/tutorial9/cifar10_64.ckpt`
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/tutorial9/cifar10_64/lightning_logs
Found pretrained model, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Lightning automatically upgraded your loaded checkpoint from v0.9.0 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/tutorial9/cifar10_128.ckpt`
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/tutorial9/cifar10_128/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
Found pretrained model, loading...
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Lightning automatically upgraded your loaded checkpoint from v0.9.0 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/tutorial9/cifar10_256.ckpt`
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/tutorial9/cifar10_256/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
Found pretrained model, loading...
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Lightning automatically upgraded your loaded checkpoint from v0.9.0 to v2.0.0rc0. To apply the upgrade to your files permanently, run `python -m lightning.pytorch.utilities.upgrade_checkpoint --file saved_models/tutorial9/cifar10_384.ckpt`
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: saved_models/tutorial9/cifar10_384/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
Found pretrained model, loading...
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [4,5]
After training the models, we can plot the reconstruction loss over the latent dimensionality to get an intuition how these two properties are correlated:
[12]:
latent_dims = sorted(k for k in model_dict)
val_scores = [model_dict[k]["result"]["val"][0]["test_loss"] for k in latent_dims]
fig = plt.figure(figsize=(6, 4))
plt.plot(
latent_dims, val_scores, "--", color="#000", marker="*", markeredgecolor="#000", markerfacecolor="y", markersize=16
)
plt.xscale("log")
plt.xticks(latent_dims, labels=latent_dims)
plt.title("Reconstruction error over latent dimensionality", fontsize=14)
plt.xlabel("Latent dimensionality")
plt.ylabel("Reconstruction error")
plt.minorticks_off()
plt.ylim(0, 100)
plt.show()

As we initially expected, the reconstruction loss goes down with increasing latent dimensionality. For our model and setup, the two properties seem to be exponentially (or double exponentially) correlated. To understand what these differences in reconstruction error mean, we can visualize example reconstructions of the four models:
[13]:
def visualize_reconstructions(model, input_imgs):
# Reconstruct images
model.eval()
with torch.no_grad():
reconst_imgs = model(input_imgs.to(model.device))
reconst_imgs = reconst_imgs.cpu()
# Plotting
imgs = torch.stack([input_imgs, reconst_imgs], dim=1).flatten(0, 1)
grid = torchvision.utils.make_grid(imgs, nrow=4, normalize=True, range=(-1, 1))
grid = grid.permute(1, 2, 0)
plt.figure(figsize=(7, 4.5))
plt.title("Reconstructed from %i latents" % (model.hparams.latent_dim))
plt.imshow(grid)
plt.axis("off")
plt.show()
[14]:
input_imgs = get_train_images(4)
for latent_dim in model_dict:
visualize_reconstructions(model_dict[latent_dim]["model"], input_imgs)




Clearly, the smallest latent dimensionality can only save information about the rough shape and color of the object, but the reconstructed image is extremely blurry and it is hard to recognize the original object in the reconstruction. With 128 features, we can recognize some shapes again although the picture remains blurry. The models with the highest two dimensionalities reconstruct the images quite well. The difference between 256 and 384 is marginal at first sight but can be noticed when comparing, for instance, the backgrounds of the first image (the 384 features model more of the pattern than 256).
Out-of-distribution images¶
Before continuing with the applications of autoencoder, we can actually explore some limitations of our autoencoder. For example, what happens if we try to reconstruct an image that is clearly out of the distribution of our dataset? We expect the decoder to have learned some common patterns in the dataset, and thus might in particular fail to reconstruct images that do not follow these patterns.
The first experiment we can try is to reconstruct noise. We, therefore, create two images whose pixels are randomly sampled from a uniform distribution over pixel values, and visualize the reconstruction of the model (feel free to test different latent dimensionalities):
[15]:
rand_imgs = torch.rand(2, 3, 32, 32) * 2 - 1
visualize_reconstructions(model_dict[256]["model"], rand_imgs)

