Introduction to Pytorch Lightning¶
Author: PL team
License: CC BY-SA
Generated: 2023-01-05T12:09:29.379466
In this notebook, we’ll go over the basics of lightning by preparing models to train on the MNIST Handwritten Digits dataset.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Slack
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "torchmetrics>=0.7, <0.12" "seaborn" "ipython[notebook]>=8.0.0, <8.9.0" "pytorch-lightning>=1.4, <1.9" "torchmetrics >=0.11.0" "setuptools==65.6.3" "pandas" "torchvision" "torch>=1.8.1, <1.14.0"
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[2]:
import os
import pandas as pd
import seaborn as sn
import torch
from IPython.core.display import display
from pytorch_lightning import LightningModule, Trainer
from pytorch_lightning.callbacks.progress import TQDMProgressBar
from pytorch_lightning.loggers import CSVLogger
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchmetrics import Accuracy
from torchvision import transforms
from torchvision.datasets import MNIST
PATH_DATASETS = os.environ.get("PATH_DATASETS", ".")
BATCH_SIZE = 256 if torch.cuda.is_available() else 64
/tmp/ipykernel_3064/1920170836.py:6: DeprecationWarning: Importing display from IPython.core.display is deprecated since IPython 7.14, please import from IPython display
from IPython.core.display import display
Simplest example¶
Here’s the simplest most minimal example with just a training loop (no validation, no testing).
Keep in Mind - A LightningModule is a PyTorch nn.Module - it just has a few more helpful features.
[3]:
class MNISTModel(LightningModule):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_nb):
x, y = batch
loss = F.cross_entropy(self(x), y)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.02)
By using the Trainer you automatically get: 1. Tensorboard logging 2. Model checkpointing 3. Training and validation loop 4. early-stopping
[4]:
# Init our model
mnist_model = MNISTModel()
# Init DataLoader from MNIST Dataset
train_ds = MNIST(PATH_DATASETS, train=True, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE)
# Initialize a trainer
trainer = Trainer(
accelerator="auto",
devices=1 if torch.cuda.is_available() else None, # limiting got iPython runs
max_epochs=3,
callbacks=[TQDMProgressBar(refresh_rate=20)],
)
# Train the model ⚡
trainer.fit(mnist_model, train_loader)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to /__w/6/s/.datasets/MNIST/raw/train-images-idx3-ubyte.gz
Extracting /__w/6/s/.datasets/MNIST/raw/train-images-idx3-ubyte.gz to /__w/6/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to /__w/6/s/.datasets/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting /__w/6/s/.datasets/MNIST/raw/train-labels-idx1-ubyte.gz to /__w/6/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to /__w/6/s/.datasets/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting /__w/6/s/.datasets/MNIST/raw/t10k-images-idx3-ubyte.gz to /__w/6/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to /__w/6/s/.datasets/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting /__w/6/s/.datasets/MNIST/raw/t10k-labels-idx1-ubyte.gz to /__w/6/s/.datasets/MNIST/raw
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: /__w/6/s/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
--------------------------------
0 | l1 | Linear | 7.9 K
--------------------------------
7.9 K Trainable params
0 Non-trainable params
7.9 K Total params
0.031 Total estimated model params size (MB)
/usr/local/lib/python3.9/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:224: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 64 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
`Trainer.fit` stopped: `max_epochs=3` reached.
A more complete MNIST Lightning Module Example¶
That wasn’t so hard was it?
Now that we’ve got our feet wet, let’s dive in a bit deeper and write a more complete LightningModule for MNIST…
This time, we’ll bake in all the dataset specific pieces directly in the LightningModule. This way, we can avoid writing extra code at the beginning of our script every time we want to run it.
Note what the following built-in functions are doing:¶
-
This is where we can download the dataset. We point to our desired dataset and ask torchvision’s
MNISTdataset class to download if the dataset isn’t found there.Note we do not make any state assignments in this function (i.e.
self.something = ...)
setup(stage) ⚙️
Loads in data from file and prepares PyTorch tensor datasets for each split (train, val, test).
Setup expects a ‘stage’ arg which is used to separate logic for ‘fit’ and ‘test’.
