Tutorial 10: Autoregressive Image Modeling¶
Author: Phillip Lippe
License: CC BY-SA
Generated: 2022-05-03T02:43:16.674251
In this tutorial, we implement an autoregressive likelihood model for the task of image modeling. Autoregressive models are naturally strong generative models that constitute one of the current state-of-the-art architectures on likelihood-based image modeling, and are also the basis for large language generation models such as GPT3. We will focus on the PixelCNN architecture in this tutorial, and apply it to MNIST modeling. This notebook is part of a lecture series on Deep Learning at the University of Amsterdam. The full list of tutorials can be found at https://uvadlc-notebooks.rtfd.io.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Slack
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "ipython[notebook]" "torchmetrics>=0.7" "setuptools==59.5.0" "matplotlib" "seaborn" "torchvision" "pytorch-lightning>=1.4" "torch>=1.8"
Similar to the language generation you have seen in assignment 2, autoregressive models work on images by modeling the likelihood of a pixel given all previous ones. For instance, in the picture below, we model the pixel 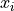 as a conditional probability distribution based on all previous (here blue) pixels (figure credit - Aaron van den Oord et al. ):
as a conditional probability distribution based on all previous (here blue) pixels (figure credit - Aaron van den Oord et al. ):

Generally, autoregressive model over high-dimensional data 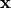 factor the joint distribution as the following product of conditionals:
factor the joint distribution as the following product of conditionals:
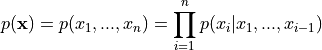
Learning these conditionals is often much simpler than learning the joint distribution 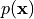 all together. However, disadvantages of autoregressive models include slow sampling, especially for large images, as we need height-times-width forward passes through the model. In addition, for some applications, we require a latent space as modeled in VAEs and Normalizing Flows. For instance, in autoregressive models, we cannot interpolate between two images because of the lack of a
latent representation. We will explore and discuss these benefits and drawbacks alongside with our implementation.
all together. However, disadvantages of autoregressive models include slow sampling, especially for large images, as we need height-times-width forward passes through the model. In addition, for some applications, we require a latent space as modeled in VAEs and Normalizing Flows. For instance, in autoregressive models, we cannot interpolate between two images because of the lack of a
latent representation. We will explore and discuss these benefits and drawbacks alongside with our implementation.
Our implementation will focus on the PixelCNN [2] model which has been discussed in detail in the lecture. Most current SOTA models use PixelCNN as their fundamental architecture, and various additions have been proposed to improve the performance (e.g. PixelCNN++ and PixelSNAIL). Hence, implementing PixelCNN is a good starting point for our short tutorial.
First of all, we need to import our standard libraries. Similarly as in the last couple of tutorials, we will use PyTorch Lightning here as well.
[2]:
import math
import os
import urllib.request
from urllib.error import HTTPError
# Imports for plotting
import matplotlib.pyplot as plt
import numpy as np
import pytorch_lightning as pl
import seaborn as sns
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
import torchvision
from IPython.display import set_matplotlib_formats
from matplotlib.colors import to_rgb
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
from torch import Tensor
from torchvision import transforms
from torchvision.datasets import MNIST
from tqdm.notebook import tqdm
plt.set_cmap("cividis")
%matplotlib inline
set_matplotlib_formats("svg", "pdf") # For export
# Path to the folder where the datasets are/should be downloaded (e.g. MNIST)
DATASET_PATH = os.environ.get("PATH_DATASETS", "data")
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/tutorial12")
# Setting the seed
pl.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.determinstic = True
torch.backends.cudnn.benchmark = False
# Fetching the device that will be used throughout this notebook
device = torch.device("cpu") if not torch.cuda.is_available() else torch.device("cuda:0")
print("Using device", device)
/usr/lib/python3.8/site-packages/apex/pyprof/__init__.py:5: FutureWarning: pyprof will be removed by the end of June, 2022
warnings.warn("pyprof will be removed by the end of June, 2022", FutureWarning)
WARNING:root:Bagua cannot detect bundled NCCL library, Bagua will try to use system NCCL instead. If you encounter any error, please run `import bagua_core; bagua_core.install_deps()` or the `bagua_install_deps.py` script to install bundled libraries.
/tmp/ipykernel_4215/1092408338.py:27: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
set_matplotlib_formats("svg", "pdf") # For export
Global seed set to 42
Using device cuda:0
We again provide a pretrained model, which is downloaded below:
[3]:
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial12/"
# Files to download
pretrained_files = ["PixelCNN.ckpt"]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print("Downloading %s..." % file_url)
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print(
"Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n",
e,
)
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial12/PixelCNN.ckpt...
Similar to the Normalizing Flows in Tutorial 11, we will work on the MNIST dataset and use 8-bits per pixel (values between 0 and 255). The dataset is loaded below:
[4]:
# Convert images from 0-1 to 0-255 (integers). We use the long datatype as we will use the images as labels as well
def discretize(sample):
return (sample * 255).to(torch.long)
# Transformations applied on each image => only make them a tensor
transform = transforms.Compose([transforms.ToTensor(), discretize])
# Loading the training dataset. We need to split it into a training and validation part
train_dataset = MNIST(root=DATASET_PATH, train=True, transform=transform, download=True)
pl.seed_everything(42)
train_set, val_set = torch.utils.data.random_split(train_dataset, [50000, 10000])
# Loading the test set
test_set = MNIST(root=DATASET_PATH, train=False, transform=transform, download=True)
# We define a set of data loaders that we can use for various purposes later.
train_loader = data.DataLoader(train_set, batch_size=128, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = data.DataLoader(val_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
test_loader = data.DataLoader(test_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
/usr/local/lib/python3.8/dist-packages/torchvision/datasets/mnist.py:498: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
Global seed set to 42
A good practice is to always visualize some data examples to get an intuition of the data:
[5]:
def show_imgs(imgs):
num_imgs = imgs.shape[0] if isinstance(imgs, Tensor) else len(imgs)
nrow = min(num_imgs, 4)
ncol = int(math.ceil(num_imgs / nrow))
imgs = torchvision.utils.make_grid(imgs, nrow=nrow, pad_value=128)
imgs = imgs.clamp(min=0, max=255)
np_imgs = imgs.cpu().numpy()
plt.figure(figsize=(1.5 * nrow, 1.5 * ncol))
plt.imshow(np.transpose(np_imgs, (1, 2, 0)), interpolation="nearest")
plt.axis("off")
plt.show()
plt.close()
show_imgs([train_set[i][0] for i in range(8)])

