PyTorch Lightning CIFAR10 ~94% Baseline Tutorial¶
Author: Lightning.ai
License: CC BY-SA
Generated: 2024-07-26T12:02:20.094943
Train a Resnet to 94% accuracy on Cifar10!
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Discord
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "torchvision" "matplotlib" "torchmetrics>=1.0, <1.5" "numpy <2.0" "pytorch-lightning >=2.0,<2.4" "pandas" "seaborn" "torch>=1.8.1, <2.5"
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[2]:
# Run this if you intend to use TPUs
# !pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.8-cp37-cp37m-linux_x86_64.whl
[3]:
import os
import pandas as pd
import pytorch_lightning as pl
import seaborn as sn
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from IPython.display import display
from pytorch_lightning.callbacks import LearningRateMonitor
from pytorch_lightning.loggers import CSVLogger
from torch.optim.lr_scheduler import OneCycleLR
from torch.optim.swa_utils import AveragedModel
from torch.utils.data import DataLoader, random_split
from torchmetrics.functional import accuracy
from torchvision.datasets import CIFAR10
pl.seed_everything(7)
PATH_DATASETS = os.environ.get("PATH_DATASETS", ".")
BATCH_SIZE = 256 if torch.cuda.is_available() else 64
NUM_WORKERS = int(os.cpu_count() / 2)
Seed set to 7
CIFAR10 DataLoaders¶
[4]:
cifar10_normalization = torchvision.transforms.Normalize(
mean=[x / 255.0 for x in [125.3, 123.0, 113.9]],
std=[x / 255.0 for x in [63.0, 62.1, 66.7]],
)
def split_dataset(dataset, val_split=0.2, train=True):
"""Splits the dataset into train and validation set."""
len_dataset = len(dataset)
splits = get_splits(len_dataset, val_split)
dataset_train, dataset_val = random_split(dataset, splits, generator=torch.Generator().manual_seed(42))
if train:
return dataset_train
return dataset_val
def get_splits(len_dataset, val_split):
"""Computes split lengths for train and validation set."""
if isinstance(val_split, int):
train_len = len_dataset - val_split
splits = [train_len, val_split]
elif isinstance(val_split, float):
val_len = int(val_split * len_dataset)
train_len = len_dataset - val_len
splits = [train_len, val_len]
else:
raise ValueError(f"Unsupported type {type(val_split)}")
return splits
train_transforms = torchvision.transforms.Compose(
[
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
cifar10_normalization,
]
)
test_transforms = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
cifar10_normalization,
]
)
dataset_train = CIFAR10(PATH_DATASETS, train=True, download=True, transform=train_transforms)
dataset_val = CIFAR10(PATH_DATASETS, train=True, download=True, transform=test_transforms)
dataset_train = split_dataset(dataset_train)
dataset_val = split_dataset(dataset_val, train=False)
dataset_test = CIFAR10(PATH_DATASETS, train=False, download=True, transform=test_transforms)
train_dataloader = DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS)
val_dataloader = DataLoader(dataset_val, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS)
test_dataloader = DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to /__w/14/s/.datasets/cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [00:04<00:00, 38826098.18it/s]
Extracting /__w/14/s/.datasets/cifar-10-python.tar.gz to /__w/14/s/.datasets
Files already downloaded and verified
Files already downloaded and verified
Resnet¶
Modify the pre-existing Resnet architecture from TorchVision. The pre-existing architecture is based on ImageNet images (224x224) as input. So we need to modify it for CIFAR10 images (32x32).
