Introduction to PyTorch Lightning¶
Author: Lightning.ai
License: CC BY-SA
Generated: 2024-07-26T13:06:57.153249
In this notebook, we’ll go over the basics of lightning by preparing models to train on the MNIST Handwritten Digits dataset.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Discord
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "numpy <2.0" "torchmetrics>=1.0, <1.5" "torchmetrics >=0.11.0" "matplotlib" "pandas" "seaborn" "pytorch-lightning >=2.0,<2.4" "torch>=1.8.1, <2.5" "torchvision"
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[2]:
# ------------------- Preliminaries ------------------- #
import os
from dataclasses import dataclass
from typing import Tuple
import pandas as pd
import pytorch_lightning as pl
import seaborn as sn
import torch
from IPython.display import display
from pytorch_lightning.loggers import CSVLogger
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchmetrics import Accuracy
from torchvision import transforms
from torchvision.datasets import MNIST
# ------------------- Configuration ------------------- #
@dataclass
class Config:
"""Configuration options for the Lightning MNIST example.
Args:
data_dir : The path to the directory where the MNIST dataset is stored. Defaults to the value of
the 'PATH_DATASETS' environment variable or '.' if not set.
save_dir : The path to the directory where the training logs will be saved. Defaults to 'logs/'.
batch_size : The batch size to use during training. Defaults to 256 if a GPU is available,
or 64 otherwise.
max_epochs : The maximum number of epochs to train the model for. Defaults to 3.
accelerator : The accelerator to use for training. Can be one of "cpu", "gpu", "tpu", "ipu", "auto".
devices : The number of devices to use for training. Defaults to 1.
Examples:
This dataclass can be used to specify the configuration options for training a PyTorch Lightning model on the
MNIST dataset. A new instance of this dataclass can be created as follows:
>>> config = Config()
The default values for each argument are shown in the documentation above. If desired, any of these values can be
overridden when creating a new instance of the dataclass:
>>> config = Config(batch_size=128, max_epochs=5)
"""
data_dir: str = os.environ.get("PATH_DATASETS", ".")
save_dir: str = "logs/"
batch_size: int = 256 if torch.cuda.is_available() else 64
max_epochs: int = 3
accelerator: str = "auto"
devices: int = 1
config = Config()
Simplest example¶
Here’s the simplest most minimal example with just a training loop (no validation, no testing).
Keep in Mind - A LightningModule is a PyTorch nn.Module - it just has a few more helpful features.
[3]:
class MNISTModel(pl.LightningModule):
"""A PyTorch Lightning module for classifying images in the MNIST dataset.
Attributes:
l1 : A linear layer that maps input features to output features.
Methods:
forward(x):
Performs a forward pass through the model.
training_step(batch, batch_nb):
Defines a single training step for the model.
configure_optimizers():
Configures the optimizer to use during training.
Examples:
The MNISTModel class can be used to create and train a PyTorch Lightning model for classifying images in the MNIST
dataset. To create a new instance of the model, simply instantiate the class:
>>> model = MNISTModel()
The model can then be trained using a PyTorch Lightning trainer object:
>>> trainer = pl.Trainer()
>>> trainer.fit(model)
"""
def __init__(self):
"""Initializes a new instance of the MNISTModel class."""
super().__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Performs a forward pass through the model.
Args:
x : The input tensor to pass through the model.
Returns:
activated : The output tensor produced by the model.
Examples:
>>> model = MNISTModel()
>>> x = torch.randn(1, 1, 28, 28)
>>> output = model(x)
"""
flattened = x.view(x.size(0), -1)
hidden = self.l1(flattened)
activated = torch.relu(hidden)
return activated
def training_step(self, batch: Tuple[torch.Tensor, torch.Tensor], batch_nb: int) -> torch.Tensor:
"""Defines a single training step for the model.
Args:
batch: A tuple containing the input and target tensors for the batch.
batch_nb: The batch number.
Returns:
torch.Tensor: The loss value for the current batch.
Examples:
>>> model = MNISTModel()
>>> x = torch.randn(1, 1, 28, 28)
>>> y = torch.tensor([1])
>>> loss = model.training_step((x, y), 0)
"""
x, y = batch
loss = F.cross_entropy(self(x), y)
return loss
def configure_optimizers(self) -> torch.optim.Optimizer:
"""Configures the optimizer to use during training.