The reconstruction of the noise is quite poor, and seems to introduce some rough patterns. As the input does not follow the patterns of the CIFAR dataset, the model has issues reconstructing it accurately.
We can also check how well the model can reconstruct other manually-coded patterns:
[16]:
plain_imgs = torch.zeros(4, 3, 32, 32)
# Single color channel
plain_imgs[1, 0] = 1
# Checkboard pattern
plain_imgs[2, :, :16, :16] = 1
plain_imgs[2, :, 16:, 16:] = -1
# Color progression
xx, yy = torch.meshgrid(torch.linspace(-1, 1, 32), torch.linspace(-1, 1, 32))
plain_imgs[3, 0, :, :] = xx
plain_imgs[3, 1, :, :] = yy
visualize_reconstructions(model_dict[256]["model"], plain_imgs)
/usr/local/lib/python3.9/dist-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3190.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]

The plain, constant images are reconstructed relatively good although the single color channel contains some noticeable noise. The hard borders of the checkboard pattern are not as sharp as intended, as well as the color progression, both because such patterns never occur in the real-world pictures of CIFAR.
In general, autoencoders tend to fail reconstructing high-frequent noise (i.e. sudden, big changes across few pixels) due to the choice of MSE as loss function (see our previous discussion about loss functions in autoencoders). Small misalignments in the decoder can lead to huge losses so that the model settles for the expected value/mean in these regions. For low-frequent noise, a misalignment of a few pixels does not result in a big difference to the original image. However, the larger the latent dimensionality becomes, the more of this high-frequent noise can be accurately reconstructed.
Generating new images¶
Variational autoencoders are a generative version of the autoencoders because we regularize the latent space to follow a Gaussian distribution. However, in vanilla autoencoders, we do not have any restrictions on the latent vector. So what happens if we would actually input a randomly sampled latent vector into the decoder? Let’s find it out below:
[17]:
model = model_dict[256]["model"]
latent_vectors = torch.randn(8, model.hparams.latent_dim, device=model.device)
with torch.no_grad():
imgs = model.decoder(latent_vectors)
imgs = imgs.cpu()
grid = torchvision.utils.make_grid(imgs, nrow=4, normalize=True, range=(-1, 1), pad_value=0.5)
grid = grid.permute(1, 2, 0)
plt.figure(figsize=(8, 5))
plt.imshow(grid)
plt.axis("off")
plt.show()

As we can see, the generated images more look like art than realistic images. As the autoencoder was allowed to structure the latent space in whichever way it suits the reconstruction best, there is no incentive to map every possible latent vector to realistic images. Furthermore, the distribution in latent space is unknown to us and doesn’t necessarily follow a multivariate normal distribution. Thus, we can conclude that vanilla autoencoders are indeed not generative.
Finding visually similar images¶
One application of autoencoders is to build an image-based search engine to retrieve visually similar images. This can be done by representing all images as their latent dimensionality, and find the closest 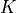 images in this domain. The first step to such a search engine is to encode all images into . In the following, we will use the training set as a search corpus, and the test set as queries to the system.
images in this domain. The first step to such a search engine is to encode all images into . In the following, we will use the training set as a search corpus, and the test set as queries to the system.
(Warning: the following cells can be computationally heavy for a weak CPU-only system. If you do not have a strong computer and are not on Google Colab, you might want to skip the execution of the following cells and rely on the results shown in the filled notebook)
[18]:
# We use the following model throughout this section.
# If you want to try a different latent dimensionality, change it here!
model = model_dict[128]["model"]
[19]:
def embed_imgs(model, data_loader):
# Encode all images in the data_laoder using model, and return both images and encodings
img_list, embed_list = [], []
model.eval()
for imgs, _ in tqdm(data_loader, desc="Encoding images", leave=False):
with torch.no_grad():
z = model.encoder(imgs.to(model.device))
img_list.append(imgs)
embed_list.append(z)
return (torch.cat(img_list, dim=0), torch.cat(embed_list, dim=0))
train_img_embeds = embed_imgs(model, train_loader)
test_img_embeds = embed_imgs(model, test_loader)
After encoding all images, we just need to write a function that finds the closest images and returns (or plots) those:
[20]:
def find_similar_images(query_img, query_z, key_embeds, K=8):
# Find closest K images. We use the euclidean distance here but other like cosine distance can also be used.
dist = torch.cdist(query_z[None, :], key_embeds[1], p=2)
dist = dist.squeeze(dim=0)
dist, indices = torch.sort(dist)
# Plot K closest images
imgs_to_display = torch.cat([query_img[None], key_embeds[0][indices[:K]]], dim=0)
grid = torchvision.utils.make_grid(imgs_to_display, nrow=K + 1, normalize=True, range=(-1, 1))
grid = grid.permute(1, 2, 0)
plt.figure(figsize=(12, 3))
plt.imshow(grid)
plt.axis("off")
plt.show()
[21]:
# Plot the closest images for the first N test images as example
for i in range(8):
find_similar_images(test_img_embeds[0][i], test_img_embeds[1][i], key_embeds=train_img_embeds)