[5]:
def create_model():
model = torchvision.models.resnet18(pretrained=False, num_classes=10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
model.maxpool = nn.Identity()
return model
Lightning Module¶
Check out the `configure_optimizers <https://lightning.ai/docs/pytorch/stable/common/lightning_module.html#configure-optimizers>`__ method to use custom Learning Rate schedulers. The OneCycleLR with SGD will get you to around 92-93% accuracy in 20-30 epochs and 93-94% accuracy in 40-50 epochs. Feel free to experiment with different LR schedules from https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
[6]:
class LitResnet(pl.LightningModule):
def __init__(self, lr=0.05):
super().__init__()
self.save_hyperparameters()
self.model = create_model()
def forward(self, x):
out = self.model(x)
return F.log_softmax(out, dim=1)
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
self.log("train_loss", loss)
return loss
def evaluate(self, batch, stage=None):
x, y = batch
logits = self(x)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
acc = accuracy(preds, y, task="multiclass", num_classes=10)
if stage:
self.log(f"{stage}_loss", loss, prog_bar=True)
self.log(f"{stage}_acc", acc, prog_bar=True)
def validation_step(self, batch, batch_idx):
self.evaluate(batch, "val")
def test_step(self, batch, batch_idx):
self.evaluate(batch, "test")
def configure_optimizers(self):
optimizer = torch.optim.SGD(
self.parameters(),
lr=self.hparams.lr,
momentum=0.9,
weight_decay=5e-4,
)
steps_per_epoch = 45000 // BATCH_SIZE
scheduler_dict = {
"scheduler": OneCycleLR(
optimizer,
0.1,
epochs=self.trainer.max_epochs,
steps_per_epoch=steps_per_epoch,
),
"interval": "step",
}
return {"optimizer": optimizer, "lr_scheduler": scheduler_dict}
[7]:
model = LitResnet(lr=0.05)
trainer = pl.Trainer(
max_epochs=5,
accelerator="auto",
devices=1,
logger=CSVLogger(save_dir="logs/"),
callbacks=[LearningRateMonitor(logging_interval="step")],
)
trainer.fit(model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader)
trainer.test(model, dataloaders=test_dataloader)
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
Missing logger folder: logs/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params | Mode
-----------------------------------------
0 | model | ResNet | 11.2 M | train
-----------------------------------------
11.2 M Trainable params
0 Non-trainable params
11.2 M Total params
44.696 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=5` reached.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
test_acc 0.817799985408783
test_loss 0.529252290725708
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[7]:
[{'test_loss': 0.529252290725708, 'test_acc': 0.817799985408783}]
[8]:
metrics = pd.read_csv(f"{trainer.logger.log_dir}/metrics.csv")
del metrics["step"]
metrics.set_index("epoch", inplace=True)
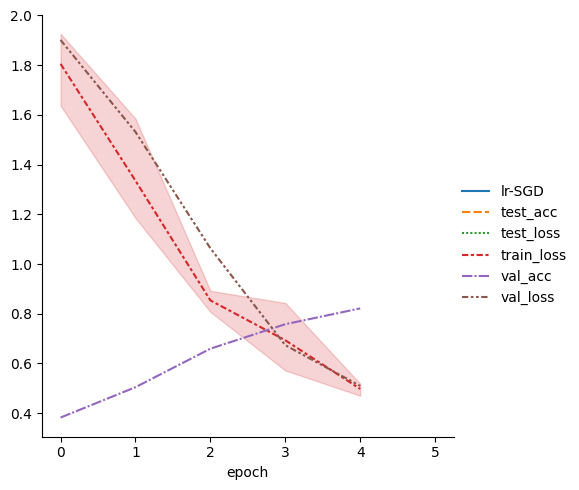
display(metrics.dropna(axis=1, how="all").head())
sn.relplot(data=metrics, kind="line")
| lr-SGD | test_acc | test_loss | train_loss | val_acc | val_loss | |
|---|---|---|---|---|---|---|
| epoch | ||||||
| NaN | 0.012079 | NaN | NaN | NaN | NaN | NaN |
| 0.0 | NaN | NaN | NaN | 1.852811 | NaN | NaN |
| NaN | 0.034132 | NaN | NaN | NaN | NaN | NaN |
| 0.0 | NaN | NaN | NaN | 1.636740 | NaN | NaN |
| NaN | 0.062440 | NaN | NaN | NaN | NaN | NaN |
[8]:
<seaborn.axisgrid.FacetGrid at 0x7f1f370ec490>
Bonus: Use Stochastic Weight Averaging to get a boost on performance¶
Use SWA from torch.optim to get a quick performance boost. Also shows a couple of cool features from Lightning: - Use training_epoch_end to run code after the end of every epoch - Use a pretrained model directly with this wrapper for SWA
[9]:
class SWAResnet(LitResnet):
def __init__(self, trained_model, lr=0.01):
super().__init__()
self.save_hyperparameters("lr")
self.model = trained_model
self.swa_model = AveragedModel(self.model)
def forward(self, x):
out = self.swa_model(x)
return F.log_softmax(out, dim=1)
def on_train_epoch_end(self):
self.swa_model.update_parameters(self.model)
def validation_step(self, batch, batch_idx, stage=None):
x, y = batch
logits = F.log_softmax(self.model(x), dim=1)
loss = F.nll_loss(logits, y)
preds = torch.argmax(logits, dim=1)
acc = accuracy(preds, y, task="multiclass", num_classes=10)
self.log("val_loss", loss, prog_bar=True)
self.log("val_acc", acc, prog_bar=True)
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.model.parameters(), lr=self.hparams.lr, momentum=0.9, weight_decay=5e-4)
return optimizer
# def on_train_end(self): # todo: failing as trainer has only dataloaders, not datamodules
# update_bn(self.trainer.datamodule.train_dataloader(), self.swa_model, device=self.device)
[10]:
swa_model = SWAResnet(model.model, lr=0.01)
swa_trainer = pl.Trainer(
max_epochs=5,
accelerator="auto",
devices=1,
logger=CSVLogger(save_dir="logs/"),
)
swa_trainer.fit(swa_model, train_dataloaders=train_dataloader, val_dataloaders=val_dataloader)
swa_trainer.test(swa_model, dataloaders=test_dataloader)
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/parsing.py:208: Attribute 'trained_model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['trained_model'])`.
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
| Name | Type | Params | Mode
----------------------------------------------------
0 | model | ResNet | 11.2 M | train
1 | swa_model | AveragedModel | 11.2 M | train
----------------------------------------------------
22.3 M Trainable params
0 Non-trainable params
22.3 M Total params
89.392 Total estimated model params size (MB)
`Trainer.fit` stopped: `max_epochs=5` reached.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Test metric DataLoader 0
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
test_acc 0.817799985408783
test_loss 0.529252290725708
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[10]:
[{'test_loss': 0.529252290725708, 'test_acc': 0.817799985408783}]
[11]:
metrics = pd.read_csv(f"{trainer.logger.log_dir}/metrics.csv")
del metrics["step"]
metrics.set_index("epoch", inplace=True)
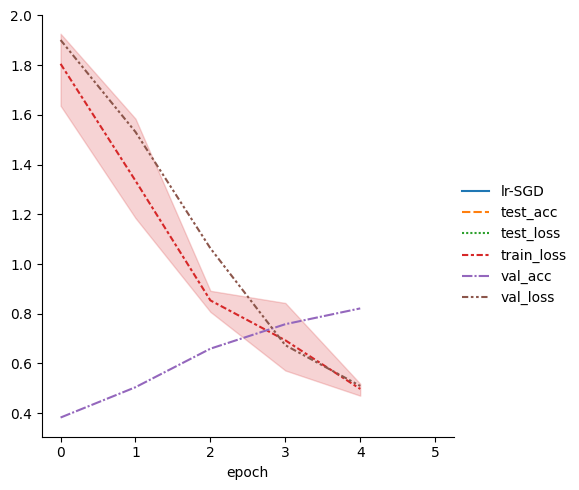
display(metrics.dropna(axis=1, how="all").head())
sn.relplot(data=metrics, kind="line")
| lr-SGD | test_acc | test_loss | train_loss | val_acc | val_loss | |
|---|---|---|---|---|---|---|
| epoch | ||||||
| NaN | 0.012079 | NaN | NaN | NaN | NaN | NaN |
| 0.0 | NaN | NaN | NaN | 1.852811 | NaN | NaN |
| NaN | 0.034132 | NaN | NaN | NaN | NaN | NaN |
| 0.0 | NaN | NaN | NaN | 1.636740 | NaN | NaN |
| NaN | 0.062440 | NaN | NaN | NaN | NaN | NaN |
[11]:
<seaborn.axisgrid.FacetGrid at 0x7f1f370ef160>
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Discord!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

