Tutorial 4: Inception, ResNet and DenseNet¶
Author: Phillip Lippe
License: CC BY-SA
Generated: 2022-05-12T13:44:17.079573
In this tutorial, we will implement and discuss variants of modern CNN architectures. There have been many different architectures been proposed over the past few years. Some of the most impactful ones, and still relevant today, are the following: GoogleNet/Inception architecture (winner of ILSVRC 2014), ResNet (winner of ILSVRC 2015), and DenseNet (best paper award CVPR 2017). All of them were state-of-the-art models when being proposed, and the core ideas of these networks are the foundations for most current state-of-the-art architectures. Thus, it is important to understand these architectures in detail and learn how to implement them. This notebook is part of a lecture series on Deep Learning at the University of Amsterdam. The full list of tutorials can be found at https://uvadlc-notebooks.rtfd.io.
Open in 
Give us a ⭐ on Github | Check out the documentation | Join us on Slack
Setup¶
This notebook requires some packages besides pytorch-lightning.
[1]:
! pip install --quiet "setuptools==59.5.0" "seaborn" "ipython[notebook]" "tabulate" "matplotlib" "torchvision" "torchmetrics>=0.7" "pytorch-lightning>=1.4" "torch>=1.8"
Let’s start with importing our standard libraries here.
[2]:
import os
import urllib.request
from types import SimpleNamespace
from urllib.error import HTTPError
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pytorch_lightning as pl
import seaborn as sns
import tabulate
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torchvision
%matplotlib inline
from IPython.display import HTML, display, set_matplotlib_formats
from PIL import Image
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
from torchvision import transforms
from torchvision.datasets import CIFAR10
set_matplotlib_formats("svg", "pdf") # For export
matplotlib.rcParams["lines.linewidth"] = 2.0
sns.reset_orig()
# PyTorch
# Torchvision
/usr/lib/python3.8/site-packages/apex/pyprof/__init__.py:5: FutureWarning: pyprof will be removed by the end of June, 2022
warnings.warn("pyprof will be removed by the end of June, 2022", FutureWarning)
/usr/local/lib/python3.8/dist-packages/numpy/core/getlimits.py:499: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/usr/local/lib/python3.8/dist-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float32'> type is zero.
return self._float_to_str(self.smallest_subnormal)
/usr/local/lib/python3.8/dist-packages/numpy/core/getlimits.py:499: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
setattr(self, word, getattr(machar, word).flat[0])
/usr/local/lib/python3.8/dist-packages/numpy/core/getlimits.py:89: UserWarning: The value of the smallest subnormal for <class 'numpy.float64'> type is zero.
return self._float_to_str(self.smallest_subnormal)
WARNING:root:Bagua cannot detect bundled NCCL library, Bagua will try to use system NCCL instead. If you encounter any error, please run `import bagua_core; bagua_core.install_deps()` or the `bagua_install_deps.py` script to install bundled libraries.
/tmp/ipykernel_2857/1100401100.py:25: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
set_matplotlib_formats("svg", "pdf") # For export
We will use the same set_seed function as in the previous tutorials, as well as the path variables DATASET_PATH and CHECKPOINT_PATH. Adjust the paths if necessary.
[3]:
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = os.environ.get("PATH_DATASETS", "data/")
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = os.environ.get("PATH_CHECKPOINT", "saved_models/ConvNets")
# Function for setting the seed
pl.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.determinstic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
Global seed set to 42
We also have pretrained models and Tensorboards (more on this later) for this tutorial, and download them below.
[4]:
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/"
# Files to download
pretrained_files = [
"GoogleNet.ckpt",
"ResNet.ckpt",
"ResNetPreAct.ckpt",
"DenseNet.ckpt",
"tensorboards/GoogleNet/events.out.tfevents.googlenet",
"tensorboards/ResNet/events.out.tfevents.resnet",
"tensorboards/ResNetPreAct/events.out.tfevents.resnetpreact",
"tensorboards/DenseNet/events.out.tfevents.densenet",
]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if "/" in file_name:
os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print(f"Downloading {file_url}...")
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print(
"Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n",
e,
)
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/GoogleNet.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/ResNet.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/ResNetPreAct.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/DenseNet.ckpt...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/tensorboards/GoogleNet/events.out.tfevents.googlenet...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/tensorboards/ResNet/events.out.tfevents.resnet...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/tensorboards/ResNetPreAct/events.out.tfevents.resnetpreact...
Downloading https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial5/tensorboards/DenseNet/events.out.tfevents.densenet...
Throughout this tutorial, we will train and evaluate the models on the CIFAR10 dataset. This allows you to compare the results obtained here with the model you have implemented in the first assignment. As we have learned from the previous tutorial about initialization, it is important to have the data preprocessed with a zero mean. Therefore, as a first step, we will calculate the mean and standard deviation of the CIFAR dataset:
[5]:
train_dataset = CIFAR10(root=DATASET_PATH, train=True, download=True)
DATA_MEANS = (train_dataset.data / 255.0).mean(axis=(0, 1, 2))
DATA_STD = (train_dataset.data / 255.0).std(axis=(0, 1, 2))
print("Data mean", DATA_MEANS)
print("Data std", DATA_STD)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to /__w/1/s/.datasets/cifar-10-python.tar.gz
Extracting /__w/1/s/.datasets/cifar-10-python.tar.gz to /__w/1/s/.datasets
Data mean [0.49139968 0.48215841 0.44653091]
Data std [0.24703223 0.24348513 0.26158784]
We will use this information to define a transforms.Normalize module which will normalize our data accordingly. Additionally, we will use data augmentation during training. This reduces the risk of overfitting and helps CNNs to generalize better. Specifically, we will apply two random augmentations.
First, we will flip each image horizontally by a chance of 50% (transforms.RandomHorizontalFlip). The object class usually does not change when flipping an image, and we don’t expect any image information to be dependent on the horizontal orientation. This would be however different if we would try to detect digits or letters in an image, as those have a certain orientation.
The second augmentation we use is called transforms.RandomResizedCrop. This transformation scales the image in a small range, while eventually changing the aspect ratio, and crops it afterward in the previous size. Therefore, the actual pixel values change while the content or overall semantics of the image stays the same.
We will randomly split the training dataset into a training and a validation set. The validation set will be used for determining early stopping. After finishing the training, we test the models on the CIFAR test set.