If you don’t mind loading all your datasets at once, you can set up a condition to allow for both ‘fit’ related setup and ‘test’ related setup to run whenever
Noneis passed tostage(or ignore it altogether and exclude any conditionals).Note this runs across all GPUs and it is safe to make state assignments here
-
train_dataloader(),val_dataloader(), andtest_dataloader()all return PyTorchDataLoaderinstances that are created by wrapping their respective datasets that we prepared insetup()
[5]:
class LitMNIST(LightningModule):
def __init__(self, data_dir=PATH_DATASETS, hidden_size=64, learning_rate=2e-4):
super().__init__()
# Set our init args as class attributes
self.data_dir = data_dir
self.hidden_size = hidden_size
self.learning_rate = learning_rate
# Hardcode some dataset specific attributes
self.num_classes = 10
self.dims = (1, 28, 28)
channels, width, height = self.dims
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
# Define PyTorch model
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(channels * width * height, hidden_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(hidden_size, self.num_classes),
)
self.val_accuracy = Accuracy(task="multiclass", num_classes=10)
self.test_accuracy = Accuracy(task="multiclass", num_classes=10)
def forward(self, x):
x = self.model(x)
return F.log_softmax(x, dim=1)
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
self.val_accuracy.update(preds, y)
# Calling self.log will surface up scalars for you in TensorBoard
self.log("val_loss", loss, prog_bar=True)
self.log("val_acc", self.val_accuracy, prog_bar=True)
def test_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
self.test_accuracy.update(preds, y)
# Calling self.log will surface up scalars for you in TensorBoard
self.log("test_loss", loss, prog_bar=True)
self.log("test_acc", self.test_accuracy, prog_bar=True)
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
####################
# DATA RELATED HOOKS
####################
def prepare_data(self):
# download
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# Assign train/val datasets for use in dataloaders
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset for use in dataloader(s)
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=BATCH_SIZE)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=BATCH_SIZE)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=BATCH_SIZE)
[6]:
model = LitMNIST()
trainer = Trainer(
accelerator="auto",
devices=1 if torch.cuda.is_available() else None, # limiting got iPython runs
max_epochs=3,
callbacks=[TQDMProgressBar(refresh_rate=20)],
logger=CSVLogger(save_dir="logs/"),
)
trainer.fit(model)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: logs/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
-----------------------------------------------------
0 | model | Sequential | 55.1 K
1 | val_accuracy | MulticlassAccuracy | 0
2 | test_accuracy | MulticlassAccuracy | 0
-----------------------------------------------------
55.1 K Trainable params
0 Non-trainable params
55.1 K Total params
0.220 Total estimated model params size (MB)
/usr/local/lib/python3.9/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:224: PossibleUserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 64 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
`Trainer.fit` stopped: `max_epochs=3` reached.
Testing¶
To test a model, call trainer.test(model).
Or, if you’ve just trained a model, you can just call trainer.test() and Lightning will automatically test using the best saved checkpoint (conditioned on val_loss).
[7]:
trainer.test()
/usr/local/lib/python3.9/dist-packages/pytorch_lightning/trainer/connectors/checkpoint_connector.py:134: UserWarning: `.test(ckpt_path=None)` was called without a model. The best model of the previous `fit` call will be used. You can pass `.test(ckpt_path='best')` to use the best model or `.test(ckpt_path='last')` to use the last model. If you pass a value, this warning will be silenced.
rank_zero_warn(
Restoring states from the checkpoint path at logs/lightning_logs/version_0/checkpoints/epoch=2-step=645.ckpt
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Loaded model weights from checkpoint at logs/lightning_logs/version_0/checkpoints/epoch=2-step=645.ckpt
/usr/local/lib/python3.9/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:224: PossibleUserWarning: The dataloader, test_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 64 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test_acc │ 0.9228000044822693 │ │ test_loss │ 0.2596317529678345 │ └───────────────────────────┴───────────────────────────┘
[7]:
[{'test_loss': 0.2596317529678345, 'test_acc': 0.9228000044822693}]
Bonus Tip¶
You can keep calling trainer.fit(model) as many times as you’d like to continue training
[8]:
trainer.fit(model)
/usr/local/lib/python3.9/dist-packages/pytorch_lightning/callbacks/model_checkpoint.py:604: UserWarning: Checkpoint directory logs/lightning_logs/version_0/checkpoints exists and is not empty.
rank_zero_warn(f"Checkpoint directory {dirpath} exists and is not empty.")
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params
-----------------------------------------------------
0 | model | Sequential | 55.1 K
1 | val_accuracy | MulticlassAccuracy | 0
2 | test_accuracy | MulticlassAccuracy | 0
-----------------------------------------------------
55.1 K Trainable params
0 Non-trainable params
55.1 K Total params
0.220 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=3` reached.
In Colab, you can use the TensorBoard magic function to view the logs that Lightning has created for you!
[9]:
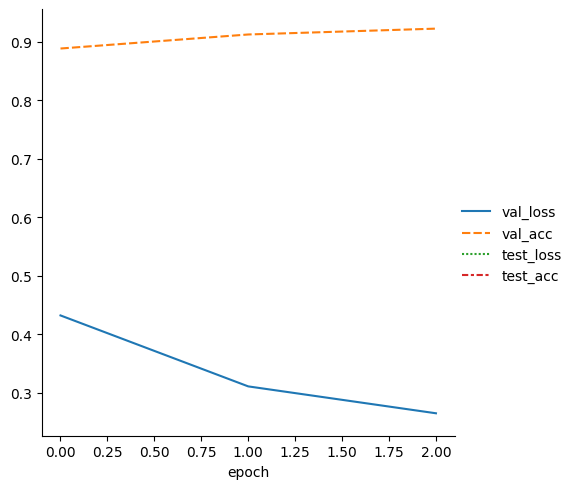
metrics = pd.read_csv(f"{trainer.logger.log_dir}/metrics.csv")
del metrics["step"]
metrics.set_index("epoch", inplace=True)
display(metrics.dropna(axis=1, how="all").head())
sn.relplot(data=metrics, kind="line")
| val_loss | val_acc | test_loss | test_acc | |
|---|---|---|---|---|
| epoch | ||||
| 0 | 0.432111 | 0.8884 | NaN | NaN |
| 1 | 0.310814 | 0.9124 | NaN | NaN |
| 2 | 0.264833 | 0.9224 | NaN | NaN |
| 2 | NaN | NaN | 0.259632 | 0.9228 |
[9]:
<seaborn.axisgrid.FacetGrid at 0x7ff9b037ee20>
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Slack!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