Returns:
torch.optim.Optimizer: The optimizer to use during training.
Examples:
>>> model = MNISTModel()
>>> optimizer = model.configure_optimizers()
"""
return torch.optim.Adam(self.parameters(), lr=0.02)
By using the Trainer you automatically get: 1. Tensorboard logging 2. Model checkpointing 3. Training and validation loop 4. early-stopping
[4]:
# Init our model
mnist_model = MNISTModel()
# Init DataLoader from MNIST Dataset
train_ds = MNIST(config.data_dir, train=True, download=True, transform=transforms.ToTensor())
# Create a dataloader
train_loader = DataLoader(train_ds, batch_size=config.batch_size)
# Initialize a trainer
trainer = pl.Trainer(
accelerator=config.accelerator,
devices=config.devices,
max_epochs=config.max_epochs,
)
# Train the model ⚡
trainer.fit(mnist_model, train_loader)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz to /__w/13/s/.datasets/MNIST/raw/train-images-idx3-ubyte.gz
100%|██████████| 9912422/9912422 [00:00<00:00, 39118704.53it/s]
Extracting /__w/13/s/.datasets/MNIST/raw/train-images-idx3-ubyte.gz to /__w/13/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz to /__w/13/s/.datasets/MNIST/raw/train-labels-idx1-ubyte.gz
100%|██████████| 28881/28881 [00:00<00:00, 3079120.86it/s]
Extracting /__w/13/s/.datasets/MNIST/raw/train-labels-idx1-ubyte.gz to /__w/13/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to /__w/13/s/.datasets/MNIST/raw/t10k-images-idx3-ubyte.gz
100%|██████████| 1648877/1648877 [00:00<00:00, 21992773.04it/s]
Extracting /__w/13/s/.datasets/MNIST/raw/t10k-images-idx3-ubyte.gz to /__w/13/s/.datasets/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz to /__w/13/s/.datasets/MNIST/raw/t10k-labels-idx1-ubyte.gz
100%|██████████| 4542/4542 [00:00<00:00, 5054531.38it/s]
Extracting /__w/13/s/.datasets/MNIST/raw/t10k-labels-idx1-ubyte.gz to /__w/13/s/.datasets/MNIST/raw
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/connectors/logger_connector/logger_connector.py:75: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `pytorch_lightning` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: /__w/13/s/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params | Mode
----------------------------------------
0 | l1 | Linear | 7.9 K | train
----------------------------------------
7.9 K Trainable params
0 Non-trainable params
7.9 K Total params
0.031 Total estimated model params size (MB)
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:424: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=3` reached.
A more complete MNIST Lightning Module Example¶
That wasn’t so hard was it?
Now that we’ve got our feet wet, let’s dive in a bit deeper and write a more complete LightningModule for MNIST…
This time, we’ll bake in all the dataset specific pieces directly in the LightningModule. This way, we can avoid writing extra code at the beginning of our script every time we want to run it.
Note what the following built-in functions are doing:¶
-
This is where we can download the dataset. We point to our desired dataset and ask torchvision’s
MNISTdataset class to download if the dataset isn’t found there.Note we do not make any state assignments in this function (i.e.
self.something = ...)
setup(stage) ⚙️
Loads in data from file and prepares PyTorch tensor datasets for each split (train, val, test).
Setup expects a ‘stage’ arg which is used to separate logic for ‘fit’ and ‘test’.
If you don’t mind loading all your datasets at once, you can set up a condition to allow for both ‘fit’ related setup and ‘test’ related setup to run whenever
Noneis passed tostage(or ignore it altogether and exclude any conditionals).Note this runs across all GPUs and it is safe to make state assignments here
-
train_dataloader(),val_dataloader(), andtest_dataloader()all return PyTorchDataLoaderinstances that are created by wrapping their respective datasets that we prepared insetup()
[5]:
class LitMNIST(pl.LightningModule):
"""PyTorch Lightning module for training a multi-layer perceptron (MLP) on the MNIST dataset.
Attributes:
data_dir : The path to the directory where the MNIST data will be downloaded.
hidden_size : The number of units in the hidden layer of the MLP.
learning_rate : The learning rate to use for training the MLP.