[6]:
test_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(DATA_MEANS, DATA_STD)])
# For training, we add some augmentation. Networks are too powerful and would overfit.
train_transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((32, 32), scale=(0.8, 1.0), ratio=(0.9, 1.1)),
transforms.ToTensor(),
transforms.Normalize(DATA_MEANS, DATA_STD),
]
)
# Loading the training dataset. We need to split it into a training and validation part
# We need to do a little trick because the validation set should not use the augmentation.
train_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=train_transform, download=True)
val_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=test_transform, download=True)
pl.seed_everything(42)
train_set, _ = torch.utils.data.random_split(train_dataset, [45000, 5000])
pl.seed_everything(42)
_, val_set = torch.utils.data.random_split(val_dataset, [45000, 5000])
# Loading the test set
test_set = CIFAR10(root=DATASET_PATH, train=False, transform=test_transform, download=True)
# We define a set of data loaders that we can use for various purposes later.
train_loader = data.DataLoader(train_set, batch_size=128, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = data.DataLoader(val_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
test_loader = data.DataLoader(test_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
Files already downloaded and verified
Files already downloaded and verified
Global seed set to 42
Global seed set to 42
Files already downloaded and verified
To verify that our normalization works, we can print out the mean and standard deviation of the single batch. The mean should be close to 0 and the standard deviation close to 1 for each channel:
[7]:
imgs, _ = next(iter(train_loader))
print("Batch mean", imgs.mean(dim=[0, 2, 3]))
print("Batch std", imgs.std(dim=[0, 2, 3]))
Batch mean tensor([0.0231, 0.0006, 0.0005])
Batch std tensor([0.9865, 0.9849, 0.9868])
Finally, let’s visualize a few images from the training set, and how they look like after random data augmentation:
[8]:
NUM_IMAGES = 4
images = [train_dataset[idx][0] for idx in range(NUM_IMAGES)]
orig_images = [Image.fromarray(train_dataset.data[idx]) for idx in range(NUM_IMAGES)]
orig_images = [test_transform(img) for img in orig_images]
img_grid = torchvision.utils.make_grid(torch.stack(images + orig_images, dim=0), nrow=4, normalize=True, pad_value=0.5)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(8, 8))
plt.title("Augmentation examples on CIFAR10")
plt.imshow(img_grid)
plt.axis("off")
plt.show()
plt.close()

PyTorch Lightning¶
In this notebook and in many following ones, we will make use of the library PyTorch Lightning. PyTorch Lightning is a framework that simplifies your code needed to train, evaluate, and test a model in PyTorch. It also handles logging into TensorBoard, a visualization toolkit for ML experiments, and saving model checkpoints automatically with minimal code overhead from our side. This is extremely helpful for us as we want to focus on implementing different model architectures and spend little time on other code overhead. Note that at the time of writing/teaching, the framework has been released in version 1.3. Future versions might have a slightly changed interface and thus might not work perfectly with the code (we will try to keep it up-to-date as much as possible).
Now, we will take the first step in PyTorch Lightning, and continue to explore the framework in our other tutorials. PyTorch Lightning comes with a lot of useful functions, such as one for setting the seed as we have seen before:
[9]:
# Setting the seed
pl.seed_everything(42)
Global seed set to 42
[9]:
42
Thus, in the future, we don’t have to define our own set_seed function anymore.
In PyTorch Lightning, we define pl.LightningModule’s (inheriting from Module) that organize our code into 5 main sections:
Initialization (
__init__), where we create all necessary parameters/modelsOptimizers (
configure_optimizers) where we create the optimizers, learning rate scheduler, etc.Training loop (
training_step) where we only have to define the loss calculation for a single batch (the loop of optimizer.zero_grad(), loss.backward() and optimizer.step(), as well as any logging/saving operation, is done in the background)Validation loop (
validation_step) where similarly to the training, we only have to define what should happen per stepTest loop (
test_step) which is the same as validation, only on a test set.
Therefore, we don’t abstract the PyTorch code, but rather organize it and define some default operations that are commonly used. If you need to change something else in your training/validation/test loop, there are many possible functions you can overwrite (see the docs for details).
Now we can look at an example of how a Lightning Module for training a CNN looks like:
[10]:
class CIFARModule(pl.LightningModule):
def __init__(self, model_name, model_hparams, optimizer_name, optimizer_hparams):
"""
Inputs:
model_name - Name of the model/CNN to run. Used for creating the model (see function below)
model_hparams - Hyperparameters for the model, as dictionary.
optimizer_name - Name of the optimizer to use. Currently supported: Adam, SGD
optimizer_hparams - Hyperparameters for the optimizer, as dictionary. This includes learning rate, weight decay, etc.
"""
super().__init__()
# Exports the hyperparameters to a YAML file, and create "self.hparams" namespace
self.save_hyperparameters()
# Create model
self.model = create_model(model_name, model_hparams)
# Create loss module
self.loss_module = nn.CrossEntropyLoss()
# Example input for visualizing the graph in Tensorboard
self.example_input_array = torch.zeros((1, 3, 32, 32), dtype=torch.float32)
def forward(self, imgs):
# Forward function that is run when visualizing the graph
return self.model(imgs)
def configure_optimizers(self):
# We will support Adam or SGD as optimizers.
if self.hparams.optimizer_name == "Adam":
# AdamW is Adam with a correct implementation of weight decay (see here
# for details: https://arxiv.org/pdf/1711.05101.pdf)
optimizer = optim.AdamW(self.parameters(), **self.hparams.optimizer_hparams)
elif self.hparams.optimizer_name == "SGD":
optimizer = optim.SGD(self.parameters(), **self.hparams.optimizer_hparams)
else:
assert False, f'Unknown optimizer: "{self.hparams.optimizer_name}"'
# We will reduce the learning rate by 0.1 after 100 and 150 epochs
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100, 150], gamma=0.1)
return [optimizer], [scheduler]
def training_step(self, batch, batch_idx):
# "batch" is the output of the training data loader.
imgs, labels = batch
preds = self.model(imgs)
loss = self.loss_module(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
# Logs the accuracy per epoch to tensorboard (weighted average over batches)
self.log("train_acc", acc, on_step=False, on_epoch=True)
self.log("train_loss", loss)
return loss # Return tensor to call ".backward" on
def validation_step(self, batch, batch_idx):
imgs, labels = batch
preds = self.model(imgs).argmax(dim=-1)
acc = (labels == preds).float().mean()
# By default logs it per epoch (weighted average over batches)
self.log("val_acc", acc)
def test_step(self, batch, batch_idx):
imgs, labels = batch
preds = self.model(imgs).argmax(dim=-1)
acc = (labels == preds).float().mean()
# By default logs it per epoch (weighted average over batches), and returns it afterwards
self.log("test_acc", acc)
We see that the code is organized and clear, which helps if someone else tries to understand your code.