Based on our autoencoder, we see that we are able to retrieve many similar images to the test input. In particular, in row 4, we can spot that some test images might not be that different from the training set as we thought (same poster, just different scaling/color scaling). We also see that although we haven’t given the model any labels, it can cluster different classes in different parts of the latent space (airplane + ship, animals, etc.). This is why autoencoders can also be used as a pre-training strategy for deep networks, especially when we have a large set of unlabeled images (often the case). However, it should be noted that the background still plays a big role in autoencoders while it doesn’t for classification. Hence, we don’t get “perfect” clusters and need to finetune such models for classification.
Tensorboard clustering¶
Another way of exploring the similarity of images in the latent space is by dimensionality-reduction methods like PCA or T-SNE. Luckily, Tensorboard provides a nice interface for this and we can make use of it in the following:
[22]:
# We use the following model throughout this section.
# If you want to try a different latent dimensionality, change it here!
model = model_dict[128]["model"]
[23]:
# Create a summary writer
writer = SummaryWriter("tensorboard/")
The function add_embedding allows us to add high-dimensional feature vectors to TensorBoard on which we can perform clustering. What we have to provide in the function are the feature vectors, additional metadata such as the labels, and the original images so that we can identify a specific image in the clustering.
[24]:
# In case you obtain the following error in the next cell, execute the import statements and last line in this cell
# AttributeError: module 'tensorflow._api.v2.io.gfile' has no attribute 'get_filesystem'
# import tensorflow as tf
# import tensorboard as tb
# tf.io.gfile = tb.compat.tensorflow_stub.io.gfile
[25]:
# Note: the embedding projector in tensorboard is computationally heavy.
# Reduce the image amount below if your computer struggles with visualizing all 10k points
NUM_IMGS = len(test_set)
writer.add_embedding(
test_img_embeds[1][:NUM_IMGS], # Encodings per image
metadata=[test_set[i][1] for i in range(NUM_IMGS)], # Adding the labels per image to the plot
label_img=(test_img_embeds[0][:NUM_IMGS] + 1) / 2.0,
) # Adding the original images to the plot
Finally, we can run tensorboard to explore similarities among images:
[26]:
# Uncomment the next line to start the tensorboard
%tensorboard --logdir tensorboard/
You should be able to see something similar as in the following image. In case the projector stays empty, try to start the TensorBoard outside of the Jupyter notebook.

Overall, we can see that the model indeed clustered images together that are visually similar. Especially the background color seems to be a crucial factor in the encoding. This correlates to the chosen loss function, here Mean Squared Error on pixel-level because the background is responsible for more than half of the pixels in an average image. Hence, the model learns to focus on it. Nevertheless, we can see that the encodings also separate a couple of classes in the latent space although it hasn’t seen any labels. This shows again that autoencoding can also be used as a “pre-training”/transfer learning task before classification.
[27]:
# Closing the summary writer
writer.close()
Conclusion¶
In this tutorial, we have implemented our own autoencoder on small RGB images and explored various properties of the model. In contrast to variational autoencoders, vanilla AEs are not generative and can work on MSE loss functions. This makes them often easier to train. Both versions of AE can be used for dimensionality reduction, as we have seen for finding visually similar images beyond pixel distances. Despite autoencoders gaining less interest in the research community due to their more “theoretically” challenging counterpart of VAEs, autoencoders still find usage in a lot of applications like denoising and compression. Hence, AEs are an essential tool that every Deep Learning engineer/researcher should be familiar with.
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Slack!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