Methods:
forward(x):
Performs a forward pass through the MLP.
training_step(batch, batch_idx):
Defines a single training step for the MLP.
validation_step(batch, batch_idx):
Defines a single validation step for the MLP.
test_step(batch, batch_idx):
Defines a single testing step for the MLP.
configure_optimizers():
Configures the optimizer to use for training the MLP.
prepare_data():
Downloads the MNIST dataset.
setup(stage=None):
Splits the MNIST dataset into train, validation, and test sets.
train_dataloader():
Returns a DataLoader for the training set.
val_dataloader():
Returns a DataLoader for the validation set.
test_dataloader():
Returns a DataLoader for the test set.
"""
def __init__(self, data_dir: str = config.data_dir, hidden_size: int = 64, learning_rate: float = 2e-4):
"""Initializes a new instance of the LitMNIST class.
Args:
data_dir : The path to the directory where the MNIST data will be downloaded. Defaults to config.data_dir.
hidden_size : The number of units in the hidden layer of the MLP (default is 64).
learning_rate : The learning rate to use for training the MLP (default is 2e-4).
"""
super().__init__()
# Set our init args as class attributes
self.data_dir = data_dir
self.hidden_size = hidden_size
self.learning_rate = learning_rate
# Hardcode some dataset specific attributes
self.num_classes = 10
self.dims = (1, 28, 28)
channels, width, height = self.dims
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
# Define PyTorch model
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(channels * width * height, hidden_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(hidden_size, self.num_classes),
)
self.val_accuracy = Accuracy(task="multiclass", num_classes=10)
self.test_accuracy = Accuracy(task="multiclass", num_classes=10)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Performs a forward pass through the MLP.
Args:
x : The input data.
Returns:
torch.Tensor: The output of the MLP.
"""
x = self.model(x)
return F.log_softmax(x, dim=1)
def training_step(self, batch: Tuple[torch.Tensor, torch.Tensor], batch_nb: int) -> torch.Tensor:
"""Defines a single training step for the MLP.
Args:
batch: A tuple containing the input data and target labels.
batch_idx: The index of the current batch.
Returns:
(torch.Tensor): The training loss.
"""
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
return loss
def validation_step(self, batch: Tuple[torch.Tensor, torch.Tensor], batch_nb: int) -> None:
"""Defines a single validation step for the MLP.
Args:
batch : A tuple containing the input data and target labels.
batch_idx : The index of the current batch.
"""
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
self.val_accuracy.update(preds, y)
# Calling self.log will surface up scalars for you in TensorBoard
self.log("val_loss", loss, prog_bar=True)
self.log("val_acc", self.val_accuracy, prog_bar=True)
def test_step(self, batch: Tuple[torch.Tensor, torch.Tensor], batch_nb: int) -> None:
"""Defines a single testing step for the MLP.
Args:
batch : A tuple containing the input data and target labels.
batch_idx : The index of the current batch.
"""
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
self.test_accuracy.update(preds, y)
# Calling self.log will surface up scalars for you in TensorBoard
self.log("test_loss", loss, prog_bar=True)
self.log("test_acc", self.test_accuracy, prog_bar=True)
def configure_optimizers(self) -> torch.optim.Optimizer:
"""Configures the optimizer to use for training the MLP.
Returns:
torch.optim.Optimizer: The optimizer.
"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
# ------------------------------------- #
# DATA RELATED HOOKS
# ------------------------------------- #
def prepare_data(self) -> None:
"""Downloads the MNIST dataset."""
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage: str = None) -> None:
"""Splits the MNIST dataset into train, validation, and test sets.
Args:
stage : The current stage (either "fit" or "test"). Defaults to None.
"""
# Assign train/val datasets for use in dataloaders
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
# Assign test dataset for use in dataloader(s)
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self) -> DataLoader:
"""Returns a DataLoader for the training set.
Returns:
DataLoader: The training DataLoader.
"""
return DataLoader(self.mnist_train, batch_size=config.batch_size)
def val_dataloader(self) -> DataLoader:
"""Returns a DataLoader for the validation set.
Returns:
DataLoader: The validation DataLoader.
"""
return DataLoader(self.mnist_val, batch_size=config.batch_size)
def test_dataloader(self) -> DataLoader:
"""Returns a DataLoader for the test set.
Returns:
DataLoader: The test DataLoader.