Another important part of PyTorch Lightning is the concept of callbacks. Callbacks are self-contained functions that contain the non-essential logic of your Lightning Module. They are usually called after finishing a training epoch, but can also influence other parts of your training loop. For instance, we will use the following two pre-defined callbacks: LearningRateMonitor and ModelCheckpoint. The learning rate monitor adds the current learning rate to our TensorBoard, which helps to
verify that our learning rate scheduler works correctly. The model checkpoint callback allows you to customize the saving routine of your checkpoints. For instance, how many checkpoints to keep, when to save, which metric to look out for, etc. We import them below:
[11]:
# Callbacks
To allow running multiple different models with the same Lightning module, we define a function below that maps a model name to the model class. At this stage, the dictionary model_dict is empty, but we will fill it throughout the notebook with our new models.
[12]:
model_dict = {}
def create_model(model_name, model_hparams):
if model_name in model_dict:
return model_dict[model_name](**model_hparams)
else:
assert False, f'Unknown model name "{model_name}". Available models are: {str(model_dict.keys())}'
Similarly, to use the activation function as another hyperparameter in our model, we define a “name to function” dict below:
[13]:
act_fn_by_name = {"tanh": nn.Tanh, "relu": nn.ReLU, "leakyrelu": nn.LeakyReLU, "gelu": nn.GELU}
If we pass the classes or objects directly as an argument to the Lightning module, we couldn’t take advantage of PyTorch Lightning’s automatically hyperparameter saving and loading.
Besides the Lightning module, the second most important module in PyTorch Lightning is the Trainer. The trainer is responsible to execute the training steps defined in the Lightning module and completes the framework. Similar to the Lightning module, you can override any key part that you don’t want to be automated, but the default settings are often the best practice to do. For a full overview, see the
documentation. The most important functions we use below are:
trainer.fit: Takes as input a lightning module, a training dataset, and an (optional) validation dataset. This function trains the given module on the training dataset with occasional validation (default once per epoch, can be changed)trainer.test: Takes as input a model and a dataset on which we want to test. It returns the test metric on the dataset.
For training and testing, we don’t have to worry about things like setting the model to eval mode (model.eval()) as this is all done automatically. See below how we define a training function for our models:
[14]:
def train_model(model_name, save_name=None, **kwargs):
"""
Inputs:
model_name - Name of the model you want to run. Is used to look up the class in "model_dict"
save_name (optional) - If specified, this name will be used for creating the checkpoint and logging directory.
"""
if save_name is None:
save_name = model_name
# Create a PyTorch Lightning trainer with the generation callback
trainer = pl.Trainer(
default_root_dir=os.path.join(CHECKPOINT_PATH, save_name), # Where to save models
# We run on a single GPU (if possible)
gpus=1 if str(device) == "cuda:0" else 0,
# How many epochs to train for if no patience is set
max_epochs=180,
callbacks=[
ModelCheckpoint(
save_weights_only=True, mode="max", monitor="val_acc"
), # Save the best checkpoint based on the maximum val_acc recorded. Saves only weights and not optimizer
LearningRateMonitor("epoch"),
], # Log learning rate every epoch
progress_bar_refresh_rate=1,
) # In case your notebook crashes due to the progress bar, consider increasing the refresh rate
trainer.logger._log_graph = True # If True, we plot the computation graph in tensorboard
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, save_name + ".ckpt")
if os.path.isfile(pretrained_filename):
print(f"Found pretrained model at {pretrained_filename}, loading...")
# Automatically loads the model with the saved hyperparameters
model = CIFARModule.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42) # To be reproducable
model = CIFARModule(model_name=model_name, **kwargs)
trainer.fit(model, train_loader, val_loader)
model = CIFARModule.load_from_checkpoint(
trainer.checkpoint_callback.best_model_path
) # Load best checkpoint after training
# Test best model on validation and test set
val_result = trainer.test(model, dataloaders=val_loader, verbose=False)
test_result = trainer.test(model, dataloaders=test_loader, verbose=False)
result = {"test": test_result[0]["test_acc"], "val": val_result[0]["test_acc"]}
return model, result
Finally, we can focus on the Convolutional Neural Networks we want to implement today: GoogleNet, ResNet, and DenseNet.
Inception¶
The GoogleNet, proposed in 2014, won the ImageNet Challenge because of its usage of the Inception modules. In general, we will mainly focus on the concept of Inception in this tutorial instead of the specifics of the GoogleNet, as based on Inception, there have been many follow-up works (Inception-v2, Inception-v3, Inception-v4, Inception-ResNet,…). The follow-up works mainly focus on increasing efficiency and enabling very deep Inception networks. However, for a fundamental understanding, it is sufficient to look at the original Inception block.
An Inception block applies four convolution blocks separately on the same feature map: a 1x1, 3x3, and 5x5 convolution, and a max pool operation. This allows the network to look at the same data with different receptive fields. Of course, learning only 5x5 convolution would be theoretically more powerful. However, this is not only more computation and memory heavy but also tends to overfit much easier. The overall inception block looks like below (figure credit - Szegedy et al. ):

The additional 1x1 convolutions before the 3x3 and 5x5 convolutions are used for dimensionality reduction. This is especially crucial as the feature maps of all branches are merged afterward, and we don’t want any explosion of feature size. As 5x5 convolutions are 25 times more expensive than 1x1 convolutions, we can save a lot of computation and parameters by reducing the dimensionality before the large convolutions.