Masked autoregressive convolutions¶
The core module of PixelCNN is its masked convolutions. In contrast to language models, we don’t apply an LSTM on each pixel one-by-one. This would be inefficient because images are grids instead of sequences. Thus, it is better to rely on convolutions that have shown great success in deep CNN classification models.
Nevertheless, we cannot just apply standard convolutions without any changes. Remember that during training of autoregressive models, we want to use teacher forcing which both helps the model training, and significantly reduces the time needed for training. For image modeling, teacher forcing is implemented by using a training image as input to the model, and we want to obtain as output the prediction for each pixel based on only its predecessors. Thus, we need to ensure that the prediction for a specific pixel can only be influenced by its predecessors and not by its own value or any “future” pixels. For this, we apply convolutions with a mask.
Which mask we use depends on the ordering of pixels we decide on, i.e. which is the first pixel we predict, which is the second one, etc. The most commonly used ordering is to denote the upper left pixel as the start pixel, and sort the pixels row by row, as shown in the visualization at the top of the tutorial. Thus, the second pixel is on the right of the first one (first row, second column), and once we reach the end of the row, we start in the second row, first column. If we now want to apply this to our convolutions, we need to ensure that the prediction of pixel 1 is not influenced by its own “true” input, and all pixels on its right and in any lower row. In convolutions, this means that we want to set those entries of the weight matrix to zero that take pixels on the right and below into account. As an example for a 5x5 kernel, see a mask below (figure credit - Aaron van den Oord):

