1. Machine learning is a subfield of ... (Check all terms that apply.)
2. Generating new data can be considered as a subcategory of ...
3. Typically, we shuffle the dataset before we divide it into training and test set to make sure that the
4. Using gradient descent to update the weight w1, which of the following values do we need to compute and/or are part of the computation? (Check all that apply)
5. Comparing the perceptron learning algorithm with gradient descent, which of the following answers is/are correct?
6. Suppose you initialize a neural network layer using torch.nn.Linear(in_features=5, out_features=1). How many trainable parameters does this layer have?
7. Suppose we implement a logistic regression model as a binary classifier for a dataset with 4 features using a linear layer self.linear = torch.nn.Linear(a, b). What are the numeric values for a and b in this case?
8. For each training example, the softmax function returns one probability membership score for each class. Which of the following statements about the sum of these scores (for one training example) is correct?
9. Suppose you have 2 training examples in a 3-class classification setting. What is the cross-entropy loss for a perfectly random prediction?
10. Which of the following is crucial for producing nonlinear decision boundaries?
11. Suppose we implemented the following multilayer perceptron architecture for a 2-dimensional dataset with 3 classes:
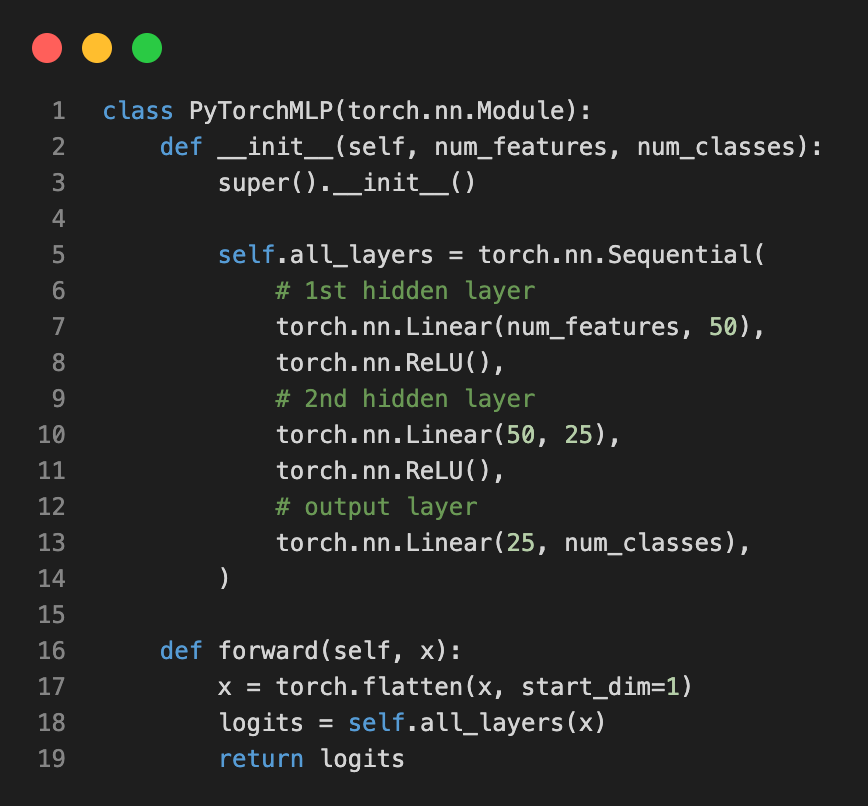
How many parameters does this neural network approximately have?
12. Before we are moving on to using the LightningModule and Trainer, suppose you want to implement a PyTorch training loop for comparison. Can you put the following code into the right order?
(1) loss.backward()
(2) logits = model(features)
(3) optimizer.zero_grad()
(4) optimizer.step()
(5) loss = F.cross_entropy(logits, labels)
13. Suppose we have a binary classification dataset with 731 data points from class 0 and 269 data points from class 1. What is the expected classification accuracy if our classifier makes totally random predictions?
14. A drop probability of 0.5 in a dropout layer means that we are dropping 50% of the
15. Suppose we have a 3x3 filter that we slide over an 12x12 dimensional image (with one input and one output channel), how many weight parameters do we need for that kernel (/filter)?
16. What is the primary purpose of skip connections in a deep neural network?
17. Which of the following is NOT a common data augmentation technique for image data?
18. Transfer learning typically involves:
19. The attention mechanism for RNNs was introduced to address which limitation of the original sequence-to-sequence models?
20. If we have an input text with 3 words, how many outputs vectors does the attention mechanism yield?
21. If we have a multi-head attention layer with 8 heads, how many weight matrices does this include?
22. How is BERT pretrained?
23. Which of the following are valid finetuning approaches?
24. On a GPU with tensor cores that support the bfloat16 type, neural networks with bfloat16 weights train ...
25. In which type of parallelism is each layer of the model computed across all GPUs, but each GPU only computes a subset of the neurons in each layer?