We can now try to implement the Inception Block ourselves:
[15]:
class InceptionBlock(nn.Module):
def __init__(self, c_in, c_red: dict, c_out: dict, act_fn):
"""
Inputs:
c_in - Number of input feature maps from the previous layers
c_red - Dictionary with keys "3x3" and "5x5" specifying the output of the dimensionality reducing 1x1 convolutions
c_out - Dictionary with keys "1x1", "3x3", "5x5", and "max"
act_fn - Activation class constructor (e.g. nn.ReLU)
"""
super().__init__()
# 1x1 convolution branch
self.conv_1x1 = nn.Sequential(
nn.Conv2d(c_in, c_out["1x1"], kernel_size=1), nn.BatchNorm2d(c_out["1x1"]), act_fn()
)
# 3x3 convolution branch
self.conv_3x3 = nn.Sequential(
nn.Conv2d(c_in, c_red["3x3"], kernel_size=1),
nn.BatchNorm2d(c_red["3x3"]),
act_fn(),
nn.Conv2d(c_red["3x3"], c_out["3x3"], kernel_size=3, padding=1),
nn.BatchNorm2d(c_out["3x3"]),
act_fn(),
)
# 5x5 convolution branch
self.conv_5x5 = nn.Sequential(
nn.Conv2d(c_in, c_red["5x5"], kernel_size=1),
nn.BatchNorm2d(c_red["5x5"]),
act_fn(),
nn.Conv2d(c_red["5x5"], c_out["5x5"], kernel_size=5, padding=2),
nn.BatchNorm2d(c_out["5x5"]),
act_fn(),
)
# Max-pool branch
self.max_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, padding=1, stride=1),
nn.Conv2d(c_in, c_out["max"], kernel_size=1),
nn.BatchNorm2d(c_out["max"]),
act_fn(),
)
def forward(self, x):
x_1x1 = self.conv_1x1(x)
x_3x3 = self.conv_3x3(x)
x_5x5 = self.conv_5x5(x)
x_max = self.max_pool(x)
x_out = torch.cat([x_1x1, x_3x3, x_5x5, x_max], dim=1)
return x_out
The GoogleNet architecture consists of stacking multiple Inception blocks with occasional max pooling to reduce the height and width of the feature maps. The original GoogleNet was designed for image sizes of ImageNet (224x224 pixels) and had almost 7 million parameters. As we train on CIFAR10 with image sizes of 32x32, we don’t require such a heavy architecture, and instead, apply a reduced version. The number of channels for dimensionality reduction and output per filter (1x1, 3x3, 5x5, and max pooling) need to be manually specified and can be changed if interested. The general intuition is to have the most filters for the 3x3 convolutions, as they are powerful enough to take the context into account while requiring almost a third of the parameters of the 5x5 convolution.
[16]:
class GoogleNet(nn.Module):
def __init__(self, num_classes=10, act_fn_name="relu", **kwargs):
super().__init__()
self.hparams = SimpleNamespace(
num_classes=num_classes, act_fn_name=act_fn_name, act_fn=act_fn_by_name[act_fn_name]
)
self._create_network()
self._init_params()
def _create_network(self):
# A first convolution on the original image to scale up the channel size
self.input_net = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.BatchNorm2d(64), self.hparams.act_fn()
)
# Stacking inception blocks
self.inception_blocks = nn.Sequential(
InceptionBlock(
64,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 16, "3x3": 32, "5x5": 8, "max": 8},
act_fn=self.hparams.act_fn,
),
InceptionBlock(
64,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 24, "3x3": 48, "5x5": 12, "max": 12},
act_fn=self.hparams.act_fn,
),
nn.MaxPool2d(3, stride=2, padding=1), # 32x32 => 16x16
InceptionBlock(
96,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 24, "3x3": 48, "5x5": 12, "max": 12},
act_fn=self.hparams.act_fn,
),
InceptionBlock(
96,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 16, "3x3": 48, "5x5": 16, "max": 16},
act_fn=self.hparams.act_fn,
),
InceptionBlock(
96,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 16, "3x3": 48, "5x5": 16, "max": 16},
act_fn=self.hparams.act_fn,
),
InceptionBlock(
96,
c_red={"3x3": 32, "5x5": 16},
c_out={"1x1": 32, "3x3": 48, "5x5": 24, "max": 24},
act_fn=self.hparams.act_fn,
),
nn.MaxPool2d(3, stride=2, padding=1), # 16x16 => 8x8
InceptionBlock(
128,
c_red={"3x3": 48, "5x5": 16},
c_out={"1x1": 32, "3x3": 64, "5x5": 16, "max": 16},
act_fn=self.hparams.act_fn,
),
InceptionBlock(
128,
c_red={"3x3": 48, "5x5": 16},
c_out={"1x1": 32, "3x3": 64, "5x5": 16, "max": 16},
act_fn=self.hparams.act_fn,
),
)
# Mapping to classification output
self.output_net = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(), nn.Linear(128, self.hparams.num_classes)
)
def _init_params(self):
# Based on our discussion in Tutorial 4, we should initialize the
# convolutions according to the activation function
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, nonlinearity=self.hparams.act_fn_name)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.input_net(x)
x = self.inception_blocks(x)
x = self.output_net(x)
return x
Now, we can integrate our model to the model dictionary we defined above:
[17]:
model_dict["GoogleNet"] = GoogleNet
The training of the model is handled by PyTorch Lightning, and we just have to define the command to start. Note that we train for almost 200 epochs, which takes about an hour on Lisa’s default GPUs (GTX1080Ti). We would recommend using the saved models and train your own model if you are interested.
[18]:
googlenet_model, googlenet_results = train_model(
model_name="GoogleNet",
model_hparams={"num_classes": 10, "act_fn_name": "relu"},
optimizer_name="Adam",
optimizer_hparams={"lr": 1e-3, "weight_decay": 1e-4},
)
/home/AzDevOps_azpcontainer/.local/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/callback_connector.py:96: LightningDeprecationWarning: Setting `Trainer(progress_bar_refresh_rate=1)` is deprecated in v1.5 and will be removed in v1.7. Please pass `pytorch_lightning.callbacks.progress.TQDMProgressBar` with `refresh_rate` directly to the Trainer's `callbacks` argument instead. Or, to disable the progress bar pass `enable_progress_bar = False` to the Trainer.
rank_zero_deprecation(
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: saved_models/ConvNets/GoogleNet/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Found pretrained model at saved_models/ConvNets/GoogleNet.ckpt, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
We will compare the results later in the notebooks, but we can already print them here for a first glance:
[19]:
print("GoogleNet Results", googlenet_results)
GoogleNet Results {'test': 0.8970000147819519, 'val': 0.9039999842643738}
Tensorboard log¶
A nice extra of PyTorch Lightning is the automatic logging into TensorBoard. To give you a better intuition of what TensorBoard can be used, we can look at the board that PyTorch Lightning has been generated when training the GoogleNet. TensorBoard provides an inline functionality for Jupyter notebooks, and we use it here:
[20]:
# Import tensorboard
%load_ext tensorboard
[21]:
# Opens tensorboard in notebook. Adjust the path to your CHECKPOINT_PATH!
%tensorboard --logdir ../saved_models/tutorial5/tensorboards/GoogleNet/

TensorBoard is organized in multiple tabs. The main tab is the scalar tab where we can log the development of single numbers. For example, we have plotted the training loss, accuracy, learning rate, etc. If we look at the training or validation accuracy, we can really see the impact of using a learning rate scheduler. Reducing the learning rate gives our model a nice increase in training performance. Similarly, when looking at the training loss, we see a sudden decrease at this point. However, the high numbers on the training set compared to validation indicate that our model was overfitting which is inevitable for such large networks.