Before looking into the application of masked convolutions in PixelCNN in detail, let’s first implement a module that allows us to apply an arbitrary mask to a convolution:
[6]:
class MaskedConvolution(nn.Module):
def __init__(self, c_in, c_out, mask, **kwargs):
"""Implements a convolution with mask applied on its weights.
Args:
c_in: Number of input channels
c_out: Number of output channels
mask: Tensor of shape [kernel_size_H, kernel_size_W] with 0s where
the convolution should be masked, and 1s otherwise.
kwargs: Additional arguments for the convolution
"""
super().__init__()
# For simplicity: calculate padding automatically
kernel_size = (mask.shape[0], mask.shape[1])
dilation = 1 if "dilation" not in kwargs else kwargs["dilation"]
padding = tuple(dilation * (kernel_size[i] - 1) // 2 for i in range(2))
# Actual convolution
self.conv = nn.Conv2d(c_in, c_out, kernel_size, padding=padding, **kwargs)
# Mask as buffer => it is no parameter but still a tensor of the module
# (must be moved with the devices)
self.register_buffer("mask", mask[None, None])
def forward(self, x):
self.conv.weight.data *= self.mask # Ensures zero's at masked positions
return self.conv(x)
Vertical and horizontal convolution stacks¶
To build our own autoregressive image model, we could simply stack a few masked convolutions on top of each other. This was actually the case for the original PixelCNN model, discussed in the paper Pixel Recurrent Neural Networks, but this leads to a considerable issue. When sequentially applying a couple of masked convolutions, the receptive field of a pixel show to have a “blind spot” on the right upper side, as shown in the figure below (figure credit - Aaron van den Oord et al. ):
![]()
Although a pixel should be able to take into account all other pixels above and left of it, a stack of masked convolutions does not allow us to look to the upper pixels on the right. This is because the features of the pixels above, which we use for convolution, do not contain any information of the pixels on the right of the same row. If they would, we would be “cheating” and actually looking into the future. To overcome this issue, van den Oord et. al [2] proposed to split the convolutions into a vertical and a horizontal stack. The vertical stack looks at all pixels above the current one, while the horizontal takes into account all on the left. While keeping both of them separate, we can actually look at the pixels on the right with the vertical stack without breaking any of our assumptions. The two convolutions are also shown in the figure above.
Let us implement them here as follows:
[7]:
class VerticalStackConvolution(MaskedConvolution):
def __init__(self, c_in, c_out, kernel_size=3, mask_center=False, **kwargs):
# Mask out all pixels below. For efficiency, we could also reduce the kernel
# size in height, but for simplicity, we stick with masking here.
mask = torch.ones(kernel_size, kernel_size)
mask[kernel_size // 2 + 1 :, :] = 0
# For the very first convolution, we will also mask the center row
if mask_center:
mask[kernel_size // 2, :] = 0
super().__init__(c_in, c_out, mask, **kwargs)
class HorizontalStackConvolution(MaskedConvolution):
def __init__(self, c_in, c_out, kernel_size=3, mask_center=False, **kwargs):
# Mask out all pixels on the left. Note that our kernel has a size of 1
# in height because we only look at the pixel in the same row.
mask = torch.ones(1, kernel_size)
mask[0, kernel_size // 2 + 1 :] = 0
# For the very first convolution, we will also mask the center pixel
if mask_center:
mask[0, kernel_size // 2] = 0
super().__init__(c_in, c_out, mask, **kwargs)
Note that we have an input argument called mask_center. Remember that the input to the model is the actual input image. Hence, the very first convolution we apply cannot use the center pixel as input, but must be masked. All consecutive convolutions, however, should use the center pixel as we otherwise lose the features of the previous layer. Hence, the input argument mask_center is True for the very first convolutions, and False for all others.
Visualizing the receptive field¶
To validate our implementation of masked convolutions, we can visualize the receptive field we obtain with such convolutions. We should see that with increasing number of convolutional layers, the receptive field grows in both vertical and horizontal direction, without the issue of a blind spot. The receptive field can be empirically measured by backpropagating an arbitrary loss for the output features of a speicifc pixel with respect to the input. We implement this idea below, and visualize the receptive field below.
[8]:
inp_img = torch.zeros(1, 1, 11, 11)
inp_img.requires_grad_()
def show_center_recep_field(img, out):
"""Calculates the gradients of the input with respect to the output center pixel, and visualizes the overall
receptive field.
Args:
img: Input image for which we want to calculate the receptive field on.
out: Output features/loss which is used for backpropagation, and should be
the output of the network/computation graph.
"""
# Determine gradients
loss = out[0, :, img.shape[2] // 2, img.shape[3] // 2].sum() # L1 loss for simplicity
# Retain graph as we want to stack multiple layers and show the receptive field of all of them
loss.backward(retain_graph=True)
img_grads = img.grad.abs()
img.grad.fill_(0) # Reset grads
# Plot receptive field
img = img_grads.squeeze().cpu().numpy()
fig, ax = plt.subplots(1, 2)
_ = ax[0].imshow(img)
ax[1].imshow(img > 0)
# Mark the center pixel in red if it doesn't have any gradients (should be
# the case for standard autoregressive models)
show_center = img[img.shape[0] // 2, img.shape[1] // 2] == 0
if show_center:
center_pixel = np.zeros(img.shape + (4,))
center_pixel[center_pixel.shape[0] // 2, center_pixel.shape[1] // 2, :] = np.array([1.0, 0.0, 0.0, 1.0])
for i in range(2):
ax[i].axis("off")
if show_center:
ax[i].imshow(center_pixel)
ax[0].set_title("Weighted receptive field")
ax[1].set_title("Binary receptive field")
plt.show()
plt.close()
show_center_recep_field(inp_img, inp_img)

Let’s first visualize the receptive field of a horizontal convolution without the center pixel. We use a small, arbitrary input image (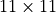 pixels), and calculate the loss for the center pixel. For simplicity, we initialize all weights with 1 and the bias with 0, and use a single channel. This is sufficient for our visualization purposes.
pixels), and calculate the loss for the center pixel. For simplicity, we initialize all weights with 1 and the bias with 0, and use a single channel. This is sufficient for our visualization purposes.
[9]:
horiz_conv = HorizontalStackConvolution(c_in=1, c_out=1, kernel_size=3, mask_center=True)
horiz_conv.conv.weight.data.fill_(1)
horiz_conv.conv.bias.data.fill_(0)
horiz_img = horiz_conv(inp_img)
show_center_recep_field(inp_img, horiz_img)

The receptive field is shown in yellow, the center pixel in red, and all other pixels outside of the receptive field are dark blue. As expected, the receptive field of a single horizontal convolution with the center pixel masked and a 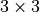 kernel is only the pixel on the left. If we use a larger kernel size, more pixels would be taken into account on the left.
kernel is only the pixel on the left. If we use a larger kernel size, more pixels would be taken into account on the left.
Next, let’s take a look at the vertical convolution:
[10]:
vert_conv = VerticalStackConvolution(c_in=1, c_out=1, kernel_size=3, mask_center=True)
vert_conv.conv.weight.data.fill_(1)
vert_conv.conv.bias.data.fill_(0)
vert_img = vert_conv(inp_img)
show_center_recep_field(inp_img, vert_img)

The vertical convolution takes all pixels above into account. Combining these two, we get the L-shaped receptive field of the original masked convolution:
[11]:
horiz_img = vert_img + horiz_img
show_center_recep_field(inp_img, horiz_img)