"""
return DataLoader(self.mnist_test, batch_size=config.batch_size)
[6]:
# Instantiate the LitMNIST model
model = LitMNIST()
# Instantiate a PyTorch Lightning trainer with the specified configuration
trainer = pl.Trainer(
accelerator=config.accelerator,
devices=config.devices,
max_epochs=config.max_epochs,
logger=CSVLogger(save_dir=config.save_dir),
)
# Train the model using the trainer
trainer.fit(model)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
Missing logger folder: logs/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params | Mode
-------------------------------------------------------------
0 | model | Sequential | 55.1 K | train
1 | val_accuracy | MulticlassAccuracy | 0 | train
2 | test_accuracy | MulticlassAccuracy | 0 | train
-------------------------------------------------------------
55.1 K Trainable params
0 Non-trainable params
55.1 K Total params
0.220 Total estimated model params size (MB)
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:424: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=3` reached.
Testing¶
To test a model, call trainer.test(model).
Or, if you’ve just trained a model, you can just call trainer.test() and Lightning will automatically test using the best saved checkpoint (conditioned on val_loss).
[7]:
trainer.test(ckpt_path="best")
Restoring states from the checkpoint path at logs/lightning_logs/version_0/checkpoints/epoch=2-step=645.ckpt
/usr/local/lib/python3.10/dist-packages/lightning_fabric/utilities/cloud_io.py:57: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Loaded model weights from the checkpoint at logs/lightning_logs/version_0/checkpoints/epoch=2-step=645.ckpt
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py:424: The 'test_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
test_acc 0.9290000200271606
test_loss 0.24375776946544647
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[7]:
[{'test_loss': 0.24375776946544647, 'test_acc': 0.9290000200271606}]
Bonus Tip¶
You can keep calling trainer.fit(model) as many times as you’d like to continue training
[8]:
trainer.fit(model)
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/model_checkpoint.py:652: Checkpoint directory logs/lightning_logs/version_0/checkpoints exists and is not empty.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params | Mode
-------------------------------------------------------------
0 | model | Sequential | 55.1 K | train
1 | val_accuracy | MulticlassAccuracy | 0 | train
2 | test_accuracy | MulticlassAccuracy | 0 | train
-------------------------------------------------------------
55.1 K Trainable params
0 Non-trainable params
55.1 K Total params
0.220 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=3` reached.
In Colab, you can use the TensorBoard magic function to view the logs that Lightning has created for you!
[9]:
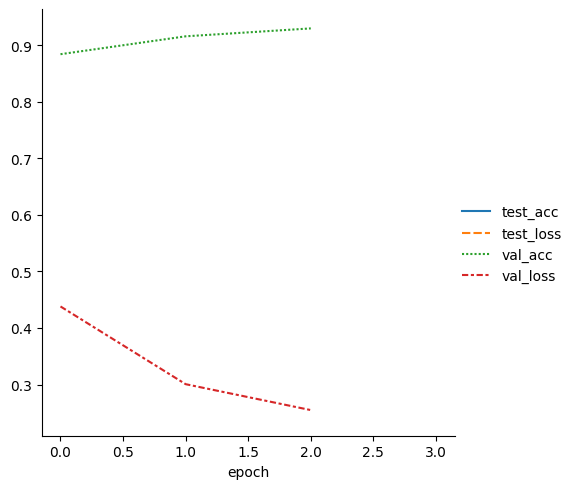
# Read in the training metrics from the CSV file generated by the logger
metrics = pd.read_csv(f"{trainer.logger.log_dir}/metrics.csv")
# Remove the "step" column, which is not needed for our analysis
del metrics["step"]
# Set the epoch column as the index, for easier plotting
metrics.set_index("epoch", inplace=True)
# Display the first few rows of the metrics table, excluding any columns with all NaN values
display(metrics.dropna(axis=1, how="all").head())
# Create a line plot of the training metrics using Seaborn
sn.relplot(data=metrics, kind="line")
| test_acc | test_loss | val_acc | val_loss | |
|---|---|---|---|---|
| epoch | ||||
| 0 | NaN | NaN | 0.8838 | 0.437945 |
| 1 | NaN | NaN | 0.9154 | 0.300581 |
| 2 | NaN | NaN | 0.9294 | 0.254781 |
| 3 | 0.929 | 0.243758 | NaN | NaN |
[9]:
<seaborn.axisgrid.FacetGrid at 0x7f2dd427f820>
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Discord!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