Another interesting tab in TensorBoard is the graph tab. It shows us the network architecture organized by building blocks from the input to the output. It basically shows the operations taken in the forward step of CIFARModule. Double-click on a module to open it. Feel free to explore the architecture from a different perspective. The graph visualization can often help you to validate that your model is actually doing what it is supposed to do, and you don’t miss any layers in the
computation graph.
ResNet¶
The ResNet paper is one of the most cited AI papers, and has been the foundation for neural networks with more than 1,000 layers. Despite its simplicity, the idea of residual connections is highly effective as it supports stable gradient propagation through the network. Instead of modeling 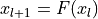 , we model
, we model
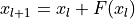 where
where 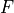 is a non-linear mapping (usually a sequence of NN modules likes convolutions, activation functions, and normalizations). If we do backpropagation on such residual connections, we obtain:
is a non-linear mapping (usually a sequence of NN modules likes convolutions, activation functions, and normalizations). If we do backpropagation on such residual connections, we obtain:
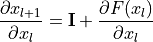
The bias towards the identity matrix guarantees a stable gradient propagation being less effected by itself. There have been many variants of ResNet proposed, which mostly concern the function , or operations applied on the sum. In this tutorial, we look at two of them: the original ResNet block, and the Pre-Activation ResNet block. We visually compare the blocks below (figure credit - He et al. ):

The original ResNet block applies a non-linear activation function, usually ReLU, after the skip connection. In contrast, the pre-activation ResNet block applies the non-linearity at the beginning of . Both have their advantages and disadvantages. For very deep network, however, the pre-activation ResNet has shown to perform better as the gradient flow is guaranteed to have the identity matrix as calculated above, and is not harmed by any non-linear activation applied to it. For
comparison, in this notebook, we implement both ResNet types as shallow networks.
Let’s start with the original ResNet block. The visualization above already shows what layers are included in . One special case we have to handle is when we want to reduce the image dimensions in terms of width and height. The basic ResNet block requires 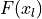 to be of the same shape as
to be of the same shape as 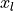 . Thus, we need to change the dimensionality of as well before adding to . The original implementation used an identity mapping with stride 2 and
padded additional feature dimensions with 0. However, the more common implementation is to use a 1x1 convolution with stride 2 as it allows us to change the feature dimensionality while being efficient in parameter and computation cost. The code for the ResNet block is relatively simple, and shown below:
. Thus, we need to change the dimensionality of as well before adding to . The original implementation used an identity mapping with stride 2 and
padded additional feature dimensions with 0. However, the more common implementation is to use a 1x1 convolution with stride 2 as it allows us to change the feature dimensionality while being efficient in parameter and computation cost. The code for the ResNet block is relatively simple, and shown below:
[22]:
class ResNetBlock(nn.Module):
def __init__(self, c_in, act_fn, subsample=False, c_out=-1):
"""
Inputs:
c_in - Number of input features
act_fn - Activation class constructor (e.g. nn.ReLU)
subsample - If True, we want to apply a stride inside the block and reduce the output shape by 2 in height and width
c_out - Number of output features. Note that this is only relevant if subsample is True, as otherwise, c_out = c_in
"""
super().__init__()
if not subsample:
c_out = c_in
# Network representing F
self.net = nn.Sequential(
nn.Conv2d(
c_in, c_out, kernel_size=3, padding=1, stride=1 if not subsample else 2, bias=False
), # No bias needed as the Batch Norm handles it
nn.BatchNorm2d(c_out),
act_fn(),
nn.Conv2d(c_out, c_out, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(c_out),
)
# 1x1 convolution with stride 2 means we take the upper left value, and transform it to new output size
self.downsample = nn.Conv2d(c_in, c_out, kernel_size=1, stride=2) if subsample else None
self.act_fn = act_fn()
def forward(self, x):
z = self.net(x)
if self.downsample is not None:
x = self.downsample(x)
out = z + x
out = self.act_fn(out)
return out
The second block we implement is the pre-activation ResNet block. For this, we have to change the order of layer in self.net, and do not apply an activation function on the output. Additionally, the downsampling operation has to apply a non-linearity as well as the input, 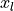 , has not been processed by a non-linearity yet. Hence, the block looks as follows:
, has not been processed by a non-linearity yet. Hence, the block looks as follows:
[23]:
class PreActResNetBlock(nn.Module):
def __init__(self, c_in, act_fn, subsample=False, c_out=-1):
"""
Inputs:
c_in - Number of input features
act_fn - Activation class constructor (e.g. nn.ReLU)
subsample - If True, we want to apply a stride inside the block and reduce the output shape by 2 in height and width
c_out - Number of output features. Note that this is only relevant if subsample is True, as otherwise, c_out = c_in
"""
super().__init__()
if not subsample:
c_out = c_in
# Network representing F
self.net = nn.Sequential(
nn.BatchNorm2d(c_in),
act_fn(),
nn.Conv2d(c_in, c_out, kernel_size=3, padding=1, stride=1 if not subsample else 2, bias=False),
nn.BatchNorm2d(c_out),
act_fn(),
nn.Conv2d(c_out, c_out, kernel_size=3, padding=1, bias=False),
)
# 1x1 convolution needs to apply non-linearity as well as not done on skip connection
self.downsample = (
nn.Sequential(nn.BatchNorm2d(c_in), act_fn(), nn.Conv2d(c_in, c_out, kernel_size=1, stride=2, bias=False))
if subsample
else None
)
def forward(self, x):
z = self.net(x)
if self.downsample is not None:
x = self.downsample(x)
out = z + x
return out
Similarly to the model selection, we define a dictionary to create a mapping from string to block class. We will use the string name as hyperparameter value in our model to choose between the ResNet blocks. Feel free to implement any other ResNet block type and add it here as well.