If we stack multiple horizontal and vertical convolutions, we need to take two aspects into account:
The center should not be masked anymore for the following convolutions as the features at the pixel’s position are already independent of its actual value. If it is hard to imagine why we can do this, just change the value below to
mask_center=Trueand see what happens.The vertical convolution is not allowed to work on features from the horizontal convolution. In the feature map of the horizontal convolutions, a pixel contains information about all of the “true” pixels on the left. If we apply a vertical convolution which also uses features from the right, we effectively expand our receptive field to the true input which we want to prevent. Thus, the feature maps can only be merged for the horizontal convolution.
Using this, we can stack the convolutions in the following way. We have two feature streams: one for the vertical stack, and one for the horizontal stack. The horizontal convolutions can operate on the joint features of the previous horizontals and vertical convolutions, while the vertical stack only takes its own previous features as input. For a quick implementation, we can therefore sum the horizontal and vertical output features at each layer, and use those as final output features to
calculate the loss on. An implementation of 4 consecutive layers is shown below. Note that we reuse the features from the other convolutions with mask_center=True from above.
[12]:
# Initialize convolutions with equal weight to all input pixels
horiz_conv = HorizontalStackConvolution(c_in=1, c_out=1, kernel_size=3, mask_center=False)
horiz_conv.conv.weight.data.fill_(1)
horiz_conv.conv.bias.data.fill_(0)
vert_conv = VerticalStackConvolution(c_in=1, c_out=1, kernel_size=3, mask_center=False)
vert_conv.conv.weight.data.fill_(1)
vert_conv.conv.bias.data.fill_(0)
# We reuse our convolutions for the 4 layers here. Note that in a standard network,
# we don't do that, and instead learn 4 separate convolution. As this cell is only for
# visualization purposes, we reuse the convolutions for all layers.
for l_idx in range(4):
vert_img = vert_conv(vert_img)
horiz_img = horiz_conv(horiz_img) + vert_img
print("Layer %i" % (l_idx + 2))
show_center_recep_field(inp_img, horiz_img)
Layer 2

Layer 3

Layer 4

Layer 5

The receptive field above it visualized for the horizontal stack, which includes the features of the vertical convolutions. It grows over layers without any blind spot as we had before. The difference between “weighted” and “binary” receptive field is that for the latter, we check whether there are any gradients flowing back to this pixel. This indicates that the center pixel indeed can use information from this pixel. Nevertheless, due to the convolution weights, some pixels have a stronger effect on the prediction than others. This is visualized in the weighted receptive field by plotting the gradient magnitude for each pixel instead of a binary yes/no.
Another receptive field we can check is the one for the vertical stack as the one above is for the horizontal stack. Let’s visualize it below:
[13]:
show_center_recep_field(inp_img, vert_img)