[24]:
resnet_blocks_by_name = {"ResNetBlock": ResNetBlock, "PreActResNetBlock": PreActResNetBlock}
The overall ResNet architecture consists of stacking multiple ResNet blocks, of which some are downsampling the input. When talking about ResNet blocks in the whole network, we usually group them by the same output shape. Hence, if we say the ResNet has [3,3,3] blocks, it means that we have 3 times a group of 3 ResNet blocks, where a subsampling is taking place in the fourth and seventh block. The ResNet with [3,3,3] blocks on CIFAR10 is visualized below.

The three groups operate on the resolutions 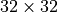 ,
, 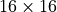 and
and 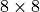 respectively. The blocks in orange denote ResNet blocks with downsampling. The same notation is used by many other implementations such as in the torchvision library from PyTorch. Thus, our code looks as follows:
respectively. The blocks in orange denote ResNet blocks with downsampling. The same notation is used by many other implementations such as in the torchvision library from PyTorch. Thus, our code looks as follows:
[25]:
class ResNet(nn.Module):
def __init__(
self,
num_classes=10,
num_blocks=[3, 3, 3],
c_hidden=[16, 32, 64],
act_fn_name="relu",
block_name="ResNetBlock",
**kwargs,
):
"""
Inputs:
num_classes - Number of classification outputs (10 for CIFAR10)
num_blocks - List with the number of ResNet blocks to use. The first block of each group uses downsampling, except the first.
c_hidden - List with the hidden dimensionalities in the different blocks. Usually multiplied by 2 the deeper we go.
act_fn_name - Name of the activation function to use, looked up in "act_fn_by_name"
block_name - Name of the ResNet block, looked up in "resnet_blocks_by_name"
"""
super().__init__()
assert block_name in resnet_blocks_by_name
self.hparams = SimpleNamespace(
num_classes=num_classes,
c_hidden=c_hidden,
num_blocks=num_blocks,
act_fn_name=act_fn_name,
act_fn=act_fn_by_name[act_fn_name],
block_class=resnet_blocks_by_name[block_name],
)
self._create_network()
self._init_params()
def _create_network(self):
c_hidden = self.hparams.c_hidden
# A first convolution on the original image to scale up the channel size
if self.hparams.block_class == PreActResNetBlock: # => Don't apply non-linearity on output
self.input_net = nn.Sequential(nn.Conv2d(3, c_hidden[0], kernel_size=3, padding=1, bias=False))
else:
self.input_net = nn.Sequential(
nn.Conv2d(3, c_hidden[0], kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(c_hidden[0]),
self.hparams.act_fn(),
)
# Creating the ResNet blocks
blocks = []
for block_idx, block_count in enumerate(self.hparams.num_blocks):
for bc in range(block_count):
# Subsample the first block of each group, except the very first one.
subsample = bc == 0 and block_idx > 0
blocks.append(
self.hparams.block_class(
c_in=c_hidden[block_idx if not subsample else (block_idx - 1)],
act_fn=self.hparams.act_fn,
subsample=subsample,
c_out=c_hidden[block_idx],
)
)
self.blocks = nn.Sequential(*blocks)
# Mapping to classification output
self.output_net = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(), nn.Linear(c_hidden[-1], self.hparams.num_classes)
)
def _init_params(self):
# Based on our discussion in Tutorial 4, we should initialize the convolutions according to the activation function
# Fan-out focuses on the gradient distribution, and is commonly used in ResNets
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity=self.hparams.act_fn_name)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.input_net(x)
x = self.blocks(x)
x = self.output_net(x)
return x
We also need to add the new ResNet class to our model dictionary:
[26]:
model_dict["ResNet"] = ResNet
Finally, we can train our ResNet models. One difference to the GoogleNet training is that we explicitly use SGD with Momentum as optimizer instead of Adam. Adam often leads to a slightly worse accuracy on plain, shallow ResNets. It is not 100% clear why Adam performs worse in this context, but one possible explanation is related to ResNet’s loss surface. ResNet has been shown to produce smoother loss surfaces than networks without skip connection (see Li et al., 2018 for details). A possible visualization of the loss surface with/out skip connections is below (figure credit - Li et al. ):

The 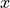 and
and 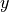 axis shows a projection of the parameter space, and the
axis shows a projection of the parameter space, and the  axis shows the loss values achieved by different parameter values. On smooth surfaces like the one on the right, we might not require an adaptive learning rate as Adam provides. Instead, Adam can get stuck in local optima while SGD finds the wider minima that tend to generalize better. However, to answer this question in detail, we would need an extra tutorial because it is not easy to answer. For now,
we conclude: for ResNet architectures, consider the optimizer to be an important hyperparameter, and try training with both Adam and SGD. Let’s train the model below with SGD:
axis shows the loss values achieved by different parameter values. On smooth surfaces like the one on the right, we might not require an adaptive learning rate as Adam provides. Instead, Adam can get stuck in local optima while SGD finds the wider minima that tend to generalize better. However, to answer this question in detail, we would need an extra tutorial because it is not easy to answer. For now,
we conclude: for ResNet architectures, consider the optimizer to be an important hyperparameter, and try training with both Adam and SGD. Let’s train the model below with SGD:
[27]:
resnet_model, resnet_results = train_model(
model_name="ResNet",
model_hparams={"num_classes": 10, "c_hidden": [16, 32, 64], "num_blocks": [3, 3, 3], "act_fn_name": "relu"},
optimizer_name="SGD",
optimizer_hparams={"lr": 0.1, "momentum": 0.9, "weight_decay": 1e-4},
)
/home/AzDevOps_azpcontainer/.local/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/callback_connector.py:96: LightningDeprecationWarning: Setting `Trainer(progress_bar_refresh_rate=1)` is deprecated in v1.5 and will be removed in v1.7. Please pass `pytorch_lightning.callbacks.progress.TQDMProgressBar` with `refresh_rate` directly to the Trainer's `callbacks` argument instead. Or, to disable the progress bar pass `enable_progress_bar = False` to the Trainer.
rank_zero_deprecation(
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: saved_models/ConvNets/ResNet/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Found pretrained model at saved_models/ConvNets/ResNet.ckpt, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Let’s also train the pre-activation ResNet as comparison:
[28]:
resnetpreact_model, resnetpreact_results = train_model(
model_name="ResNet",
model_hparams={
"num_classes": 10,
"c_hidden": [16, 32, 64],
"num_blocks": [3, 3, 3],
"act_fn_name": "relu",
"block_name": "PreActResNetBlock",
},
optimizer_name="SGD",
optimizer_hparams={"lr": 0.1, "momentum": 0.9, "weight_decay": 1e-4},
save_name="ResNetPreAct",
)
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: saved_models/ConvNets/ResNetPreAct/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Found pretrained model at saved_models/ConvNets/ResNetPreAct.ckpt, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Tensorboard log¶
Similarly to our GoogleNet model, we also have a TensorBoard log for the ResNet model. We can open it below.
[29]:
# Opens tensorboard in notebook. Adjust the path to your CHECKPOINT_PATH! Feel free to change "ResNet" to "ResNetPreAct"
%tensorboard --logdir ../saved_models/tutorial5/tensorboards/ResNet/

Feel free to explore the TensorBoard yourself, including the computation graph. In general, we can see that with SGD, the ResNet has a higher training loss than the GoogleNet in the first stage of the training. After reducing the learning rate however, the model achieves even higher validation accuracies. We compare the precise scores at the end of the notebook.
DenseNet¶
DenseNet is another architecture for enabling very deep neural networks and takes a slightly different perspective on residual connections. Instead of modeling the difference between layers, DenseNet considers residual connections as a possible way to reuse features across layers, removing any necessity to learn redundant feature maps. If we go deeper into the network, the model learns abstract features to recognize patterns. However, some complex patterns consist of a combination of abstract features (e.g. hand, face, etc. ), and low-level features (e.g. edges, basic color, etc.). To find these low-level features in the deep layers, standard CNNs have to learn copy such feature maps, which wastes a lot of parameter complexity. DenseNet provides an efficient way of reusing features by having each convolution depends on all previous input features, but add only a small amount of filters to it. See the figure below for an illustration (figure credit - Hu et al. ):

The last layer, called the transition layer, is responsible for reducing the dimensionality of the feature maps in height, width, and channel size. Although those technically break the identity backpropagation, there are only a few in a network so that it doesn’t affect the gradient flow much.
We split the implementation of the layers in DenseNet into three parts: a DenseLayer, and a DenseBlock, and a TransitionLayer. The module DenseLayer implements a single layer inside a dense block. It applies a 1x1 convolution for dimensionality reduction with a subsequential 3x3 convolution. The output channels are concatenated to the originals and returned. Note that we apply the Batch Normalization as the first layer of each block. This allows slightly different activations for
the same features to different layers, depending on what is needed. Overall, we can implement it as follows:
[30]:
class DenseLayer(nn.Module):
def __init__(self, c_in, bn_size, growth_rate, act_fn):
"""
Inputs:
c_in - Number of input channels
bn_size - Bottleneck size (factor of growth rate) for the output of the 1x1 convolution. Typically between 2 and 4.
growth_rate - Number of output channels of the 3x3 convolution
act_fn - Activation class constructor (e.g. nn.ReLU)
"""
super().__init__()
self.net = nn.Sequential(
nn.BatchNorm2d(c_in),
act_fn(),
nn.Conv2d(c_in, bn_size * growth_rate, kernel_size=1, bias=False),
nn.BatchNorm2d(bn_size * growth_rate),
act_fn(),
nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, padding=1, bias=False),
)
def forward(self, x):
out = self.net(x)
out = torch.cat([out, x], dim=1)
return out
The module DenseBlock summarizes multiple dense layers applied in sequence. Each dense layer takes as input the original input concatenated with all previous layers’ feature maps:
[31]:
class DenseBlock(nn.Module):
def __init__(self, c_in, num_layers, bn_size, growth_rate, act_fn):
"""
Inputs:
c_in - Number of input channels
num_layers - Number of dense layers to apply in the block
bn_size - Bottleneck size to use in the dense layers
growth_rate - Growth rate to use in the dense layers
act_fn - Activation function to use in the dense layers
"""
super().__init__()
layers = []
for layer_idx in range(num_layers):
# Input channels are original plus the feature maps from previous layers
layer_c_in = c_in + layer_idx * growth_rate
layers.append(DenseLayer(c_in=layer_c_in, bn_size=bn_size, growth_rate=growth_rate, act_fn=act_fn))
self.block = nn.Sequential(*layers)
def forward(self, x):
out = self.block(x)
return out
Finally, the TransitionLayer takes as input the final output of a dense block and reduces its channel dimensionality using a 1x1 convolution. To reduce the height and width dimension, we take a slightly different approach than in ResNet and apply an average pooling with kernel size 2 and stride 2. This is because we don’t have an additional connection to the output that would consider the full 2x2 patch instead of a single value. Besides, it is more parameter efficient than using a 3x3
convolution with stride 2. Thus, the layer is implemented as follows:
[32]:
class TransitionLayer(nn.Module):
def __init__(self, c_in, c_out, act_fn):
super().__init__()
self.transition = nn.Sequential(
nn.BatchNorm2d(c_in),
act_fn(),
nn.Conv2d(c_in, c_out, kernel_size=1, bias=False),
nn.AvgPool2d(kernel_size=2, stride=2), # Average the output for each 2x2 pixel group
)
def forward(self, x):
return self.transition(x)
Now we can put everything together and create our DenseNet. To specify the number of layers, we use a similar notation as in ResNets and pass on a list of ints representing the number of layers per block. After each dense block except the last one, we apply a transition layer to reduce the dimensionality by 2.
[33]:
class DenseNet(nn.Module):
def __init__(
self, num_classes=10, num_layers=[6, 6, 6, 6], bn_size=2, growth_rate=16, act_fn_name="relu", **kwargs
):
super().__init__()
self.hparams = SimpleNamespace(
num_classes=num_classes,
num_layers=num_layers,
bn_size=bn_size,
growth_rate=growth_rate,
act_fn_name=act_fn_name,
act_fn=act_fn_by_name[act_fn_name],
)
self._create_network()
self._init_params()
def _create_network(self):
c_hidden = self.hparams.growth_rate * self.hparams.bn_size # The start number of hidden channels
# A first convolution on the original image to scale up the channel size
self.input_net = nn.Sequential(
# No batch norm or activation function as done inside the Dense layers
nn.Conv2d(3, c_hidden, kernel_size=3, padding=1)
)
# Creating the dense blocks, eventually including transition layers
blocks = []
for block_idx, num_layers in enumerate(self.hparams.num_layers):
blocks.append(
DenseBlock(
c_in=c_hidden,
num_layers=num_layers,
bn_size=self.hparams.bn_size,
growth_rate=self.hparams.growth_rate,
act_fn=self.hparams.act_fn,
)
)
c_hidden = c_hidden + num_layers * self.hparams.growth_rate # Overall output of the dense block
if block_idx < len(self.hparams.num_layers) - 1: # Don't apply transition layer on last block
blocks.append(TransitionLayer(c_in=c_hidden, c_out=c_hidden // 2, act_fn=self.hparams.act_fn))
c_hidden = c_hidden // 2
self.blocks = nn.Sequential(*blocks)
# Mapping to classification output
self.output_net = nn.Sequential(
nn.BatchNorm2d(c_hidden), # The features have not passed a non-linearity until here.