As we have discussed before, the vertical stack only looks at pixels above the one we want to predict. Hence, we can validate that our implementation works as we initially expected it to. As a final step, let’s clean up the computation graph we still had kept in memory for the visualization of the receptive field:
[14]:
del inp_img, horiz_conv, vert_conv
Gated PixelCNN¶
In the next step, we will use the masked convolutions to build a full autoregressive model, called Gated PixelCNN. The difference between the original PixelCNN and Gated PixelCNN is the use of separate horizontal and vertical stacks. However, in literature, you often see that people refer to the Gated PixelCNN simply as “PixelCNN”. Hence, in the following, if we say “PixelCNN”, we usually mean the gated version. What “Gated” refers to in the model name is explained next.
Gated Convolutions¶
For visualizing the receptive field, we assumed a very simplified stack of vertical and horizontal convolutions. Obviously, there are more sophisticated ways of doing it, and PixelCNN uses gated convolutions for this. Specifically, the Gated Convolution block in PixelCNN looks as follows (figure credit - Aaron van den Oord et al. ):
![]()
The left path is the vertical stack (the 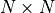 convolution is masked correspondingly), and the right path is the horizontal stack. Gated convolutions are implemented by having a twice as large output channel size, and combine them by a element-wise multiplication of
convolution is masked correspondingly), and the right path is the horizontal stack. Gated convolutions are implemented by having a twice as large output channel size, and combine them by a element-wise multiplication of  and a sigmoid. For a linear layer, we can express a gated activation unit as follows:
and a sigmoid. For a linear layer, we can express a gated activation unit as follows:
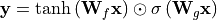
For simplicity, biases have been neglected and the linear layer split into two part, 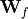 and
and 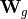 . This concept resembles the input and modulation gate in an LSTM, and has been used in many other architectures as well. The main motivation behind this gated activation is that it might allow to model more complex interactions and simplifies learning. But as in any other architecture, this is mostly a design choice and can be considered a hyperparameters.
. This concept resembles the input and modulation gate in an LSTM, and has been used in many other architectures as well. The main motivation behind this gated activation is that it might allow to model more complex interactions and simplifies learning. But as in any other architecture, this is mostly a design choice and can be considered a hyperparameters.
Besides the gated convolutions, we also see that the horizontal stack uses a residual connection while the vertical stack does not. This is because we use the output of the horizontal stack for prediction. Each convolution in the vertical stack also receives a strong gradient signal as it is only two  convolutions away from the residual connection, and does not require another residual connection to all its earleri layers.
convolutions away from the residual connection, and does not require another residual connection to all its earleri layers.
The implementation in PyTorch is fairly straight forward for this block, because the visualization above gives us a computation graph to follow:
[15]:
class GatedMaskedConv(nn.Module):
def __init__(self, c_in, **kwargs):
"""Gated Convolution block implemented the computation graph shown above."""
super().__init__()
self.conv_vert = VerticalStackConvolution(c_in, c_out=2 * c_in, **kwargs)
self.conv_horiz = HorizontalStackConvolution(c_in, c_out=2 * c_in, **kwargs)
self.conv_vert_to_horiz = nn.Conv2d(2 * c_in, 2 * c_in, kernel_size=1, padding=0)
self.conv_horiz_1x1 = nn.Conv2d(c_in, c_in, kernel_size=1, padding=0)
def forward(self, v_stack, h_stack):
# Vertical stack (left)
v_stack_feat = self.conv_vert(v_stack)
v_val, v_gate = v_stack_feat.chunk(2, dim=1)
v_stack_out = torch.tanh(v_val) * torch.sigmoid(v_gate)
# Horizontal stack (right)
h_stack_feat = self.conv_horiz(h_stack)
h_stack_feat = h_stack_feat + self.conv_vert_to_horiz(v_stack_feat)
h_val, h_gate = h_stack_feat.chunk(2, dim=1)
h_stack_feat = torch.tanh(h_val) * torch.sigmoid(h_gate)
h_stack_out = self.conv_horiz_1x1(h_stack_feat)
h_stack_out = h_stack_out + h_stack
return v_stack_out, h_stack_out
Building the model¶
Using the gated convolutions, we can now build our PixelCNN model. The architecture consists of multiple stacked GatedMaskedConv blocks, where we add an additional dilation factor to a few convolutions. This is used to increase the receptive field of the model and allows to take a larger context into accout during generation. As a reminder, dilation on a convolution works looks as follows (figure credit - Vincent Dumoulin and Francesco Visin):
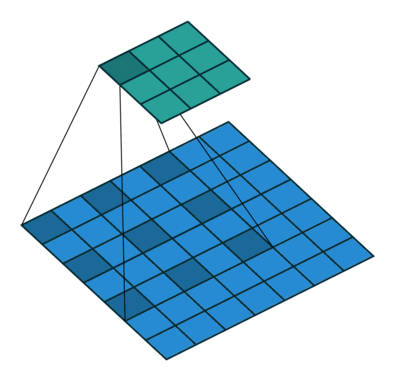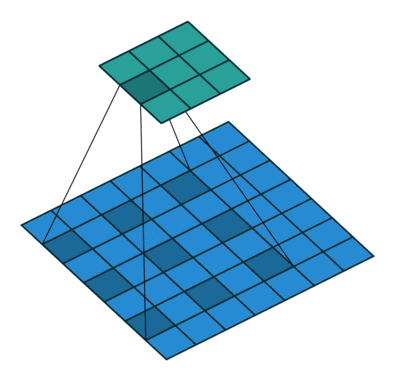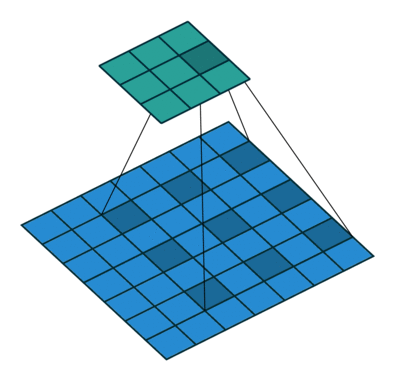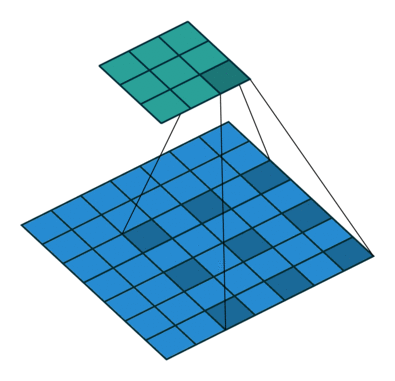
Note that the smaller output size is only because the animation assumes no padding. In our implementation, we will pad the input image correspondingly. Alternatively to dilated convolutions, we could downsample the input and use a encoder-decoder architecture as in PixelCNN++ [3]. This is especially beneficial if we want to build a very deep autoregressive model. Nonetheless, as we seek to train a reasonably small model, dilated convolutions are the more efficient option to use here.
Below, we implement the PixelCNN model as a PyTorch Lightning module. Besides the stack of gated convolutions, we also have the initial horizontal and vertical convolutions which mask the center pixel, and a final convolution which maps the output features to class predictions. To determine the likelihood of a batch of images, we first create our initial features using the masked horizontal and vertical input convolution. Next, we forward the features through the stack of gated
convolutions. Finally, we take the output features of the horizontal stack, and apply the convolution for classification. We use the bits per dimension metric for the likelihood, similarly to Tutorial 11 and assignment 3.
[16]:
class PixelCNN(pl.LightningModule):
def __init__(self, c_in, c_hidden):
super().__init__()
self.save_hyperparameters()
# Initial convolutions skipping the center pixel
self.conv_vstack = VerticalStackConvolution(c_in, c_hidden, mask_center=True)
self.conv_hstack = HorizontalStackConvolution(c_in, c_hidden, mask_center=True)
# Convolution block of PixelCNN. We use dilation instead of downscaling
self.conv_layers = nn.ModuleList(
[
GatedMaskedConv(c_hidden),
GatedMaskedConv(c_hidden, dilation=2),
GatedMaskedConv(c_hidden),
GatedMaskedConv(c_hidden, dilation=4),
GatedMaskedConv(c_hidden),
GatedMaskedConv(c_hidden, dilation=2),
GatedMaskedConv(c_hidden),
]
)
# Output classification convolution (1x1)
self.conv_out = nn.Conv2d(c_hidden, c_in * 256, kernel_size=1, padding=0)
self.example_input_array = train_set[0][0][None]
def forward(self, x):
"""Forward image through model and return logits for each pixel.
Args:
x: Image tensor with integer values between 0 and 255.
"""
# Scale input from 0 to 255 back to -1 to 1
x = (x.float() / 255.0) * 2 - 1
# Initial convolutions
v_stack = self.conv_vstack(x)
h_stack = self.conv_hstack(x)
# Gated Convolutions
for layer in self.conv_layers:
v_stack, h_stack = layer(v_stack, h_stack)
# 1x1 classification convolution
# Apply ELU before 1x1 convolution for non-linearity on residual connection
out = self.conv_out(F.elu(h_stack))
# Output dimensions: [Batch, Classes, Channels, Height, Width]
out = out.reshape(out.shape[0], 256, out.shape[1] // 256, out.shape[2], out.shape[3])
return out
def calc_likelihood(self, x):
# Forward pass with bpd likelihood calculation
pred = self.forward(x)
nll = F.cross_entropy(pred, x, reduction="none")
bpd = nll.mean(dim=[1, 2, 3]) * np.log2(np.exp(1))
return bpd.mean()
@torch.no_grad()
def sample(self, img_shape, img=None):
"""Sampling function for the autoregressive model.
Args:
img_shape: Shape of the image to generate (B,C,H,W)
img (optional): If given, this tensor will be used as
a starting image. The pixels to fill
should be -1 in the input tensor.
"""
# Create empty image
if img is None:
img = torch.zeros(img_shape, dtype=torch.long).to(device) - 1
# Generation loop
for h in tqdm(range(img_shape[2]), leave=False):
for w in range(img_shape[3]):
for c in range(img_shape[1]):
# Skip if not to be filled (-1)
if (img[:, c, h, w] != -1).all().item():
continue
# For efficiency, we only have to input the upper part of the image
# as all other parts will be skipped by the masked convolutions anyways
pred = self.forward(img[:, :, : h + 1, :])
probs = F.softmax(pred[:, :, c, h, w], dim=-1)
img[:, c, h, w] = torch.multinomial(probs, num_samples=1).squeeze(dim=-1)
return img
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.99)
return [optimizer], [scheduler]
def training_step(self, batch, batch_idx):
loss = self.calc_likelihood(batch[0])
self.log("train_bpd", loss)
return loss
def validation_step(self, batch, batch_idx):
loss = self.calc_likelihood(batch[0])
self.log("val_bpd", loss)
def test_step(self, batch, batch_idx):
loss = self.calc_likelihood(batch[0])
self.log("test_bpd", loss)
To sample from the autoregressive model, we need to iterate over all dimensions of the input. We start with an empty image, and fill the pixels one by one, starting from the upper left corner. Note that as for predicting , all pixels below it have no influence on the prediction. Hence, we can cut the image in height without changing the prediction while increasing efficiency. Nevertheless, all the loops in the sampling function already show that it will take us quite some time to
sample. A lot of computation could be reused across loop iterations as those the features on the already predicted pixels will not change over iterations. Nevertheless, this takes quite some effort to implement, and is often not done in implementations because in the end, autoregressive sampling remains sequential and slow. Hence, we settle with the default implementation here.
Before training the model, we can check the full receptive field of the model on an MNIST image of size 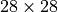 :
:
[17]:
test_model = PixelCNN(c_in=1, c_hidden=64)
inp = torch.zeros(1, 1, 28, 28)
inp.requires_grad_()
out = test_model(inp)
show_center_recep_field(inp, out.squeeze(dim=2))
del inp, out, test_model

The visualization shows that for predicting any pixel, we can take almost half of the image into account. However, keep in mind that this is the “theoretical” receptive field and not necessarily the effective receptive field, which is usually much smaller. For a stronger model, we should therefore try to increase the receptive field even further. Especially, for the pixel on the bottom right, the very last pixel, we would be allowed to take into account the whole image. However, our current receptive field only spans across 1/4 of the image. An encoder-decoder architecture can help with this, but it also shows that we require a much deeper, more complex network in autoregressive models than in VAEs or energy-based models.
Training loop¶
To train the model, we again can rely on PyTorch Lightning and write a function below for loading the pretrained model if it exists. To reduce the computational cost, we have saved the validation and test score in the checkpoint already:
[18]:
def train_model(**kwargs):
# Create a PyTorch Lightning trainer with the generation callback
trainer = pl.Trainer(
default_root_dir=os.path.join(CHECKPOINT_PATH, "PixelCNN"),
gpus=1 if str(device).startswith("cuda") else 0,
max_epochs=150,
callbacks=[
ModelCheckpoint(save_weights_only=True, mode="min", monitor="val_bpd"),
LearningRateMonitor("epoch"),
],
)
result = None
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "PixelCNN.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = PixelCNN.load_from_checkpoint(pretrained_filename)
ckpt = torch.load(pretrained_filename, map_location=device)
result = ckpt.get("result", None)
else:
model = PixelCNN(**kwargs)
trainer.fit(model, train_loader, val_loader)
model = model.to(device)
if result is None:
# Test best model on validation and test set
val_result = trainer.test(model, dataloaders=val_loader, verbose=False)
test_result = trainer.test(model, dataloaders=test_loader, verbose=False)
result = {"test": test_result, "val": val_result}
return model, result
Training the model is time consuming and we recommend using the provided pre-trained model for going through this notebook. However, feel free to play around with the hyperparameter like number of layers etc. if you want to get a feeling for those.
When calling the training function with a pre-trained model, we automatically load it and print its test performance:
[19]:
model, result = train_model(c_in=1, c_hidden=64)
test_res = result["test"][0]
print(
"Test bits per dimension: %4.3fbpd" % (test_res["test_loss"] if "test_loss" in test_res else test_res["test_bpd"])
)
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Found pretrained model, loading...
Test bits per dimension: 0.808bpd
With a test performance of 0.809bpd, the PixelCNN significantly outperforms the normalizing flows we have seen in Tutorial 11. Considering image modeling as an autoregressive problem simplifies the learning process as predicting one pixel given the ground truth of all others is much easier than predicting all pixels at once. In addition, PixelCNN can explicitly predict the pixel values by a discrete softmax while Normalizing Flows have to learn transformations in continuous latent space. These two aspects allow the PixelCNN to achieve a notably better performance.
To fully compare the models, let’s also measure the number of parameters of the PixelCNN:
[20]:
num_params = sum(np.prod(param.shape) for param in model.parameters())
print(f"Number of parameters: {num_params:,}")
Number of parameters: 852,160
Compared to the multi-scale normalizing flows, the PixelCNN has considerably less parameters. Of course, the number of parameters depend on our hyperparameter choices. Nevertheless, in general, it can be said that autoregressive models require considerably less parameters than normalizing flows to reach good performance, based on the reasons stated above. Still, autoregressive models are much slower in sampling than normalizing flows, which limits their possible applications.
Sampling¶
One way of qualitatively analysing generative models is by looking at the actual samples. Let’s therefore use our sampling function to generate a few digits:
[21]:
pl.seed_everything(1)
samples = model.sample(img_shape=(16, 1, 28, 28))
show_imgs(samples.cpu())
Global seed set to 1