self.hparams.act_fn(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(c_hidden, self.hparams.num_classes),
)
def _init_params(self):
# Based on our discussion in Tutorial 4, we should initialize the
# convolutions according to the activation function
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, nonlinearity=self.hparams.act_fn_name)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.input_net(x)
x = self.blocks(x)
x = self.output_net(x)
return x
Let’s also add the DenseNet to our model dictionary:
[34]:
model_dict["DenseNet"] = DenseNet
Lastly, we train our network. In contrast to ResNet, DenseNet does not show any issues with Adam, and hence we train it with this optimizer. The other hyperparameters are chosen to result in a network with a similar parameter size as the ResNet and GoogleNet. Commonly, when designing very deep networks, DenseNet is more parameter efficient than ResNet while achieving a similar or even better performance.
[35]:
densenet_model, densenet_results = train_model(
model_name="DenseNet",
model_hparams={
"num_classes": 10,
"num_layers": [6, 6, 6, 6],
"bn_size": 2,
"growth_rate": 16,
"act_fn_name": "relu",
},
optimizer_name="Adam",
optimizer_hparams={"lr": 1e-3, "weight_decay": 1e-4},
)
/home/AzDevOps_azpcontainer/.local/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/callback_connector.py:96: LightningDeprecationWarning: Setting `Trainer(progress_bar_refresh_rate=1)` is deprecated in v1.5 and will be removed in v1.7. Please pass `pytorch_lightning.callbacks.progress.TQDMProgressBar` with `refresh_rate` directly to the Trainer's `callbacks` argument instead. Or, to disable the progress bar pass `enable_progress_bar = False` to the Trainer.
rank_zero_deprecation(
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: saved_models/ConvNets/DenseNet/lightning_logs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Found pretrained model at saved_models/ConvNets/DenseNet.ckpt, loading...
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1]
Tensorboard log¶
Finally, we also have another TensorBoard for the DenseNet training. We take a look at it below:
[36]:
# Opens tensorboard in notebook. Adjust the path to your CHECKPOINT_PATH! Feel free to change "ResNet" to "ResNetPreAct"
%tensorboard --logdir ../saved_models/tutorial5/tensorboards/DenseNet/

The overall course of the validation accuracy and training loss resemble the training of GoogleNet, which is also related to training the network with Adam. Feel free to explore the training metrics yourself.
Conclusion and Comparison¶
After discussing each model separately, and training all of them, we can finally compare them. First, let’s organize the results of all models in a table:
[37]:
%%html
<!-- Some HTML code to increase font size in the following table -->
<style>
th {font-size: 120%;}
td {font-size: 120%;}
</style>
[38]:
all_models = [
("GoogleNet", googlenet_results, googlenet_model),
("ResNet", resnet_results, resnet_model),
("ResNetPreAct", resnetpreact_results, resnetpreact_model),
("DenseNet", densenet_results, densenet_model),
]
table = [
[
model_name,
f"{100.0*model_results['val']:4.2f}%",
f"{100.0*model_results['test']:4.2f}%",
f"{sum(np.prod(p.shape) for p in model.parameters()):,}",
]
for model_name, model_results, model in all_models
]
display(
HTML(
tabulate.tabulate(table, tablefmt="html", headers=["Model", "Val Accuracy", "Test Accuracy", "Num Parameters"])
)
)
| Model | Val Accuracy | Test Accuracy | Num Parameters |
|---|---|---|---|
| GoogleNet | 90.40% | 89.70% | 260,650 |
| ResNet | 91.84% | 91.06% | 272,378 |
| ResNetPreAct | 91.80% | 91.07% | 272,250 |
| DenseNet | 90.72% | 90.23% | 239,146 |
First of all, we see that all models are performing reasonably well. Simple models as you have implemented them in the practical achieve considerably lower performance, which is beside the lower number of parameters also attributed to the architecture design choice. GoogleNet is the model to obtain the lowest performance on the validation and test set, although it is very close to DenseNet. A proper hyperparameter search over all the channel sizes in GoogleNet would likely improve the accuracy of the model to a similar level, but this is also expensive given a large number of hyperparameters. ResNet outperforms both DenseNet and GoogleNet by more than 1% on the validation set, while there is a minor difference between both versions, original and pre-activation. We can conclude that for shallow networks, the place of the activation function does not seem to be crucial, although papers have reported the contrary for very deep networks (e.g. He et al. ).
In general, we can conclude that ResNet is a simple, but powerful architecture. If we would apply the models on more complex tasks with larger images and more layers inside the networks, we would likely see a bigger gap between GoogleNet and skip-connection architectures like ResNet and DenseNet. A comparison with deeper models on CIFAR10 can be for example found here. Interestingly, DenseNet outperforms the original ResNet on their setup but comes closely behind the Pre-Activation ResNet. The best model, a Dual Path Network (Chen et. al), is actually a combination of ResNet and DenseNet showing that both offer different advantages.
Which model should I choose for my task?¶
We have reviewed four different models. So, which one should we choose if have given a new task? Usually, starting with a ResNet is a good idea given the superior performance of the CIFAR dataset and its simple implementation. Besides, for the parameter number we have chosen here, ResNet is the fastest as DenseNet and GoogleNet have many more layers that are applied in sequence in our primitive implementation. However, if you have a really difficult task, such as semantic segmentation on HD images, more complex variants of ResNet and DenseNet are recommended.
Congratulations - Time to Join the Community!¶
Congratulations on completing this notebook tutorial! If you enjoyed this and would like to join the Lightning movement, you can do so in the following ways!
Star Lightning on GitHub¶
The easiest way to help our community is just by starring the GitHub repos! This helps raise awareness of the cool tools we’re building.
Join our Slack!¶
The best way to keep up to date on the latest advancements is to join our community! Make sure to introduce yourself and share your interests in #general channel
Contributions !¶
The best way to contribute to our community is to become a code contributor! At any time you can go to Lightning or Bolt GitHub Issues page and filter for “good first issue”.
You can also contribute your own notebooks with useful examples !
Great thanks from the entire Pytorch Lightning Team for your interest !¶