Most of the samples can be identified as digits, and overall we achieve a better quality than we had in normalizing flows. This goes along with the lower likelihood we achieved with autoregressive models. Nevertheless, we also see that there is still place for improvement as a considerable amount of samples cannot be identified (for example the first row). Deeper autoregressive models are expected to achieve better quality, as they can take more context into account for generating the pixels.
Note that on Google Colab, you might see different results, specifically with a white line at the top. After some debugging, it seemed that the difference occurs inside the dilated convolution, as it gives different results for different batch sizes. However, it is hard to debug this further as it might be a bug of the installed PyTorch version on Google Colab.
The trained model itself is not restricted to any specific image size. However, what happens if we actually sample a larger image than we had seen in our training dataset? Let’s try below to sample images of size 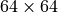 instead of
instead of 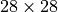 :
:
[22]:
pl.seed_everything(1)
samples = model.sample(img_shape=(8, 1, 64, 64))
show_imgs(samples.cpu())
Global seed set to 1

The larger images show that changing the size of the image during testing confuses the model and generates abstract figures (you can sometimes spot a digit in the upper left corner). In addition, sampling for images of 64x64 pixels take more than a minute on a GPU. Clearly, autoregressive models cannot be scaled to large images without changing the sampling procedure such as with forecasting. Our implementation is also not the most efficient as many computations can be stored and reused throughout the sampling process. Nevertheless, the sampling procedure stays sequential which is inherently slower than parallel generation like done in normalizing flows.
Autocompletion¶
One common application done with autoregressive models is auto-completing an image. As autoregressive models predict pixels one by one, we can set the first 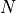 pixels to predefined values and check how the model completes the image. For implementing this, we just need to skip the iterations in the sampling loop that already have a value unequals -1. See above in our PyTorch Lightning module for the specific implementation. In the cell below, we randomly take three images from the training
set, mask about the lower half of the image, and let the model autocomplete it. To see the diversity of samples, we do this 12 times for each image:
pixels to predefined values and check how the model completes the image. For implementing this, we just need to skip the iterations in the sampling loop that already have a value unequals -1. See above in our PyTorch Lightning module for the specific implementation. In the cell below, we randomly take three images from the training
set, mask about the lower half of the image, and let the model autocomplete it. To see the diversity of samples, we do this 12 times for each image:
[23]:
def autocomplete_image(img):
# Remove lower half of the image
img_init = img.clone()
img_init[:, 10:, :] = -1
print("Original image and input image to sampling:")
show_imgs([img, img_init])
# Generate 12 example completions
img_init = img_init.unsqueeze(dim=0).expand(12, -1, -1, -1).to(device)
pl.seed_everything(1)
img_generated = model.sample(img_init.shape, img_init)
print("Autocompletion samples:")
show_imgs(img_generated)
for i in range(1, 4):
img = train_set[i][0]
autocomplete_image(img)
Original image and input image to sampling:

Global seed set to 1
Autocompletion samples:

Original image and input image to sampling:

Global seed set to 1
Autocompletion samples:

Original image and input image to sampling:

Global seed set to 1
Autocompletion samples:

For the first two digits (7 and 6), we see that the 12 samples all result in a shape which resemble the original digit. Nevertheless, there are some style difference in writing the 7, and some deformed sixes in the samples. When autocompleting the 9 below, we see that the model can fit multiple digits to it. We obtain diverse samples from 0, 3, 8 and 9. This shows that despite having no latent space, we can still obtain diverse samples from an autoregressive model.
Visualization of the predictive distribution (softmax)¶
Autoregressive models use a softmax over 256 values to predict the next pixel. This gives the model a large flexibility as the probabilities for each pixel value can be learned independently if necessary. However, the values are actually not independent because the values 32 and 33 are much closer than 32 and 255. In the following, we visualize the softmax distribution that the model predicts to gain insights how it has learned the relationships of close-by pixels.
To do this, we first run the model on a batch of images and store the output softmax distributions:
[24]:
det_loader = data.DataLoader(train_set, batch_size=128, shuffle=False, drop_last=False)
imgs, _ = next(iter(det_loader))
imgs = imgs.to(device)
with torch.no_grad():
out = model(imgs)
out = F.softmax(out, dim=1)
mean_out = out.mean(dim=[0, 2, 3, 4]).cpu().numpy()
out = out.cpu().numpy()
Before diving into the model, let’s visualize the distribution of the pixel values in the whole dataset:
[25]:
sns.set()
plot_args = {"color": to_rgb("C0") + (0.5,), "edgecolor": "C0", "linewidth": 0.5, "width": 1.0}
plt.hist(imgs.view(-1).cpu().numpy(), bins=256, density=True, **plot_args)
plt.yscale("log")
plt.xticks([0, 64, 128, 192, 256])
plt.show()
plt.close()

As we would expect from the seen images, the pixel value 0 (black) is the dominant value, followed by a batch of values between 250 and 255. Note that we use a log scale on the y-axis due to the big imbalance in the dataset. Interestingly, the pixel values 64, 128 and 191 also stand out which is likely due to the quantization used during the creation of the dataset. For RGB images, we would also see two peaks around 0 and 255, but the values in between would be much more frequent than in MNIST (see Figure 1 in the PixelCNN++ for a visualization on CIFAR10).
Next, we can visualize the distribution our model predicts (in average):
[26]:
plt.bar(np.arange(mean_out.shape[0]), mean_out, **plot_args)
plt.yscale("log")
plt.xticks([0, 64, 128, 192, 256])
plt.show()
plt.close()

This distribution is very close to the actual dataset distribution. This is in general a good sign, but we can see a slightly smoother histogram than above.
Finally, to take a closer look at learned value relations, we can visualize the distribution for individual pixel predictions to get a better intuition. For this, we pick 4 random images and pixels, and visualize their distribution below:
[27]:
fig, ax = plt.subplots(2, 2, figsize=(10, 6))
for i in range(4):
ax_sub = ax[i // 2][i % 2]
ax_sub.bar(np.arange(out.shape[1], dtype=np.int32), out[i + 4, :, 0, 14, 14], **plot_args)
ax_sub.set_yscale("log")
ax_sub.set_xticks([0, 64, 128, 192, 256])
plt.show()
plt.close()

Overall we see a very diverse set of distributions, with a usual peak for 0 and close to 1. However, the distributions in the first row show a potentially undesirable behavior. For instance, the value 242 has a 1000x lower likelihood than 243 although they are extremely close and can often not be distinguished. This shows that the model might have not generlized well over pixel values. The better solution to this problem is to use discrete logitics mixtures instead of a softmax distribution. A discrete logistic distribution can be imagined as discretized, binned Gaussians. Using a mixture of discrete logistics instead of a softmax introduces an inductive bias to the model to assign close-by values similar likelihoods. We can visualize a discrete logistic below:
[28]:
mu = Tensor([128])
sigma = Tensor([2.0])
def discrete_logistic(x, mu, sigma):
return torch.sigmoid((x + 0.5 - mu) / sigma) - torch.sigmoid((x - 0.5 - mu) / sigma)
x = torch.arange(256)
p = discrete_logistic(x, mu, sigma)
# Visualization
plt.figure(figsize=(6, 3))
plt.bar(x.numpy(), p.numpy(), **plot_args)
plt.xlim(96, 160)
plt.title("Discrete logistic distribution")
plt.xlabel("Pixel value")
plt.ylabel("Probability")
plt.show()
plt.close()

Instead of the softmax, the model would output mean and standard deviations for the 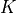 logistics we use in the mixture. This is one of the improvements in autoregressive models that PixelCNN++ [3] has introduced compared to the original PixelCNN.
logistics we use in the mixture. This is one of the improvements in autoregressive models that PixelCNN++ [3] has introduced compared to the original PixelCNN.
Conclusion¶
In this tutorial, we have looked at autoregressive image modeling, and implemented the PixelCNN architecture. With the usage of masked convolutions, we are able to apply a convolutional network in which a pixel is only influenced by all its predecessors. Separating the masked convolution into a horizontal and vertical stack allowed us to remove the known blind spot on the right upper row of a pixel. In experiments, autoregressive models outperformed normalizing flows in terms of bits per dimension, but are much slower to sample from. Improvements, that we have not implemented ourselves here, are discrete logistic mixtures, a downsampling architecture, and changing the pixel order in a diagonal fashion (see PixelSNAIL). Overall, autoregressive models are another, strong family of generative models, which however are mostly used in sequence tasks because of their linear scaling in sampling time than quadratic as on images.
References¶
[1] van den Oord, A., et al. “Pixel Recurrent Neural Networks.” arXiv preprint arXiv:1601.06759 (2016). Link
[2] van den Oord, A., et al. “Conditional Image Generation with PixelCNN Decoders.” In Advances in Neural Information Processing Systems 29, pp. 4790–4798 (2016). Link
[3] Salimans, Tim, et al. “PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications.” arXiv preprint arXiv:1701.05517 (2017). Link
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Slack!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

